@teortaxesTex@zhenbailian Hi! As a Qwen researcher, I'd like to clarify the nl2repo score changes: we discovered that some models "hack" the benchmark by using commands like "pip install" to access cloud repos. We re-evaluated all baselines with these commands disabled, detailed in our blog's footnote.
How to scale training environments for coding agents? Let the agent build their own! 🙌
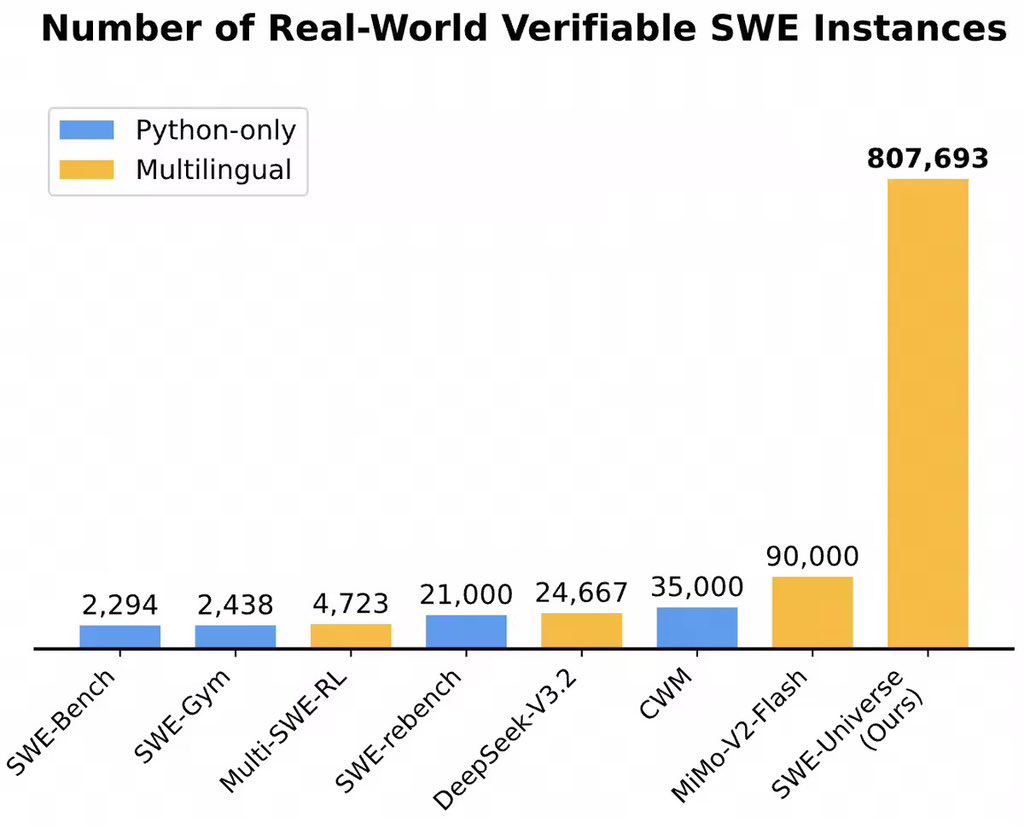
We introduce SWE-Universe 🪐, a scalable framework that turns GitHub PRs into real-world, multilingual, verifiable SWE environments. The agent configures each environment like a human expert, with extra safeguards for reliability.
We’ve validated these environments in both mid-training and RL for Qwen3-Coder-Next, and will push environment synthesis further as a path toward agent self-improvement. Let's move on!
👉 https://t.co/DRlw0fov9F
How far are we from natural language programming?
We introduce NoCode-bench, a benchmark with 634 real-world feature-addition tasks from software doc changes to validated code changes, towards answering this question.
Even top models struggle with new feature implementation from software docs, facing challenges such as cross-file edits, large codebase comprehension, and accurate tool use.
Paper: https://t.co/YCM2XdcHP8
Code: https://t.co/peULCECuQq
Hugging Face: https://t.co/7t2dZZrKvc
Leaderboard: https://t.co/gR0j44GL3z
@main_horse@teortaxesTex If combining with MoE, I tend to do an additional aggregation before each routing, to let the activation weights be the same among different streams. This may be more cost-efficient.
