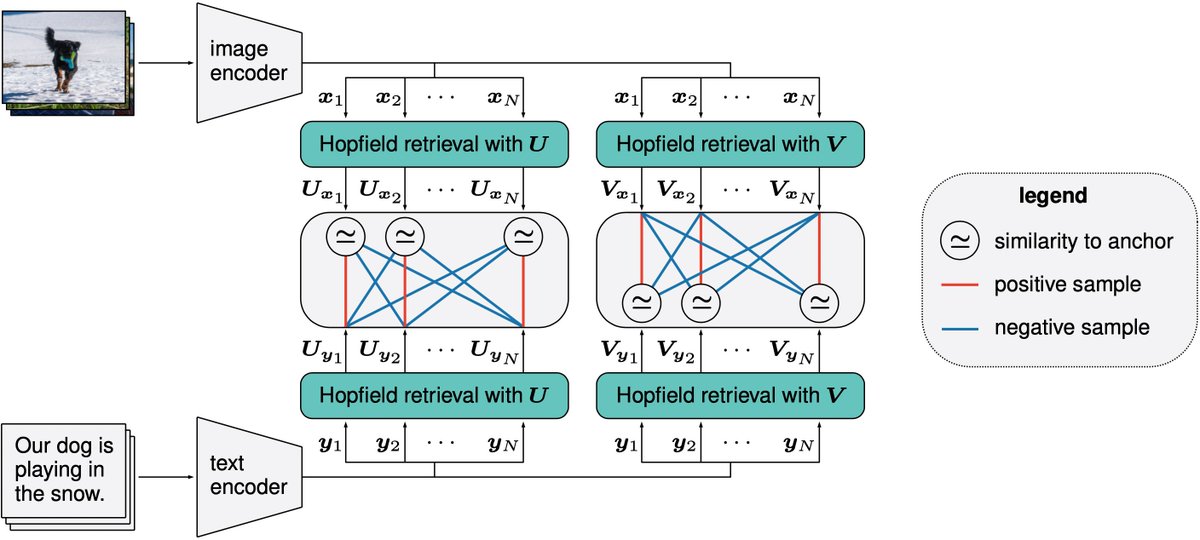
Automated knowledge graph generation pipelines often jump from unstructured text to triplets, producing inconsistent graphs that work for one-hop fact lookup but fail at multi-hop reasoning and degrade as they grow. We introduce HyDRA, a consistency-first pipeline.🧵 (1/9)
Excited to present our work “Large Language Models Can Self-Improve At Web Agent Tasks”. We show that synthetic data self-improvement boosts task completion by 31% on WebArena and introduce quality metrics for measuring autonomous agent workflows. #AI#MachineLearning#LLMs [1/n]
I am so excited that xLSTM is out. LSTM is close to my heart - for more than 30 years now. With xLSTM we close the gap to existing state-of-the-art LLMs. With NXAI we have started to build our own European LLMs. I am very proud of my team. https://t.co/IH7giCe3gd
🚀 SymbolicAI – a framework for logic-based approaches combining generative models and solvers. Alongside, we introduce a benchmark and empirical measure to evaluate SOTA LLMs in AI-centric workflows. Read more in our paper https://t.co/H49rfzf8tv #MachineLearning 🧠💡[1/n]
Interested in a semantic memory for reinforcement learning?
I was recently invited to a podcast talking about our #NeurIPS2023 paper: Semantic HELM (https://t.co/eRSbVWkFaz).
In case you are interested, you can stream the episode here:
https://t.co/NxCQCx6mIS
🎉 Exciting news! Our latest work has been published in Nature Communications. 🎉
CLOOME utilizes contrastive learning to connect microscopy images and chemical structures, paving the way for major advancements in drug discovery and beyond.🌟🔬💊
📜https://t.co/fH0wunVFLH
Personal update: last month, I re-joined the group of my mentor @HochreiterSepp and my amazing colleague @gklambauer in Linz, opening my own group "AI for data-driven simulations". We all share the vision to create a large-scale AI ecosystem in Linz. Big news to come soon 🚀
Thanks @_akhaliq for sharing!
SITTA unlocks zero-shot image captioning via a generative language model by aligning its embedding space with that of a pretrained vision encoder without any access to gradient information.
