Andrej Karpathy just explained the future of software engineering without directly saying it.
The best AI engineers are no longer “prompting.”
They’re building systems around the agents.
Karpathy’s biggest insight wasn’t:
“Claude can code.”
It was:
LLMs become dramatically better when you force them into disciplined workflows.
That’s why "CLAUDE.md" files are suddenly everywhere.
Not because they’re prompts.
Because they behave like an operating system for the agent.
Karpathy called out the exact problems with AI coding:
- models assume instead of asking
- they overengineer simple tasks
- they hide confusion
- they rewrite unrelated code
- they optimize for completion, not correctness
So developers started encoding rules directly into the workflow:
→ Think before coding
→ Simplicity first
→ Surgical edits only
→ Goal-driven execution
And the results are wild.
People are now running multiple Claude Code agents in parallel like engineering teams:
• one agent researching
• one debugging
• one writing tests
• one optimizing code
• one validating outputs
Not “AI assistance.”
Actual orchestration.
And this part from Karpathy changes everything:
“Don’t tell the model what to do. Give it success criteria and let it loop.”
That is the shift.
From:
“write this function”
To:
“here’s the goal, constraints, tests, and verification system — now iterate until correct.”
The craziest part?
This already feels like a phase shift in engineering.
A lot of developers quietly went from:
80% manual coding → to 80% agent-driven coding in just months.
Not because AI became perfect.
Because the leverage became impossible to ignore.
We’re entering an era where the highest leverage engineers won’t necessarily be the best coders.
They’ll be the people who build the best systems around AI agents.
Anthropic engineer:
"You're not supposed to prompt Claude. You're supposed to build a system that prompts itself."
this is one of the best workflows I've seen in a long time
in this video she breaks down exactly how most people are using Claude:
- the 14% you lose to CLAUDE.md before typing a word
- the plugins that 95% of users have never installed
- the workflows that run without you typing a single prompt
- why typing one prompt and closing the tab is leaving 90% on the table
if you've been using Claude for months and still start every session from scratch, you have at least 28 untouched features. probably 30
instead of another show tonight, watch this
make sure to bookmark it before it gets lost in your feed
full guide in the article below
People think learning Claude takes days. It doesn't.
I wrote 17 free guides that teach it in hours:
Claude 101: https://t.co/QQDmzBAoH5
Claude Code: https://t.co/o782qegoKu
Claude Skills: https://t.co/RgQUCNMqzQ
Claude Connectors: https://t.co/cSPMBUNmRG
Claude for Excel: https://t.co/ZgmUFXd0Iw
How to Prompt: https://t.co/Sw2tg2PMMc
Claude Certificates: https://t.co/LyV7fegv4c
Claude for your team: https://t.co/NakViTGCAL
Stop Prompting Claude: https://t.co/45xPLDRB6Y
AI Slides (PPT in 2026): https://t.co/OY7cHDTV7l
Claude Design: https://t.co/FhlRSlH0aD
Set up Claude Cowork: https://t.co/4jygw4M1RO
Claude to sound like you: https://t.co/LyV7fegv4c
Stop writing like AI: https://t.co/JXKAVP6hdS
Claude as your computer: https://t.co/tQDrcs8drQ
Claude Cowork + Project: https://t.co/xU97EpdrEe
Stop hitting Claude limits: https://t.co/Yu24rPQafQ
___
1. Save this list for later (three dots, top right).
2. Share it with a friend by ♻️ reposting this image.
3. Subscribe to my free newsletter: https://t.co/psB7XxAv8w.
Claude opus 4.8 dropped and Anthropic released Boris Cherny's prompt workshop
One of the people actually building claude explains how to use it properly
Free
No signup
No paywall
The first 8 minutes are better than most $300 ai courses
Context
Task structure
Cleaner outputs
Fewer wasted prompts
Watch it and bookmark it before this gets sold back to you as a course
MARC ANDREESSEN JUST WENT ON ROGAN AND DROPPED THE MOST IMPORTANT AI ALPHA OF THE YEAR.
3 hours and 20 minutes of podcast.
Here are the 17 things worth your attention.
