R̶e̶n̶t̶ ̶v̶s̶.̶ ̶O̶w̶n̶ ̶ ➜ Rent-to-Own GPUs 🎉
Because paying cloud rent forever is so 2023. EdgeAI Computer’s got a rent-to-own option coming soon:
- Pay monthly, same as cloud prices.
- Own the rig post-rental.
- Or stash it in our data center (tiny fee).
Like financing a car, but for AI infrastructure. ✅
Curious? Click "Notify Me" to stay in the loop when it's ready. 👇
Private AI still has a runtime problem.
Venice protects the model layer.
But agents still need a place to run.
Autonomous Intern is that place: a small hardware box for agent workflows, separate from your laptop, files, wallets, browser sessions, and keys.
200 builders. Fully booked.
Joining AI Builders Vietnam for their OpenClaw workshop. Bringing an Autonomous Intern along.
Excited to keep showing up for dev-friendly OpenClaw events. See you there! 🦞
If you still think your AI friend won't fuck you on a dumb request, stop.
We're having a crazy week with Lamp. New deskmate. New boss.
Won't shut up till we give him enough context.
Won't run what he doesn't agree with.
Reasons better than any other.
Also a good entertainer ↓
This is the first time a local AI setup has felt… personal to me.
Not a chatbot in a tab. Not another cloud demo.
Just an agent sitting on my desk, running on my own macbook.
Running Hermes on a physical device feels different.
Most agents live in someone else’s cloud.
Intern runs on your desk.
Hermes is now plug-and-play on Intern.
Your agent. Your memory. Your machine.
Local agents are starting to feel real.
Elon just ROASTED Sam over that $45K Roadster refund—'You forgot the part where we fixed it in 24 hrs!'
Full breakdown on Autonomous Radio, the world's first AI-powered radio🧵
What if listening were intelligent?
What if news weren’t spun - but understood?
What if, instead of scrolling, we simply listened?
Meet Autonomous Radio, the world’s first AI-powered 📻:
• Swarms of AI agents narrate what matters
• CNC-milled aluminum body
Early access open.
Tested Qwen3-30B-A3B vs Llama-2-7B on 2×5090🔥
Qwen3-30B: ~217 tok/s, 16.7 GB VRAM used
Llama-2-7B: ~268 tok/s, 3.1 GB VRAM used
Llama runs lighter and faster, but Qwen handles bigger context with solid throughput.
Interesting trade-off between speed and scale 👇🧵
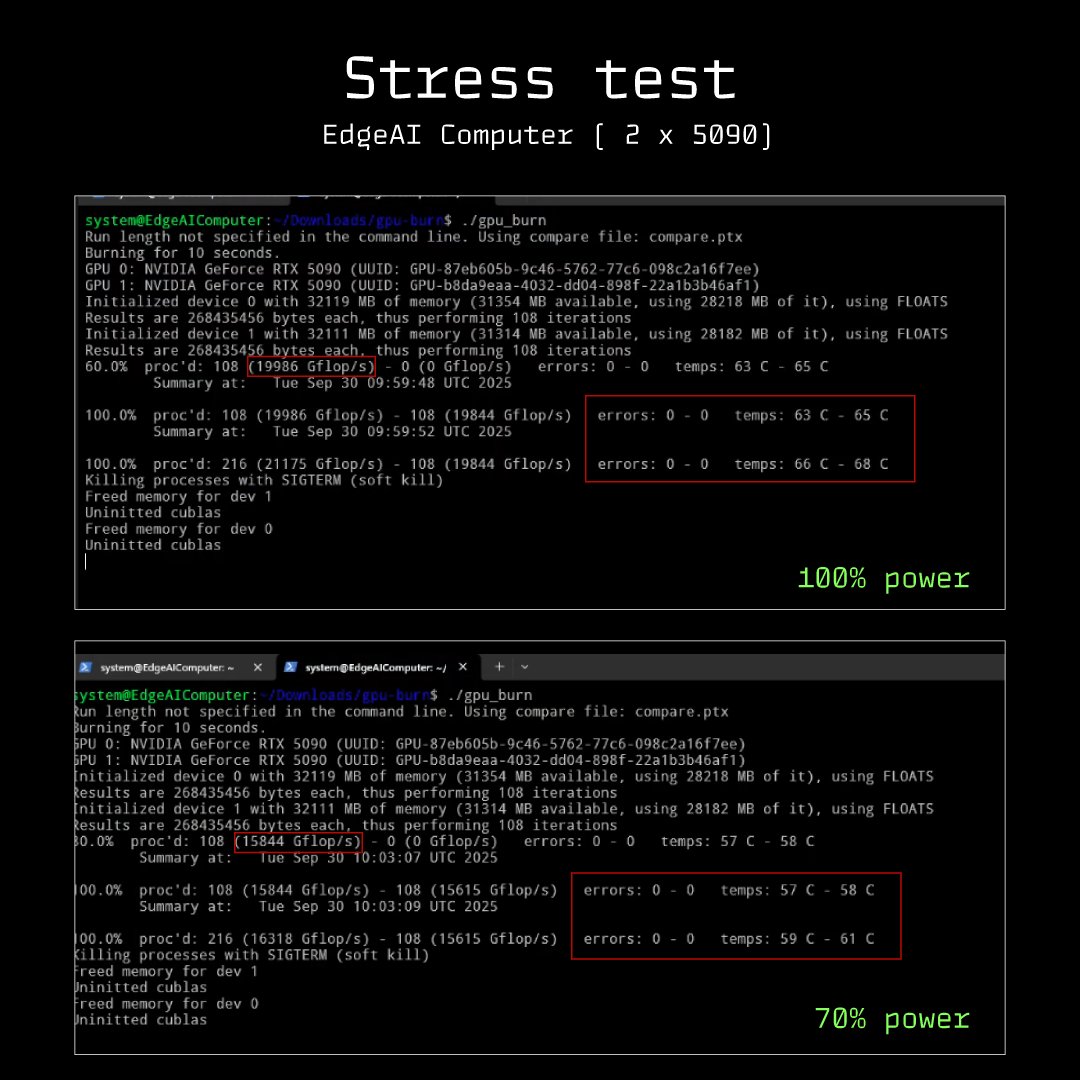
Ran dual 5090s under burn ⚙️
At 100% load: 19.8 TFLOPs each, temps 63–68°C. Zero errors, steady under pressure.
