🚨 Cambridge just dropped 10 FREE AI & ML textbooks (quietly).
University-level. Zero cost. Absolute gold for builders & learners.
Here’s the list with direct links 🧵👇
1️⃣ Understanding Machine Learning
Theory meets algorithms
https://t.co/TWZmFGMDyh
2️⃣ Mathematics for ML
Linear algebra → calculus made intuitive
https://t.co/ag8j2MWvHC
3️⃣ Mathematical Analysis of ML
The theory behind the code
https://t.co/gUESoNwlMH
4️⃣ Deep Learning Principles
Neural networks explained clearly
https://t.co/aiywLbVKo1
5️⃣ ML with Networks
Neurons → backpropagation
https://t.co/NAVAdjnRko
6️⃣ Deep Learning on Graphs
Graph Neural Networks & modern architectures
https://t.co/aec6tHviN1
7️⃣ Algorithmic ML
Complexity & optimization theory
https://t.co/sx1xxY9eMo
8️⃣ Probability Theory
Statistical foundations with examples
https://t.co/9QFqascQx9
9️⃣ Elementary Probability
Beginner-friendly + real-world use
https://t.co/a2NyOSNzlf
🔟 Advanced Data Analysis
Statistical learning for production systems
https://t.co/RqiDvLMNmc
💡 Free textbooks. Cambridge quality.
Perfect for students, engineers & AI builders.
Save 🔖 | Repost ♻️ | Follow for more AI resources 🤝
#AI #MachineLearning #DeepLearning #FreeResources #DataScience #StudyAI
🚨 ANOTHER MASTERCLASS FROM @3BLUE1BROWN
The compressibility of language isn’t just a math curiosity, it’s the hidden engine behind every LLM you use.
Grant’s new video reframes Shannon’s entropy through one elegant lens:
Prediction IS compression.
→ The better you predict the next word, the fewer bits you need to store it
→ Shannon measured English at ~1 bit per character: astonishingly compressible
→ This is exactly what GPT-style models optimize
→ Intelligence, in this framing, is compression
FUN FACT: Von Neumann told Shannon to name it “entropy” because nobody truly understands it anyway 😄
Decades later, that same concept became the bedrock of modern AI.
Deep-dive resources in the 🧵 ↓
If you want to become good at AI engineering (in 3 weeks), then learn these 15 concepts:
1 AI Agents: Memory, State & Consistency
→ https://t.co/v8H7O00jub
2 Machine Learning System Design 101
→ https://t.co/9MkHcLb5e0
3 Design Personal AI Chat Assistant
→ https://t.co/nNWq3onTnW
4 How RAG Works
→ https://t.co/cGmunPTUlb
5 LLM Concepts - A Deep Dive
→ https://t.co/5lCKxq2g4N
6 How to Design an AI Agent
→ https://t.co/JvnPd9773A
7 What is Reinforcement Learning
→ https://t.co/AVpl9j1oit
8 How Vector Databases Work
→ https://t.co/FVxan8xHH3
9 Context Engineering 101
→ https://t.co/OMkiZhkODL
10 AI Coding Workflow 101
→ https://t.co/paIf9ksIU9
11 LLM Evals Explained
→ https://t.co/nv3Ol8W53p
12 How AI Agents Work
→ https://t.co/tk3zkCjRvg
13 How MCP Works
→ https://t.co/wgf8gHnnkn
14 Agentic Patterns Explained
→ https://t.co/8YdBBWvTj1
15 Multi-Agent Architecture Explained
→ https://t.co/rS5QQS7Jln
What else should make this list?
===
👋 PS - Want my System Design Playbook for FREE?
Join my newsletter with 210K+ software engineers right now:
→ https://t.co/ByOFTtOihX
===
💾 Save & RT to help others ace AI engineering.
👤 Follow @systemdesignone + turn on notifications.
karpathy said it best - most people paying for claude aren't actually using claude. they're typing prompts into a $20/mo chatbox
meanwhile claude code ships with built-in features that replace 90% of plugins people install and nobody knows they exist
i had 23 plugins. deleted all of them. my sessions got 3x longer and my outputs got sharper
watch the video then read the full breakdown below - you'll probably uninstall half your setup by tonight
The creator of Claude Code just broke coding in 30 minutes.
No long tutorials.
No fluff.
Just pure “vibe-coding.”
People spend HOURS learning this… and still miss it.
Save this.
This changes how you build forever.
Why is no one talking about this?
@nvidia is offering around 80 AI models via hosted APIs absolutely for free.