1/6
SITTA: A Semantic Image-Text Alignment for Image Captioning
paper page: https://t.co/cUYfM0UrJK
Textual and semantic comprehension of images is essential for generating proper captions. The comprehension requires detection of objects, modeling of relations between them, an assessment of the semantics of the scene and, finally, representing the extracted knowledge in a language space. To achieve rich language capabilities while ensuring good image-language mappings, pretrained language models (LMs) were conditioned on pretrained multi-modal (image-text) models that allow for image inputs. This requires an alignment of the image representation of the multi-modal model with the language representations of a generative LM. However, it is not clear how to best transfer semantics detected by the vision encoder of the multi-modal model to the LM. We introduce two novel ways of constructing a linear mapping that successfully transfers semantics between the embedding spaces of the two pretrained models. The first aligns the embedding space of the multi-modal language encoder with the embedding space of the pretrained LM via token correspondences. The latter leverages additional data that consists of image-text pairs to construct the mapping directly from vision to language space. Using our semantic mappings, we unlock image captioning for LMs without access to gradient information. By using different sources of data we achieve strong captioning performance on MS-COCO and Flickr30k datasets. Even in the face of limited data, our method partly exceeds the performance of other zero-shot and even finetuned competitors. Our ablation studies show that even LMs at a scale of merely 250M parameters can generate decent captions employing our semantic mappings. Our approach makes image captioning more accessible for institutions with restricted computational resources.
🚀 Excited to share our latest research on quantifying the predictive uncertainty of machine learning models. QUAM searches for adversarial models (not adversarial examples!) to better estimate the epistemic uncertainty, the uncertainty about chosen model parameters.
1/5
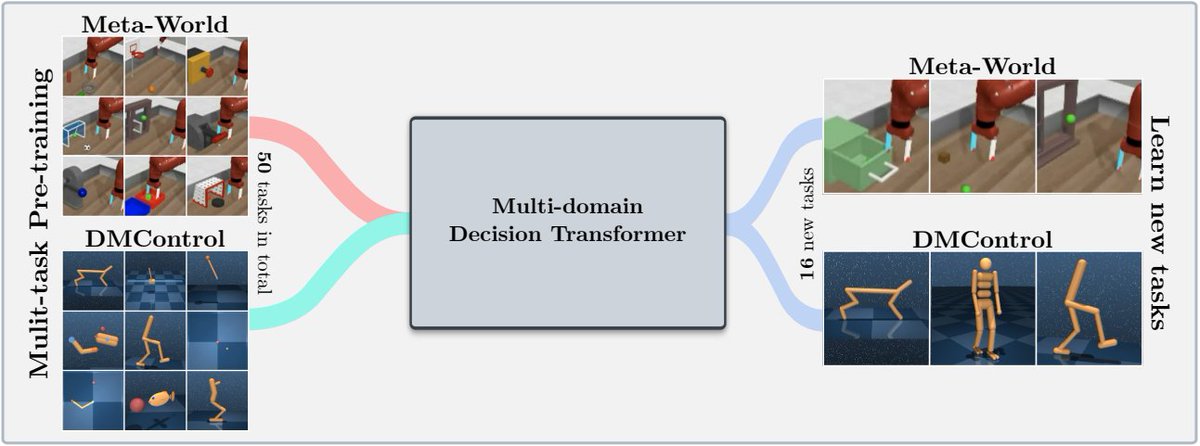
Excited to share our recent work on parameter-efficient fine-tuning in RL. We pre-train a Decision Transformer (DT) on 50 tasks from two domains, and subsequently fine-tune on various down-stream tasks. Joint work with @mrkhof, @PaischerFabian, Razvan, and @HochreiterSepp.
1/n
Excited to share our latest work on a semantic and interpretable memory module for RL! Complementary to recent developments in the realm of explainable AI, we focus on interpretability w.r.t. the memory of an agent.