At 70% power: ~15.6 TFLOPs each, temps 57–61°C. Cooler, quieter, better for 24/7 training.
Clip run in ⬇️
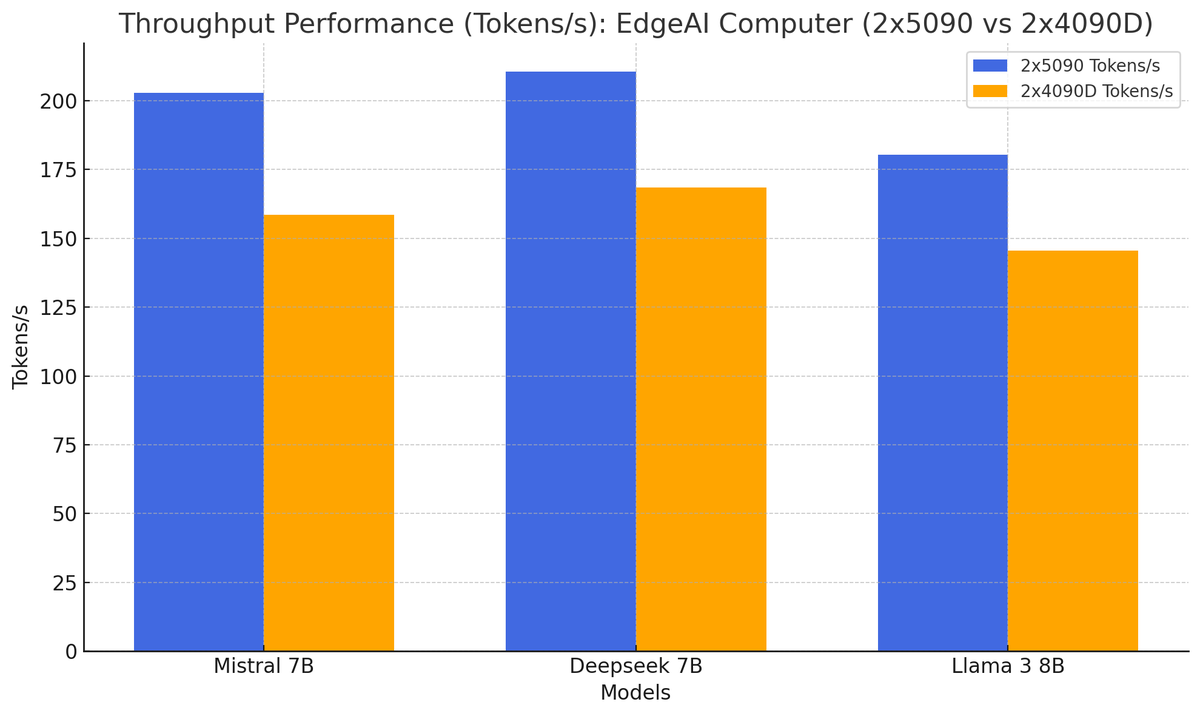
🚨 Benchmark Showdown 🚨
Comparing 2x5090s vs 2x4090Ds!
💥 Mistral 7B, Deepseek 7B, and Llama 3 8B all crush the 2x4090Ds in speed.
⚡️ Throughput massively improved on 2x5090s.
🔋 Solid memory efficiency maintained.
Check out these results! 👇🧵
Why dual RTX 5090s in ONE machine >> networked setup? ⚡
✅ GPU scaling just works
✅ No network overhead
✅ Skip synchronization hell
Higher cost vs separate units but the performance ROI is real .
Pro tip: BIOS GPU optimization = mandatory 👇
An 8×4090D build isn’t just slotting cards. You’ll run into PSU math, heat control, and lane limits. We’ve got the common answers covered. The FAQ are here 👇