You get access to MiniMax M2.7, GLM 5.1, Kimi 2.5, DeepSeek 3.2, GPT-OSS-120B, Sarvam-M etc.
This plugs straight into OpenClaude, OpenCode, Zed IDE, Hermes agent and even with Cursor IDE.
Setup:
– Grab API key: https://t.co/Wfdclm0hY2
– base_url = "https://t.co/VOGC10LmGP"
– api_key = "$NVIDIA_API_KEY"
– select model (e.g. minimaxai/minimax-m2.7)
If you’re building or experimenting, this is basically free inference.
Lock in and start building today anon.
Thank me later.
Andrej Karpathy wrote something that every Claude Code user has felt but couldn't articulate.
Three quotes. Read them slowly.
"The models make wrong assumptions on your behalf and just run along with them without checking. They don't manage their confusion, don't seek clarifications, don't surface inconsistencies, don't present tradeoffs, don't push back when they should."
"They really like to overcomplicate code and APIs, bloat abstractions, don't clean up dead code... implement a bloated construction over 1000 lines when 100 would do."
"They still sometimes change/remove comments and code they don't sufficiently understand as side effects, even if orthogonal to the task."
You've seen all three. Probably this week.
Someone turned these three observations into a single CLAUDE[.]md file. Four principles, one install, directly addresses each quote:
1./ Think before coding
Don't assume. Don't hide confusion. State ambiguity explicitly. Present multiple interpretations rather than silently picking one. Push back if a simpler approach exists. Stop and ask rather than guess.
2./ Simplicity first
No features beyond what was asked. No abstractions for single-use code. No "flexibility" that wasn't requested. No error handling for impossible scenarios. The test: would a senior engineer say this is overcomplicated? If yes, rewrite it.
3./ Surgical changes
Don't "improve" adjacent code. Don't refactor things that aren't broken. Match the existing style even if you'd do it differently. If you notice unrelated dead code, mention it, don't delete it. Every changed line should trace directly to the request.
4./ Goal-driven execution
Transform "fix the bug" into "write a test that reproduces it, then make it pass." Transform "add validation" into "write tests for invalid inputs, then make them pass." Give it success criteria and watch it loop until done.
This last one is Karpathy's key insight captured directly: "LLMs are exceptionally good at looping until they meet specific goals... Don't tell it what to do, give it success criteria and watch it go."
It's a single file. Drop it into any project.
MIT professor just revealed the brutal truth about communication:
You’re not ignored because you’re wrong.
You’re ignored because you’re unclear.
In minutes, he shows how to sound sharp, confident, and impossible to ignore.
Miss this—and stay invisible.
This 50 minute lecture from Jeff Bezos in 2005, before AWS, before Kindle, before Prime took over, will teach you more about building revolutionary products than a $150,000 MBA.
Bookmark this & give it 50 minutes today. It’s the most productive thing you can give your morning.
Why am I so hopeful about India’s young, leading India to greatness?
Read this post.
Yesterday, I inaugurated the factory of Arctus, a young startup building unmanned aircraft in Bengaluru.
All the founders, led by Sri Purna, are 2024 graduates from IIT Madras. Not one of them looks a day older than 25. Gen Z. From modest backgrounds. But powered by audacious dreams.
Three things stood out for me at this event.
One, an India where institutions like IIT Madras are not just granting degrees, but enabling ideas to become products, products to become companies, and companies to create wealth. This is the template more universities must adopt.
Two - After the initial incubation in IIT-Madras, they moved to Bengaluru to build their factory. A city with unmatched depth of talent, risk capital, mentorship, and manufacturing capability. This ecosystem is our city’s strategic advantage. We must strengthen it further.
And third and most importantly, an India where government is no longer a gatekeeper, but a partner. Sri Purna shared how agencies like DRDO and ADA, including the Chitradurga testing facility, have actively supported their journey. A decade ago, this would have been unthinkable. PM Modi’s Government is not a regulator. It is a facilitator.
This is the transformation of the last ten years.
This is the legacy of Narendra Modi.
Young Indians who don’t just aspire, but build. Who don’t just dream, but deliver.
It is these founders, these ideas, these risks that will power India to Viksit Bharat.
If you want to see the future of India, don’t look at reports.
Look at these young builders.
That is the power of a confident, resolute India.
Onwards guys, my best wishes.
@arctusaerospace@narendramodi
In 2019, MIT professor Patrick Winston gave a legendary 1-hour lecture called “How to Speak.”
His frameworks:
• Your ideas are like your children
• The 5-minute rule for job talks
• Why jokes fail at the start
BREAKING: Claude can now research like a Stanford PhD student.