1. AGI is already here. Marc thinks the line was crossed 3 months ago with GPT-5.5, Claude 4.6, Gemini 3, and Grok 4.3. Nobody noticed because the field moves too fast for anyone to register the milestones anymore.
2. For almost any topic the top AI models now give him better answers than the world-class experts he could call on the phone. And he can call basically anyone.
3. Every doctor is secretly using ChatGPT in the exam room. They turn around the second you stop talking and type your symptoms in. Some do it while you are still sitting there. His quote: "At that point you are asking what do I need you for."
4. When AI refuses to answer something he wants to know he tells it he is writing a novel. "Walk me through how the bad guy robs the bank." It explains almost anything if it thinks it is helping you write fiction.
5. When something is too complex he says "explain it like I am 10." Then "like I am 5." Then "like I am 2." He keeps going until it actually clicks.
6. When he wants to understand a tough topic he does not ask what the right answer is. He asks the AI to steelman one side then steelman the other. Then he decides for himself.
7. For big questions he tells the AI to pretend to be a panel of experts. "Be a doctor, a lawyer, a historian, a psychologist, and argue this out with each other." Then he reads the debate.
8. Pay attention to the exact moment you think "I do not know how to figure this out." Most people give up there. That is the moment you should open the AI.
9. The only real skill left in using AI is knowing what to ask. The models can do almost anything you can describe in plain English. The bottleneck lives in your own head.
10. You can send AI photos of almost anything medical now and get a real answer. Skin rashes. Blood test results. The new models read images not just text. A free 24/7 second opinion on anything.
11. The one type of therapy clinically proven to work is cognitive behavioral therapy. It is also something an AI can fully do on its own. Every person on earth is about to have access to a real therapist for free anytime they want.
12. AI is solving math problems open for 100 years that no human mathematician could crack. Same thing is starting in physics, chemistry, and biology. Expect cancer cures and weird new physics breakthroughs in the next few years.
13. The best AI coders in Silicon Valley now make $50 million a year. One person. That number tells you how big this thing actually is when you strip away all the doom takes.
14. One friend paid $200 to decode his entire DNA. Then gave the AI his DNA, blood test results, and Apple Watch data. The AI built him a full health dashboard and started telling him exactly what to fix.
15. Another friend put two cameras in his home jiu jitsu gym. AI watches him spar and gives him technique notes after every round. A world-class coach at every practice for free.
16. The best programmers in Silicon Valley now run 20 AI coding bots simultaneously. Each bot writes code while they review the others. They call themselves AI vampires because going to bed means 20 workers stop and you lose money every hour you sleep.
17. The obvious next step: the bots will run their own bots. One human running 20 bots each running 20 more. One person. One laptop. 1,000 AI workers. This is months away not years.
Bookmark this before you watch the full podcast.
Follow @cyrilXBT for every AI insight worth your attention the moment it surfaces.
Andrej Karpathy spent 4 minutes in an interview explaining a single idea
about how most people haven’t even started learning how to use AI
and everyone paying $20/month for a subscription.. that's not really using Claude at all
his point is that the real skill gap is the ability to build with AI
he identified 4 behaviors that break Claude Code and put them all into one file
a developer expanded it into 21 rules and published it - 82,000 stars and #1 on GitHub Trending
coding accuracy jumped from 65% to 94%
here's what these 21 rules actually are and why most developers using Claude every day have never configured them
the full breakdown is covered in the article below 👇
I have spent my entire life working on this and thinking about this for the past 4 years. I don't know what will happen in 20 years, but I can promise you that on the 5-10 year timescale, scientists are not out of their jobs. AI is going to massively accelerate the pace of science, increase productivity, let individual scientists make way more discoveries way faster, and is going to make science overall more fun. But the model is going to be collaboration between humans and AI, not replacement.
The key difference here between science and e.g. software engineering is that science is not verifiable in any rapid/convenient way (unlike software), unlike programming. We still need humans for their scientific taste.
