Meet Gemma 4 12B!
A unified, encoder-free multimodal model designed to bring high-performance intelligence directly to your laptop, and released under an Apache 2.0 license.
Bridging the gap between edge efficiency and advanced reasoning. Here is what’s new with Gemma 4 12B: 👇
Meet DubDub AI, the tool that just flipped video creation on its head!
https://t.co/5zWQeQbZiw
Transcription ✅
Subtitles ✅
Translation in 100+ languages ✅
Drop a video in. Get back a fully dubbed, subtitled, translated version in 100+ languages. 🔥
#DubDubAI
.@GoogleDeepMind Gemma 4 is here with state-of-the-art models targeting edge and workstations.
Requires Ollama 0.20+ that is rolling out.
4 models:
4B Effective (E4B)
ollama run gemma4:e4b
2B Effective (E2B)
ollama run gemma4:e2b
26B (4B active MoE)
ollama run gemma4:26b
31B (Dense)
ollama run gemma4:31b
Benchmarks 👇👇👇
Meet the new Stitch, your vibe design partner.
Here are 5 major upgrades to help you create, iterate and collaborate:
🎨 AI-Native Canvas
🧠 Smarter Design Agent
🎙️ Voice
⚡️ Instant Prototypes
📐 Design Systems and DESIGN.md
Rolling out now. Details and product walkthrough video in 🧵
AI is changing the way we design.
Excited to see Stitch by Google turning natural language into high-fidelity UI designs and interactive prototypes in seconds.
This could seriously speed up app and product development. 🚀
Introducing the new @stitchbygoogle, Google’s vibe design platform that transforms natural language into high-fidelity designs in one seamless flow.
🎨Create with a smarter design agent: Describe a new business concept or app vision and see it take shape on an AI-native canvas.
⚡️ Iterate quickly: Stitch screens together into interactive prototypes and manage your brand with a portable design system.
🎤 Collaborate with voice: Use hands-free voice interactions to update layouts and explore new variations in real-time.
Try it now (Age 18+ only. Currently available in English and in countries where Gemini is supported.) → https://t.co/pmT9iHEpZa
Introducing the new @stitchbygoogle, Google’s vibe design platform that transforms natural language into high-fidelity designs in one seamless flow.
🎨Create with a smarter design agent: Describe a new business concept or app vision and see it take shape on an AI-native canvas.
⚡️ Iterate quickly: Stitch screens together into interactive prototypes and manage your brand with a portable design system.
🎤 Collaborate with voice: Use hands-free voice interactions to update layouts and explore new variations in real-time.
Try it now (Age 18+ only. Currently available in English and in countries where Gemini is supported.) → https://t.co/pmT9iHEpZa
Say you have trained your deep learning model. It works. But do you know what it has actually learned?
🚀 We’ve built SymTorch: a library that translates deep learning models into human-readable equations.
I've attached here a quick video demonstrating how SymTorch works.
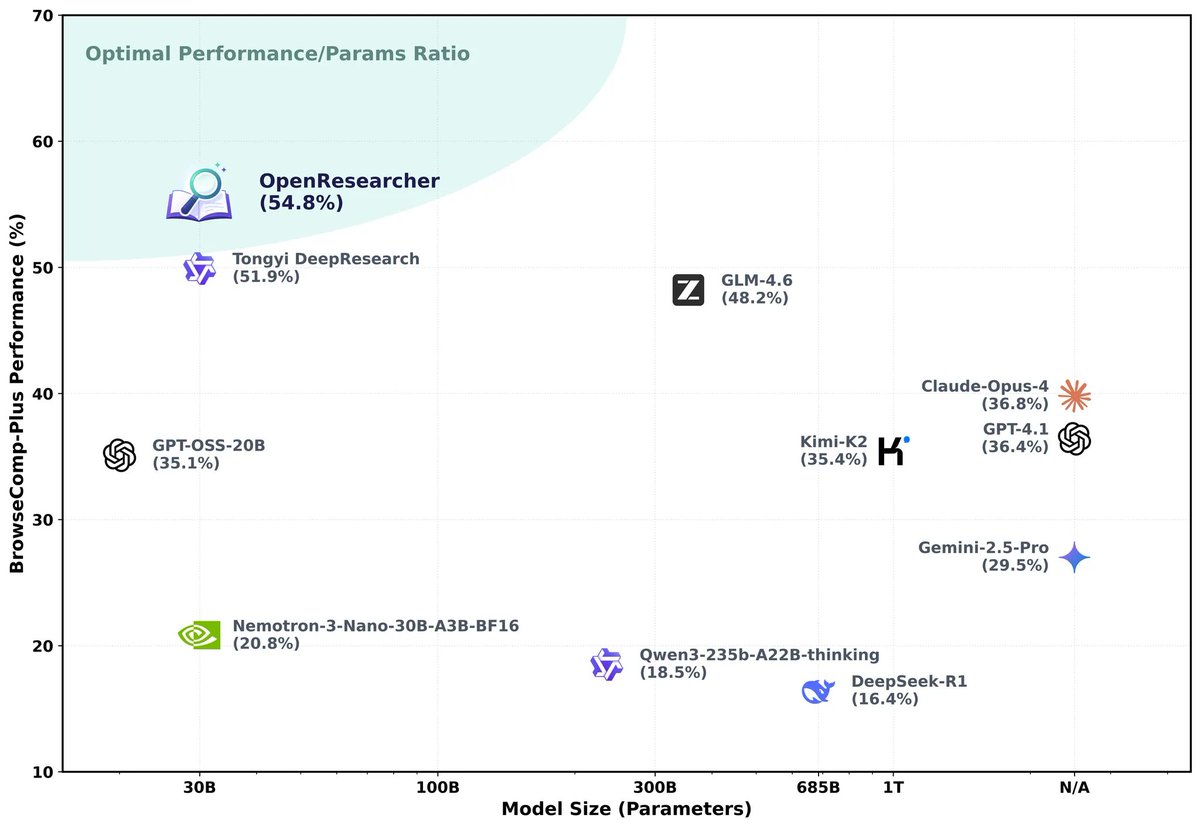
🚀 Introducing OpenResearcher: a fully offline pipeline for synthesizing 100+ turn deep-research trajectories—no search/scrape APIs, no rate limits, no nondeterminism.