Here are 9 insane Claude prompts that turn 40+ research papers into structured literature reviews, knowledge maps, and research gaps in minutes (Save this)
🚨 Professors are going to hate this.
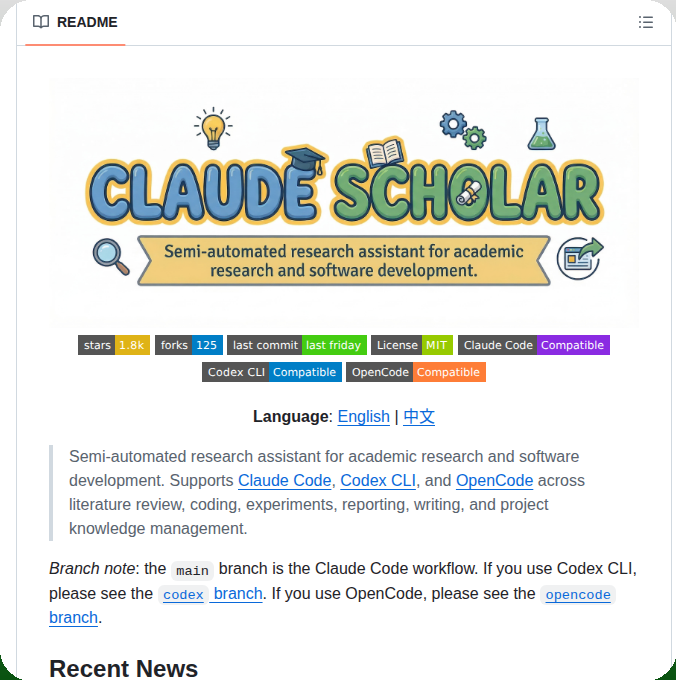
Someone just open sourced an AI that writes research papers from idea to publication. Conference-ready. Citation-verified. Free.
It's called Claude Scholar.
An AI-powered research system that handles every step of the academic workflow. Idea to publication. Fully automated.
No advisor at 2am. No staring at blank LaTeX files. No crying during rebuttal season.
Here's what's inside this thing:
→ AI brainstorms research topics, reviews literature, and finds gaps nobody has explored
→ Runs statistical analysis on your experiments. t-tests, ANOVA, ablation studies. Publication-ready figures.
→ Writes your paper section by section. Abstract to conclusion. Conference-formatted.
→ Verifies every citation through multi-layer validation so AI never hallucinates a reference
→ Strips robotic AI language and adds human voice so reviewers can't tell
→ Self-reviews your draft with a 6-point quality checklist before you submit
→ Parses reviewer comments, classifies each one, and drafts your entire rebuttal
Here's the wildest part:
It supports NeurIPS, ICML, ICLR, ACL, AAAI, Nature, Science, Cell, and PNAS. Downloads the conference template, strips sample content, and gives you a clean LaTeX structure ready to write into.
The creator says it covers 90% of the academic research lifecycle.
Research assistants charge $30 to $60/hour. Conference paper consultants charge $5,000+. Graduate programs cost $50K/year.
This is free. All of it.
100% Open Source.
Karpathy buried the most important part of autoresearch in the README, and almost nobody read it.
Above the installation instructions, he wrote a short fiction piece set in the future. Autonomous swarms of AI agents running across compute cluster megastructures. Generation 10,205 of a self-modifying codebase that has grown beyond human comprehension. No researchers in the loop. Then the last line: "This repo is the story of how it all began."
He's telling you what he thinks he built.
Today the repo is 630 lines of Python. One GPU. One file the agent can edit. 5-minute training runs. 12 experiments per hour. You wake up to a results.tsv and a cleaner git history. Cute.
But Karpathy already posted the roadmap. Step one was the single-agent loop, which is what shipped. Step two is asynchronous collaboration. Thousands of agents running parallel branches on different GPUs, contributing findings back to a shared repo. He compared it to SETI@home. His exact words: "The goal is not to emulate a single PhD student, it's to emulate a research community of them."
Step three is what he described on X as agents promoting the most promising ideas to increasingly larger scales. Small model finds an architectural improvement. Mid-size model validates it. Frontier model absorbs it. A research pipeline where each stage filters signal from noise automatically.
42,000 GitHub stars in a week. 5,800 forks. Community ports running on Mac Minis, RTX cards, 4GB laptops. One user on a GeForce 1050 Ti got it working. The surface area for this swarm already exists. Distributed GPUs sitting idle overnight in every developer's apartment, every university lab, every startup office.