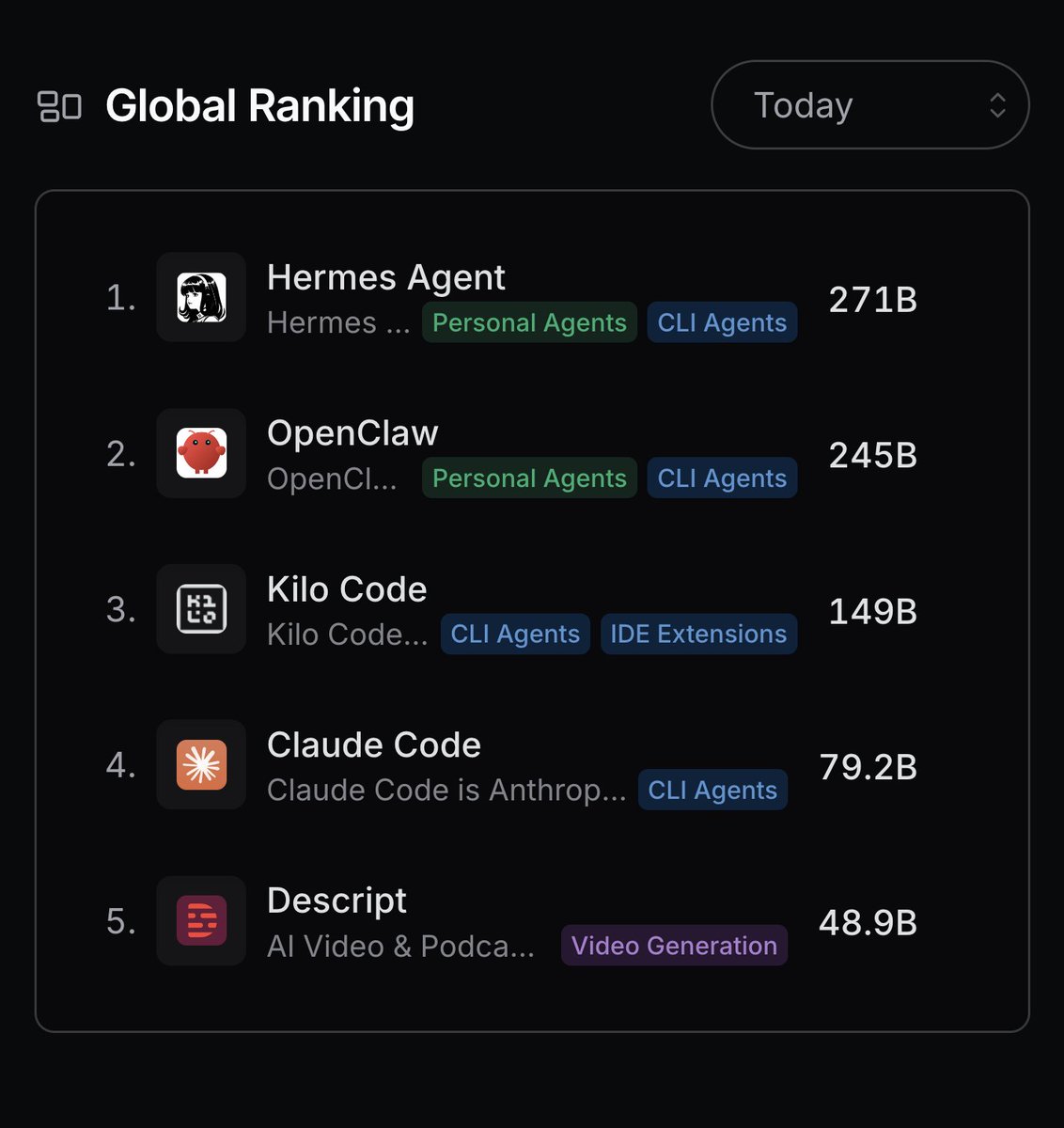
Hermes Agent is now #1 on the Global @OpenRouter token rankings.