1/n
We are excited to present our work, combining the power of a symbolic approach and Large Language Models (LLMs). Our Symbolic API bridges the gap between classical programming (Software 1.0) and differentiable programming (Software 2.0). GitHub: https://t.co/eYmfKFOWBz [1/n]
This includes fact-based generation of text, flow control of a generative process towards a desired outcome, and interpretability within generative processes. GitHub: https://t.co/eYmfKFOWBz [5/n]
Excited to share our work on history compression via language models in RL, presented at #ICML2022🤩🤩. Our novel framework HELM⎈ augments an agent with a history compression module which leverages a pretrained language Transformer without any training or finetuning 🤯🤯
1/5
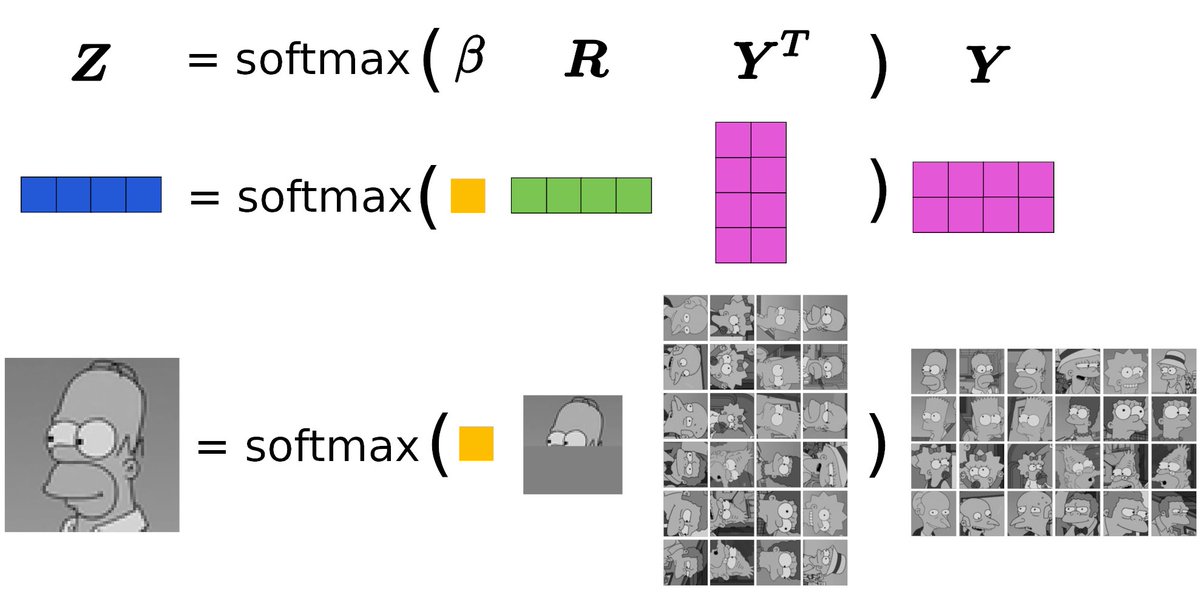
Wow, wanna see how to beat CLIP with the new CLOOB? Fantastic work lead by my colleagues @fuerst_andreas and @LizRumetshofer (Sepp Hochreiter's group) applying modern Hopfield networks to image-text data.
Paper: https://t.co/uATlB6nr9D
Blogpost: https://t.co/RLKgNYtL8M
Our paper "Hopfield Networks is All You Need" is accepted at #ICLR2021. Time to give some talks :) I am very honored to present our research today at the great platform of @ml_collective@savvyRL (https://t.co/vb2n5cMjcL).
【Final Sprint: #1MTreeChallenge】
Forest has in total planted 980 thousand trees and is about to hit 1 million now!
Let’s cross this milestone together: we will donate 1 tree for every 10 Likes or 1 Retweet of this tweet.🌲
Save the Earth at your fingertips🌏!












![DinuMariusC's tweet photo. Excited to present our work “Large Language Models Can Self-Improve At Web Agent Tasks”. We show that synthetic data self-improvement boosts task completion by 31% on WebArena and introduce quality metrics for measuring autonomous agent workflows. #AI #MachineLearning #LLMs [1/n] https://t.co/qBIV6lfw6h](https://pbs.twimg.com/media/GO6KikDaoAEisGP.png)







![DinuMariusC's tweet photo. We are excited to present our work, combining the power of a symbolic approach and Large Language Models (LLMs). Our Symbolic API bridges the gap between classical programming (Software 1.0) and differentiable programming (Software 2.0). GitHub: https://t.co/eYmfKFOWBz [1/n] https://t.co/PHoRaey253](https://pbs.twimg.com/media/Fm6dwWwaMAAVKye.jpg)