Shopify's CEO ran it on company data overnight and got a 19% gain from 37 experiments. Imagine 10,000 agents running 37 experiments each. 370,000 experiments. The ones that improve get promoted. The ones that fail get reverted. The system remembers everything.
Karpathy spent a decade at the center of AI research. He co-founded OpenAI. He ran AI at Tesla. He coined "vibe coding." When someone with that track record writes a fictional origin story for autonomous AI research and then publishes the first chapter as open source, the fiction is the spec.
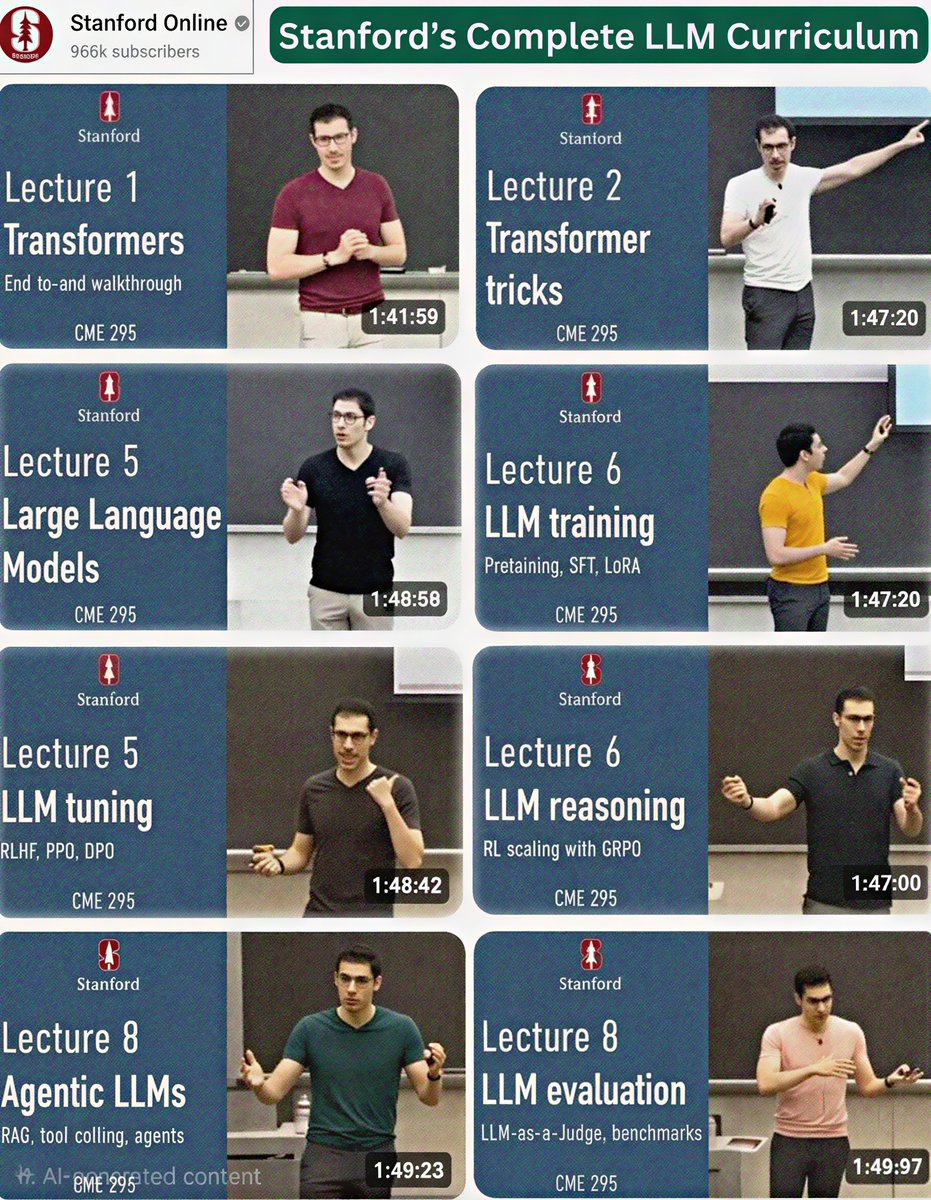
This is insane 😳
Most people are just using AI tools
Very few actually understand how they work
So I collected Stanford’s complete LLM curriculum
and turned it into a step-by-step learning path
Worth over $500
Giving it away free for the first 4,500 people
Transformers → Training → Alignment → Agents → Evaluation
Study this once and you’ll stop guessing with prompts
and start thinking like a real AI engineer
How to get it:
Follow must (so i can dm you)
Rt and comment 'LLM'
🚨 Holy shit...Researchers at HKU just built an AI that does the entire scientific research lifecycle end-to-end and it just got accepted as a Spotlight paper at NeurIPS 2025.