While our journey together has just begun, we'd like to take this opportunity to thank our contributors, supporters, and users for all they have done to get us this far.
i deleted half my Claude setup last week and every output got BETTER
sounds backwards, but anthropic's own team just explained exactly why it works.
here's the one prompt that tells you what to cut (and you don't even have to paste anything):
this is what happens to everyone...
you get a bad output, so you add a rule to your skills. "be more concise."
next week, another bad output. another rule. "use a casual tone."
but a month later, something else breaks. "always explain technical terms."
you keep stacking, and it feels productive because you're fixing problems as they come up.
but 3 months in, you've got 30 rules piled on top of each other.
some of them contradict each other ("be concise" and "always explain your reasoning" are fighting).
some of them fix problems that the model doesn't even have anymore.
and the model is trying to follow all of them at once, which means it's doing none of them well.
it's like handing a chef a 47-step recipe when they only need 12.
the extra 35 steps slow the chef down, make them second-guess the parts they already know, and the dish comes out worse than if you'd just let them cook.
that's what over-prompting does.
anthropic just published a piece on how they build claude code (the ai coding agent).
their own engineering team found that their scaffolding was making the ai worse
which means your custom instructions are almost certainly doing the same thing.
so here's the actionable move...
instead of manually reading through your setup line by line, just tell claude to audit itself.
if you're in claude's desktop app, claude already has access to your:
claude[.]md (the file where your preferences and rules live), your skills folder (where your reusable instruction files are stored), your context files, everything.
just open claude code/cowork and say this:
—
"read my entire setup before responding. check my claude .md, every skill in my skills folder, every file in my context folder, and any other instruction files you can find.
then go through every rule, instruction, and preference you found. for each one, tell me:
1. is this something you already do by default without being told?
2. does this contradict or conflict with another rule somewhere else in my setup?
3. does this repeat something that's already covered by a different rule or file?
4. does this read like it was added to fix one specific bad output rather than improve outputs overall?
5. is this so vague that you'd interpret it differently every time? (ex: 'be more natural' or 'use a good tone')
then give me a list of everything you'd cut with a one-line reason for each, a list of any conflicts you found between files, and a cleaned up version of my claude.md with the dead weight removed."
—
one message. claude goes and reads your entire setup, audits it, and comes back with exactly what to cut and why.
you don't dig through files, you don't read every rule yourself. it does the whole thing.
once you get the results, don't just blindly delete everything it flags.
here's the process:
1. read what it flagged and why
2. delete the flagged rules
3. run your 3 most common tasks with the trimmed setup
4. did the output stay the same or get better? the deleted rules were dead weight
5. did something specific break? add back just that one rule
the goal is to find the minimum viable setup that gets you the output you want.
your ai setup should be getting simpler over time.
addition by subtraction baby
the most dangerous thing about claude:
it's the world's most convincing YES-MAN
so i built a "board of advisors" skill that makes 5 agents attack your idea from 5 different angles:
• one assumes your idea will fail and tries to prove it
• one strips away your assumptions and rebuilds the problem from scratch
• one hunts for the bigger opportunity you're too close to see
• one has zero context about you and responds like a complete stranger
• one only cares about what you actually do next
then...
1. all 5 responses get anonymized and peer-reviewed blind
2. a chairman agent reads everything and synthesizes the final verdict
after a few minutes, you get one recommendation you can *actually* trust.
free skill + full breakdown:
Holy shit.
Someone just leaked the Claude Code project template teams are quietly using.
This isn't prompting anymore.
This is AI engineering infrastructure. ⚡
The entire setup revolves around one file: CLAUDE.md
Every time Claude makes a mistake → you add a rule
Every time you repeat yourself → you add a workflow
Every time something breaks → you add a guardrail
Claude literally trains itself on your project.
And the structure is wild:
• CLAUDE.md → project memory & instructions
• skills/ → reusable AI workflows
• hooks/ → automated checks & guardrails
• docs/ → architecture decisions
• src/ → actual code modules
• tools/ → scripts + prompts
You're not chatting with AI anymore.
You're building an AI that knows your repo.
The craziest part?
You only configure this once.
After that Claude: – reviews code automatically
– refactors on command
– enforces architecture rules
– writes release notes
– runs workflows from skills
– remembers past mistakes
And it keeps getting smarter.
Most people:
open ChatGPT → write prompt → copy paste → repeat
This setup:
open terminal → run skill → code shipped
You're basically running AI teammates inside your repo.
This template is the difference between: • using Claude occasionally
• running Claude like infrastructure
Drop it in any project.
Your AI stops guessing — and starts operating.