@johnowhitaker@huybery If you compair N=3B/P=1 and N=3B/P=2, the shape of loss curve is similar, so I believe the introduction of prefixes may be not too much related to the overfitting dynamics.
@johnowhitaker@huybery Of course, this is also a reasonable hypothesis 🤔 My previous hypothesis was that smaller-parameter models have weaker memorization capabilities, and therefore are less likely to overfit by excessively memorizing the fine-grained features of the dataset.
@TheodoreGalanos@huybery Thank you for your support! The inference code is directly applicable to existing qwen2.5 dense checkppint (setting P=1 by default). We may plan release a training code in the future, using huggingface Trainer, which is also effective in my early experiments.
How to select the best LLM-generated solution?
We discuss the theoretically optimal strategy for selecting the best LLM-generated solutions (e.g., unreliable code) based on LLM-generated validators (e.g., unreliable test cases) in our @ASE_conf paper
👉🏻 Paper: https://t.co/4mgfyz9tlT
👉🏻 Code: https://t.co/kNa9R2nOcf
1) We establish an optimal strategy for this problem within a Bayesian framework.
2) We show that identifying the best solution can be framed as an integer programming problem, and propose an efficient approach called B4 for approximating this optimal (yet uncomputable) strategy.
3) B4 significantly surpasses existing heuristics, achieving a relative performance improvement by up to 50% in the most challenging scenarios.
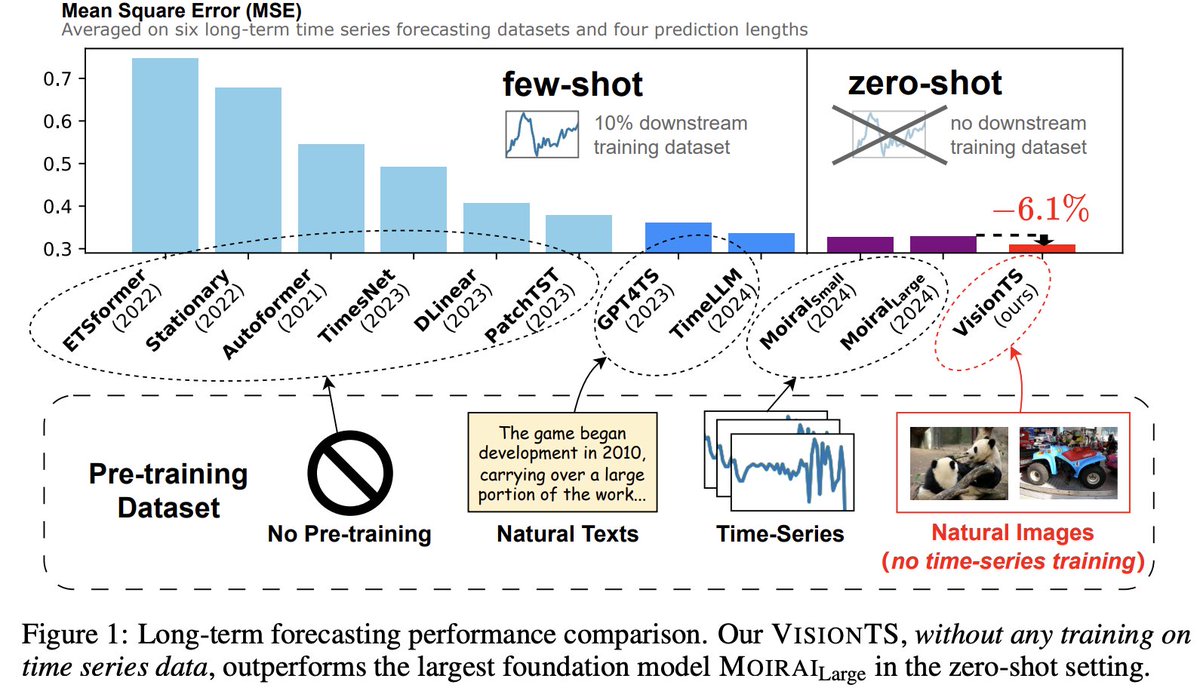
🚀 We’re thrilled to introduce VisionTS, a groundbreaking time series forecasting foundation model, building from rich, high-quality natural images without any time-series training and showing superior accuracy compared to SOTAs like Moirai, timesFM.
https://t.co/h2CC3asgRQ