@vadym_petryshyn It did it in the sandbox. The screen shots show the initial struggle looking for data locally but the need is in the sandbox, the realisation for uploading - ultimately it does everything in the sandbox - messages[] confirm this.
Day 65: #BuildInPublic#AdaptiveAgent#AI
GAIA Benchmark exposed the sandbox tool in AdaptiveAgent - repeated creation of sandbox instead of persisting the sandbox over the run. The sandbox is not persistent over the run with failsafe closure - here is a test result
Day 64 #AdaptiveAgent#BuildInPublic#AI
Early morning runs, listening to @latentspacepod podcast triggered a idea on Agent swarm! built it using @ampcode ,which is flawless. I am now running GAIA benchmark - multiple agents in parallel
Day 63: #BuildInpublic#AdaptiveAgent#AI
On one retry - if found agent in infinite search loop. The agent was made aware of this via a /steer command and it corrected itself and finally completed the task - answer was wrong but a good guess.
Day 63: #BuildInpublic#AdaptiveAgent#AI
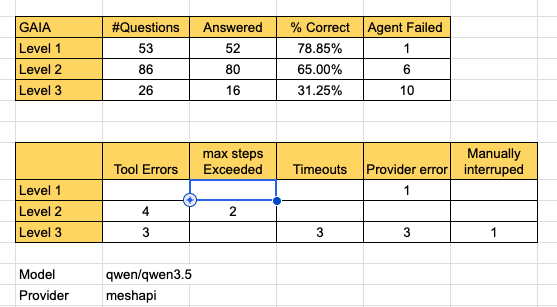
Tests using GAIA validation set continues - Yesterday was the first time I was able to test all 3 levels - scores are improving but there work to do - see overall scores and failure analysis
Day 63: #BuildInpublic#AdaptiveAgent#AI
Retrying failed runs : Further analysis revealed that the agent is tenacious at search (duckduckgo), results being poor it tries again and again and fails on MAX_STEPS which is 80 for the agent
Jensen Huang says the AI PC reinvention is as big as the smartphone shift by calling it “a new line” and “a new beginning.”
$NVDA and $MSFT unveiled RTX Spark which will be the world’s most powerful deskside AI supercomputer built to run next-gen AI agent workloads locally.
Day 62: #BuildInPublic#AdaptiveAgent#AI
I was 90% done on Day 30. Testing and refinements seem endless. It somehow feels I am half way! reminds me of @JamesClear one of 3 ideas posted week before last
Day 56 : #BuildInPublic#AdaptiveAgent#AI
Used adaptiveAgent feedback to improve tools(item 1 ) and search optimisation(item 3)
GAIA Benchmark scores improved from 62% -> 71%
on validation set. hard failures are limited to modality and 'maxsteps' exceeded for some tasks. The latter should improve by smarter search and system prompt improvements
3/n #BuildingPublic#AdaptiveAgent#AI
next steps : Improve tools and routing
- add ability to read .parquet files
- be smarter at web search - don't just look for latest stuff
- modality based agent routing
1/n Day 55 : #BuildInPublic#AdaptiveAgent#AI
Struggling to improve GAIA benchmark and getting there slowly. Analysis of failure move from manual to adaptiveAgent driven analysis - structured output has enabled this. Past results : https://t.co/KIFByzd61x
2/n Day 49: #AdaptiveAgent#BuildInPublic#AI
https://t.co/rCoL3nnNAS
Did dry runs, using validation set of 53 questions with two model on @meshapi_ai as provider
1. qwen/qwen3.5-27b - got 50% right
2. gpt-4o-min - got 19% right
2/n Day 55: #BuildInPublic#AdaptiveAgent#AI
GAIA Benchmark : 50% -> 62% improved a bit
12 were hard failures - Tool issues
8 were wrong answers
Insights by adaptiveAgent on its own performance
@JacobSobolev@meshapi_ai My goal is make it point to the shortcoming of the Agents. So far it has been useful in pointing them out.
Poor scores, i am sure is reflection of the agent's inability to do certain things.
1/n Day 49: #AdaptiveAgent#BuildInPublic#AI
Last couple days has been hard, Agentic runs were failing, subtle issues surface as you push the boundaries. Got the testing infrastructure in place to do GAIA benchmark for AdaptiveAgent
![murthyug's tweet photo. @vadym_petryshyn It did it in the sandbox. The screen shots show the initial struggle looking for data locally but the need is in the sandbox, the realisation for uploading - ultimately it does everything in the sandbox - messages[] confirm this. https://t.co/QrQk50QlPw](https://pbs.twimg.com/media/HJ8sNPCaEAA8Sln.jpg)





















![murthyug's tweet photo. @vadym_petryshyn It did it in the sandbox. The screen shots show the initial struggle looking for data locally but the need is in the sandbox, the realisation for uploading - ultimately it does everything in the sandbox - messages[] confirm this. https://t.co/QrQk50QlPw](https://pbs.twimg.com/media/HJ8sOZpbMAAXKBA.jpg)