BREAKING
Elon Musk endorsed my Top 26 Essential Papers for Mastering LLMs and Transformers
Implement those and you’ve captured ~90% of the alpha behind modern LLMs.
Everything else is garnish.
This list bridges the Transformer foundations
with the reasoning, MoE, and agentic shift
Recommended Reading Order
1. Attention Is All You Need (Vaswani et al., 2017)
> The original Transformer paper. Covers self-attention,
> multi-head attention, and the encoder-decoder structure
> (even though most modern LLMs are decoder-only.)
2. The Illustrated Transformer (Jay Alammar, 2018)
> Great intuition builder for understanding
> attention and tensor flow before diving into implementations
3. BERT: Pre-training of Deep Bidirectional Transformers (Devlin et al., 2018)
> Encoder-side fundamentals, masked language modeling,
> and representation learning that still shape modern architectures
4. Language Models are Few-Shot Learners (GPT-3) (Brown et al., 2020)
> Established in-context learning as a real
> capability and shifted how prompting is understood
5. Scaling Laws for Neural Language Models (Kaplan et al., 2020)
> First clean empirical scaling framework for parameters, data, and compute
> Read alongside Chinchilla to understand why most models were undertrained
6. Training Compute-Optimal Large Language Models (Chinchilla) (Hoffmann et al., 2022)
> Demonstrated that token count matters more than
> parameter count for a fixed compute budget
7. LLaMA: Open and Efficient Foundation Language Models (Touvron et al., 2023)
> The paper that triggered the open-weight era
> Introduced architectural defaults like RMSNorm, SwiGLU
> and RoPE as standard practice
8. RoFormer: Rotary Position Embedding (Su et al., 2021)
> Positional encoding that became the modern default for long-context LLMs
9. FlashAttention (Dao et al., 2022)
> Memory-efficient attention that enabled long context windows
> and high-throughput inference by optimizing GPU memory access.
10. Retrieval-Augmented Generation (RAG) (Lewis et al., 2020)
> Combines parametric models with external knowledge sources
> Foundational for grounded and enterprise systems
11. Training Language Models to Follow Instructions with Human Feedback (InstructGPT) (Ouyang et al., 2022)
> The modern post-training and alignment blueprint
> that instruction-tuned models follow
12. Direct Preference Optimization (DPO) (Rafailov et al., 2023)
> A simpler and more stable alternative to PPO-based RLHF
> Preference alignment via the loss function
13. Chain-of-Thought Prompting Elicits Reasoning in Large Language Models (Wei et al., 2022)
> Demonstrated that reasoning can be elicited through prompting
> alone and laid the groundwork for later reasoning-focused training
14. ReAct: Reasoning and Acting (Yao et al., 2022 / ICLR 2023)
> The foundation of agentic systems
> Combines reasoning traces with tool use and environment interaction
15. DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning (Guo et al., 2025)
> The R1 paper. Proved that large-scale reinforcement learning without
> supervised data can induce self-verification and structured reasoning behavior
16. Qwen3 Technical Report (Yang et al., 2025)
> A modern architecture lightweight overview
> Introduced unified MoE with Thinking Mode and Non-Thinking
> Mode to dynamically trade off cost and reasoning depth
17. Outrageously Large Neural Networks: Sparsely-Gated Mixture of Experts (Shazeer et al., 2017)
> The modern MoE ignition point
> Conditional computation at scale
18. Switch Transformers (Fedus et al., 2021)
> Simplified MoE routing using single-expert activation
> Key to stabilizing trillion-parameter training
19. Mixtral of Experts (Mistral AI, 2024)
> Open-weight MoE that proved sparse models can match dense quality
> while running at small-model inference cost
20. Sparse Upcycling: Training Mixture-of-Experts from Dense Checkpoints (Komatsuzaki et al., 2022 / ICLR 2023)
> Practical technique for converting dense checkpoints into MoE models
> Critical for compute reuse and iterative scaling
21. The Platonic Representation Hypothesis (Huh et al., 2024)
> Evidence that scaled models converge toward shared
> internal representations across modalities
22. Textbooks Are All You Need (Gunasekar et al., 2023)
> Demonstrated that high-quality synthetic data allows
> small models to outperform much larger ones
23. Scaling Monosemanticity: Extracting Interpretable Features from Claude 3 Sonnet (Templeton et al., 2024)
> The biggest leap in mechanistic interpretability
> Decomposes neural networks into millions of interpretable features
24. PaLM: Scaling Language Modeling with Pathways (Chowdhery et al., 2022)
> A masterclass in large-scale training
> orchestration across thousands of accelerators
25. GLaM: Generalist Language Model (Du et al., 2022)
> Validated MoE scaling economics with massive
> total parameters but small active parameter counts
26. The Smol Training Playbook (Hugging Face, 2025)
> Practical end-to-end handbook for efficiently training language models
Bonus Material
> T5: Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer (Raffel et al., 2019)
> Toolformer (Schick et al., 2023)
> GShard (Lepikhin et al., 2020)
> Adaptive Mixtures of Local Experts (Jacobs et al., 1991)
> Hierarchical Mixtures of Experts (Jordan and Jacobs, 1994)
If you deeply understand these fundamentals; Transformer core, scaling laws, FlashAttention, instruction tuning, R1-style reasoning, and MoE upcycling, you already understand LLMs better than most
Time to lock-in, good luck!



