It's called AI-Researcher. Give it some reference papers and it produces a full published-quality academic paper. No human needed in between.
Here's the full pipeline it runs autonomously:
→ Scrapes arXiv, IEEE, ACM, GitHub, and HuggingFace for relevant research
→ Identifies gaps in existing literature and generates novel ideas
→ Designs the algorithm, writes the code, runs the experiments
→ Analyzes results and iteratively refines the approach
→ Writes a complete academic paper with citations, methods, and results
You give it either a detailed idea or just reference papers. It figures out the rest.
It's already been used to produce papers on vector quantization, graph neural networks, recommendation systems, and diffusion models — all with real experimental results.
4.4K stars. 100% Opensource.
Link in comments.
This paper is almost too good that I didn't want to share it
Ignore the OpenClaw clickbait, OPD + RL on real agentic tasks with significant results is very exciting, and moves us away from needing verifiable rewards
Authors: @YinjieW2024 Xuyang Chen, Xialong Jin, @MengdiWang10@LingYang_PU
🚨Someone just open sourced a tool that clones any voice from a 10-second audio clip.
It's called Chatterbox. Give it a short recording of anyone's voice and it will generate new speech in that exact voice. Any words you want.
23 languages. One pip install. Free.
Here's what makes this one different:
→ 350M parameter model. Runs on a single GPU.
→ You can make the cloned voice laugh, cough, chuckle, and sigh
→ Works in English, Japanese, Chinese, Hindi, Arabic, French, and 17 more
→ Built-in watermarking so generated audio can be detected
→ Voice conversion mode turns YOUR voice into someone else's in real-time
Five lines of Python and it's talking:
pip install chatterbox-tts
from chatterbox.tts_turbo import ChatterboxTurboTTS
model = ChatterboxTurboTTS.from_pretrained(device="cuda")
wav = model.generate("Hello world", audio_prompt_path="any_voice.wav")
That's it. That voice now says whatever you type.
21.9K GitHub stars. 2.9K forks. MIT License.
ElevenLabs charges $5 to $99/month for this. Chatterbox does it for free.
100% Open Source.







































![techNmak's tweet photo. Andrej Karpathy wrote something that every Claude Code user has felt but couldn't articulate.
Three quotes. Read them slowly.
"The models make wrong assumptions on your behalf and just run along with them without checking. They don't manage their confusion, don't seek clarifications, don't surface inconsistencies, don't present tradeoffs, don't push back when they should."
"They really like to overcomplicate code and APIs, bloat abstractions, don't clean up dead code... implement a bloated construction over 1000 lines when 100 would do."
"They still sometimes change/remove comments and code they don't sufficiently understand as side effects, even if orthogonal to the task."
You've seen all three. Probably this week.
Someone turned these three observations into a single CLAUDE[.]md file. Four principles, one install, directly addresses each quote:
1./ Think before coding
Don't assume. Don't hide confusion. State ambiguity explicitly. Present multiple interpretations rather than silently picking one. Push back if a simpler approach exists. Stop and ask rather than guess.
2./ Simplicity first
No features beyond what was asked. No abstractions for single-use code. No "flexibility" that wasn't requested. No error handling for impossible scenarios. The test: would a senior engineer say this is overcomplicated? If yes, rewrite it.
3./ Surgical changes
Don't "improve" adjacent code. Don't refactor things that aren't broken. Match the existing style even if you'd do it differently. If you notice unrelated dead code, mention it, don't delete it. Every changed line should trace directly to the request.
4./ Goal-driven execution
Transform "fix the bug" into "write a test that reproduces it, then make it pass." Transform "add validation" into "write tests for invalid inputs, then make them pass." Give it success criteria and watch it loop until done.
This last one is Karpathy's key insight captured directly: "LLMs are exceptionally good at looping until they meet specific goals... Don't tell it what to do, give it success criteria and watch it go."
It's a single file. Drop it into any project.](https://pbs.twimg.com/media/HFxpgTJbYAA1sT-.jpg)


![KirkDBorne's tweet photo. Introduction to Graph Neural Networks — A Starting Point for Machine Learning Engineers: https://t.co/Qqo6MLXXSe [49-page PDF]
#AI #ML #DeepLearning #DataScience #DataScientist https://t.co/pen1vIxYIY](https://pbs.twimg.com/media/HEMzyNTbEAAHL68.jpg)






