💡 We use GPT-OSS-120B + a local retriever + a 10T-token corpus to generate long-horizon tool-use traces (search → open → find) that look like real browsing, but are free + reproducible.
📈 The payoff: SFT on these trajectories turns Nemotron-3-Nano-30B-A3B from 20.8% → 54.8% accuracy on BrowseComp-Plus (+34.0).
🧩 What makes it work?
🔎 Offline corpus = 15M FineWeb docs + 10K “gold” passages (bootstrapped once)
🧰 Explicit browsing primitives = better evidence-finding than “retrieve-and-read”
🎯 Reject sampling = keep only successful long-horizon traces
🧵 And we’re releasing everything:
✅ code + search engine + corpus recipe
✅ 96K-ish trajectories + eval logs
✅ trained models + live demo
👨💻 GitHub: https://t.co/0yWxIRzyDz
🤗 Models & data: https://t.co/AtweQjWF73
🚀 Demo: https://t.co/yBOXSoeWZ9
🔎 Eval logs: https://t.co/zIqfq0TKca
#llms #agentic #deepresearch #tooluse #opensource #retrieval #SFT
🚨 Just in OpenAI releases gpt-oss: powerful open-weight models for reasoning & agentic tasks.
🧠 120B (H100-ready)
⚡ 20B (local-friendly)
✅ Apache 2.0, fine-tunable, CoT access, browsing & Python tools
📥 Get them on Hugging Face:
https://t.co/6aQNEzxpx2
#gptOSS#LLM
AI Agents vs. Agentic AI
Interesting paper summarizing distinctions between AI Agents and Agentic AI.
It also talks about the key ideas, solutions, and the future.
Here are my notes:
New course: MCP: Build Rich-Context AI Apps with Anthropic. Learn to build AI apps that access tools, data, and prompts using the Model Context Protocol in this short course, created in partnership with Anthropic @AnthropicAI and taught by Elie Schoppik @eschoppik, its Head of Technical Education.
Connecting AI applications to external systems that bring rich context to LLM-based applications has often meant writing custom integrations for each use case. MCP is an open protocol that standardizes how LLMs access tools, data, and prompts from external sources, and simplifies how you provide context to your LLM-based applications. For example, you can provide context via third-party tools that let your LLM make API calls to search the web, access data from local docs, retrieve code from a GitHub repo, and so on.
MCP, developed by Anthropic, is based on a client-server architecture that defines the communication details between an MCP client, hosted inside the AI application, and an MCP server that exposes tools, resources, and prompt templates. The server can be a subprocess launched by the client that runs locally or an independent process running remotely.
In this hands-on course, you'll learn the core architecture behind MCP. You’ll create an MCP-compatible chatbot, build and deploy an MCP server, and connect the chatbot to your MCP server and other open-source servers.
Here’s what you’ll do:
- Understand why MCP makes AI development less fragmented and standardizes connections between AI applications and external data sources
- Learn the core components of the client-server architecture of MCP and the underlying communication mechanism
- Build a chatbot with custom tools for searching academic papers, and transform it into an MCP-compatible application
- Build a local MCP server that exposes tools, resources, and prompt templates using FastMCP, and test it using MCP Inspector
- Create an MCP client inside your chatbot to dynamically connect to your server
- Connect your chatbot to reference servers built by Anthropic’s MCP team, such as filesystem, which implements filesystem operations, and fetch, which extracts contents from the web as markdown
- Configure Claude Desktop to connect to your server and others, and explore how it abstracts away the low-level logic of MCP clients
- Deploy your MCP server remotely and test it with the Inspector or other MCP-compatible applications
- Learn about the roadmap for future MCP development, such as multi-agent architecture, MCP registry API, server discovery, authorization, and authentication
MCP is an exciting and important technology that lets you build rich-context AI applications that connect to a growing ecosystem of MCP servers, with minimal integration work.