![itsolelehmann's tweet photo. i deleted half my Claude setup last week and every output got BETTER
sounds backwards, but anthropic's own team just explained exactly why it works.
here's the one prompt that tells you what to cut (and you don't even have to paste anything):
this is what happens to everyone...
you get a bad output, so you add a rule to your skills. "be more concise."
next week, another bad output. another rule. "use a casual tone."
but a month later, something else breaks. "always explain technical terms."
you keep stacking, and it feels productive because you're fixing problems as they come up.
but 3 months in, you've got 30 rules piled on top of each other.
some of them contradict each other ("be concise" and "always explain your reasoning" are fighting).
some of them fix problems that the model doesn't even have anymore.
and the model is trying to follow all of them at once, which means it's doing none of them well.
it's like handing a chef a 47-step recipe when they only need 12.
the extra 35 steps slow the chef down, make them second-guess the parts they already know, and the dish comes out worse than if you'd just let them cook.
that's what over-prompting does.
anthropic just published a piece on how they build claude code (the ai coding agent).
their own engineering team found that their scaffolding was making the ai worse
which means your custom instructions are almost certainly doing the same thing.
so here's the actionable move...
instead of manually reading through your setup line by line, just tell claude to audit itself.
if you're in claude's desktop app, claude already has access to your:
claude[.]md (the file where your preferences and rules live), your skills folder (where your reusable instruction files are stored), your context files, everything.
just open claude code/cowork and say this:
—
"read my entire setup before responding. check my claude .md, every skill in my skills folder, every file in my context folder, and any other instruction files you can find.
then go through every rule, instruction, and preference you found. for each one, tell me:
1. is this something you already do by default without being told?
2. does this contradict or conflict with another rule somewhere else in my setup?
3. does this repeat something that's already covered by a different rule or file?
4. does this read like it was added to fix one specific bad output rather than improve outputs overall?
5. is this so vague that you'd interpret it differently every time? (ex: 'be more natural' or 'use a good tone')
then give me a list of everything you'd cut with a one-line reason for each, a list of any conflicts you found between files, and a cleaned up version of my claude.md with the dead weight removed."
—
one message. claude goes and reads your entire setup, audits it, and comes back with exactly what to cut and why.
you don't dig through files, you don't read every rule yourself. it does the whole thing.
once you get the results, don't just blindly delete everything it flags.
here's the process:
1. read what it flagged and why
2. delete the flagged rules
3. run your 3 most common tasks with the trimmed setup
4. did the output stay the same or get better? the deleted rules were dead weight
5. did something specific break? add back just that one rule
the goal is to find the minimum viable setup that gets you the output you want.
your ai setup should be getting simpler over time.
addition by subtraction baby](https://pbs.twimg.com/media/HEGNR64boAA8x4U.jpg)






















