the next exciting thing im working on now is gonna be multi-branch prediction, i.e. predicting more than 1 branch per cycle to keep up with the fetch bandwidth demands of next generation CPUs. This has been announced to be included in Zen 5 too, so it's a hot topic atm
on the bright side the feedback from the more positive reviews was useful, so i'll include that for a submission to HPCA in a couple months. hopefully at some point i can just be done with this project entirely
tragically this didn't go well, got 2 strong rejects which was enough to not have the option for rebuttal. Frustratingly, it felt as if the reviewers giving strong rejects didn't understand that in doing so they were preventing me from addressing their very simple questions.
same anxiety as waiting for exam results. its not the end of the world if i don't get in but i'm not looking forward to having something i obsessed over torn apart.
Also, the icache prefetcher should really be fetch-directed prefetching with a decoupled frontend, which Gem5 does now have but its kind of broken and ruins BTB accuracy for now. But if that ever changes definitely include that too.
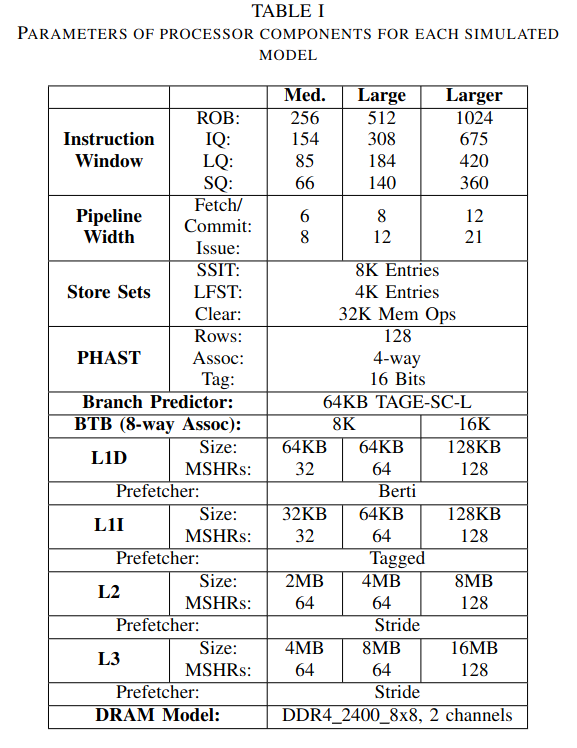
Table of Gem5 params for a paper I'm writing. The large model is meant to be a modern high-end workstation/server core. Hoping this helps lay out all the many small things you wanna be tuning in Gem5.
Not listed here: the default L2 latency is 40 cycles, which is what the L3 should be (!), set that to like 14. Also the L1-I can get away with 1 because in reality you'd use a u-op cache. You *can* use DDR5 but DDR4 actually has lower latency, which is better for spec.
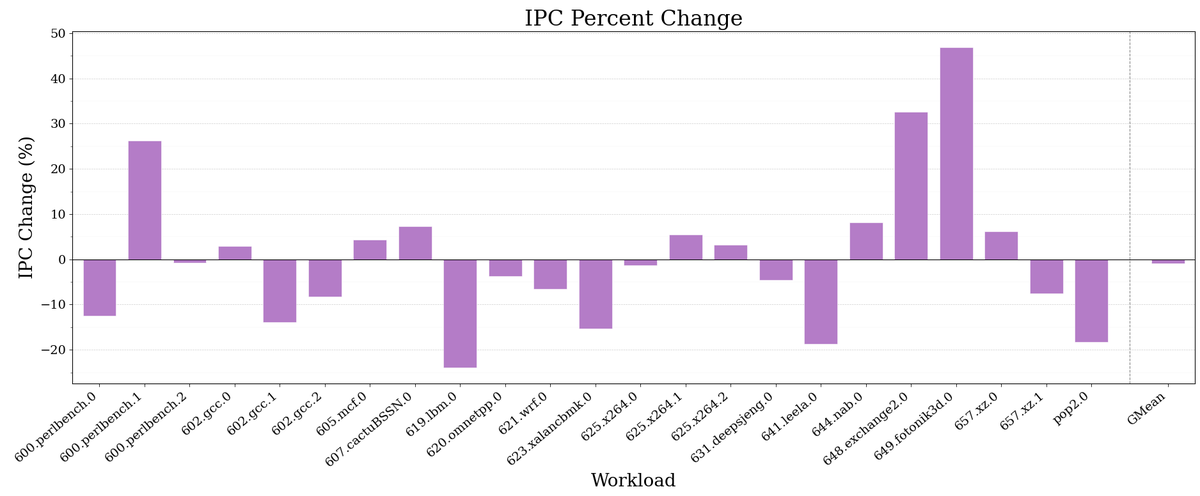
I actually think using LLVM isn't fair here because flang is so bad of a frontend that it leaves so many opportunities for PGO to pick up. But just looking at the C/++ workloads it seems to almost always make it worse!
Been playing about with PGO on spec2017 and this is what Gem5 says it does to performance:
(profiles came from the train inputs and compiled with LLVM 22)
tempted to say i wish it came out from the start of my phd but, maybe for the best i was forced to learn how to do this stuff decently by hand before having it automated
anyway, what we really need now are agents that are integrated into your environment
i have to say phd work has become twice as easy since claude, all the tedious python scripting for wrangling results and plotting graphs are like the perfect use case
On the other hand they removed x264 which was disproportionately my biggest performance win. They replaced it with flac but as that works on 1D data instead of 2D there'll probably be fewer independent loads for my work to win on </3
Spec2026 is released. I look forward to figuring out all the new miscellaneous problems like 'bwaves needs 16GB of stack space' and 'xz compiles to insane bitshifts that break gem5's X86 frontend'
Seriously though some of the new workload selections look cool. I'm surprised it took this long to switch from perl to python, but it makes way more sense + it'll be nice not to have to disable strict aliasing and LTO. It also includes Gem5! So I'll be simulating Gem5 on Gem5