Please sign up here! https://t.co/UDyp8NRe8R
LLMs Get Lost in Multi-turn Conversation
The cat is out of the bag.
Pay attention, devs.
This is one of the most common issues when building with LLMs today.
Glad there is now paper to share insights.
Here are my notes:
A drag-and-drop visual tool to build AI agents.
Langflow lets you build and deploy AI-powered agents and workflows. Supports all major LLMs, vector DBs, etc.
100% open-source with 61k+ stars!
Your brain doesn't forget - it just loses the keys to unlock memories
This paper introduces key-value memory architecture that separates storage and retrieval representations in brain memory systems, optimizing for both fidelity and discriminability.
-----
🧠 Original Problem:
→ Traditional memory models rely on similarity-based retrieval, limiting their ability to optimize separately for storage and retrieval
→ Current models can't explain how memories persist for decades despite rare access or how forgotten memories can be recovered
-----
🔑 Solution in this Paper:
→ The paper proposes a key-value memory system where inputs are transformed into two distinct representations: keys for memory addresses and values for memory content
→ Keys optimize for discriminability in retrieval while values optimize for storage fidelity
→ The hippocampus acts as key storage, while neocortex serves as value storage
→ Memories are accessed by matching queries to keys, then retrieving values weighted by match strength
-----
💡 Key Insights:
→ Memory failures occur due to retrieval issues, not storage limitations
→ Information once stored is never permanently lost
→ The brain implements error correction through attractor dynamics
→ Hippocampal representations optimize for discrimination while neocortical ones optimize for semantic content
-----
📊 Results:
→ Model demonstrates recovery of "silent" memories without retraining
→ Achieves 99% accuracy on initial tasks and 95% on subsequent tasks
→ Shows graceful degradation instead of catastrophic forgetting
→ Outperforms flexible encoders trained to minimize reconstruction error
This paper from DeepMind is blowing my
mind:
“Our findings reveal that models fine-tuned on weaker & cheaper generated data consistently outperform those trained on stronger & more-expensive generated data across multiple benchmarks…”
LLMs know themselves better than others know them, proving they have genuine self-awareness capabilities.
Self-prediction tests reveal LLMs have privileged access to their own decision-making process
Original Problem 🔍:
LLMs can acquire knowledge through introspection, but this capability is not well understood or measured.
-----
Solution in this Paper 🧠:
• Introduces a framework to measure introspection in LLMs
• Defines introspection as acquiring knowledge not derived from training data
• Proposes self-prediction tasks to test introspective abilities
• Compares self-prediction accuracy with cross-prediction by other models
• Evaluates model calibration and adaptation to behavioral changes
-----
Key Insights from this Paper 💡:
• LLMs can introspect on simple behavioral properties
• Self-prediction outperforms cross-prediction, suggesting privileged access to internal states
• Introspective abilities are robust to intentional behavior modifications
• Current models struggle with introspection on complex tasks or out-of-distribution generalization
-----
Results 📊:
• Self-prediction accuracy: GPT-4o (49.4%), Llama 70B (48.5%), GPT-3.5 (37.9%)
• Self-prediction outperforms cross-prediction: Llama 70B predicts itself (48.5%) vs. GPT-4o predicting Llama 70B (31.8%)
• Self-prediction models show better calibration than cross-prediction models
• Models adapt predictions when behavior is changed through finetuning
One neural network learns to generate all possible neural networks through weight manifold magic, as proposed in this paper
Learning a single continuous space of neural networks lets us morph between architectures effortlessly.
NeuMeta teaches neural networks to shapeshift, generating optimal weights for any network size on demand
Original Problem 🔍:
Neural networks are typically static and inflexible once trained, requiring separate models for different architectures or sizes. This limits adaptability and increases resource costs.
-----
Solution in this Paper 🧠:
• Neural Metamorphosis (NeuMeta) learns a continuous weight manifold for neural networks
• Uses Implicit Neural Representation (INR) as hypernetworks to generate weights
• Employs weight matrix permutation for intra-model smoothness
• Adds input noise for cross-model smoothness
• Optimizes INR with task-specific, reconstruction, and regularization losses
-----
Key Insights from this Paper 💡:
• NeuMeta enables dynamic network resizing without retraining
• Smoothness of weight manifold is crucial for performance
• Implicit knowledge distillation occurs across different model sizes
• NeuMeta generalizes to unseen network configurations
-----
Results 📊:
• Outperforms pruning methods and flexible models across various tasks
• Maintains full-size model performance at 75% compression rate
• Generalizes to network sizes outside training range
• Reduces storage and training costs for multiple model variants
• Demonstrates superior performance in image classification, segmentation, and generation tasks