The MVAPICH family delivers the best performance and scalability for HPC and AI applications on HPC systems with InfiniBand, Omni-Path, HSE/RoCE/iWARP, and more
We are pleased to announce a set of student (MS/PhD) and early career (post-doc and research staff) travel grants available for the annual @mvapich User Group (MUG) Conference!
Dates: Aug. 17-19, 2026
Location: Columbus, OH, USA
Info link: https://t.co/vbRlB8SVUX
Apply now!
Attending #ISC26? Several folks from the @mvapich team will be attending. Be sure to check out our papers on enhanced #MPI intra-node communication, multi-rail #GPU collective algorithms on @nvidia and @AMD GPUs, work on efficient #NVLink usage, and work on AMD #MI300A APUs
📢 Deadline Extended: IEEE Hot Interconnects (HotI) 2026 Call for Tutorials — Proposals Now Due June 12, 2026!
There's still time to submit your tutorial proposal for IEEE Hot Interconnects (HotI) 2026!
HotI 2026 will take place virtually from August 19–21, 2026, with tutorials held on August 21, 2026.
We invite proposals for half-day and full-day tutorials exploring the technologies, systems, and design choices shaping modern interconnects across long, short, and ultra-short distances.
Topics may include:
🔹 AI/ML networking
🔹 Data center interconnects
🔹 Optical fabrics
🔹 Chiplet and accelerator interconnects
🔹 Congestion management
🔹 SDN and overlays
🔹 Traffic characterization
🔹 Fault tolerance
🔹 High-bandwidth, low-latency I/O
Hands-on segments are strongly encouraged to make tutorials more engaging and practical.
🗓 Updated Key Dates
• Proposal Deadline (Extended): June 12, 2026
• Notification of Acceptance: June 19, 2026
• Materials Due: July 31, 2026
Submissions are handled through EasyChair: https://t.co/LA6kZd7Cu9
We look forward to receiving your tutorial proposals and seeing you at HotI 2026! 🚀
👉 Full Call for Tutorials: https://t.co/XLRDmOBOnd
📩 Questions: [email protected]
#hoti #hoti26 @ComputerSociety
Earlier today at @IPDPS: @mvapich member Goutham Kuncham presented his work at the Best Paper Finalkst session, focusing on understanding the memory paths available on the @AMD#MI300A APU architecture for #MPI, #HPC, and #DL applications!
Back to back sessions from @IPDPS 2026 2 of the 3 papers from the @mvapich team today! Lab members Chen-Chun and Jinghan both discussed optimizations on #GPU-aware communication for #HPC and #AI programs on modern #supercomputers!!
@mvapich team member Jinghan Yao is at @MLSysConf '26 presenting his work "MAC-Attention," which focuses on improved #KVCache performance and #scalability for #LLM#attention methods! Catch him there later presenting his paper! Details here: https://t.co/YA2BHVIfOC
Attending @IPDPS in New Orleans? The @mvapich team is presenting three papers centered on #GPU-aware communication on @AMD and @nvidia GPUs, with one being a best paper finalist; and two tutorials! Check out the IPDPS '26 schedule here: https://t.co/0yhtnItAyi
See you there!!
The @mvapich team is excited to announce the GA release of MVAPICH-Plus 5.0!! This release features new algorithms for Alltoall operations, enhanced GPU-based Compression, and continued compliance with the MPI 5.0 standard. Check it out at https://t.co/0I6yWrOB1a!!
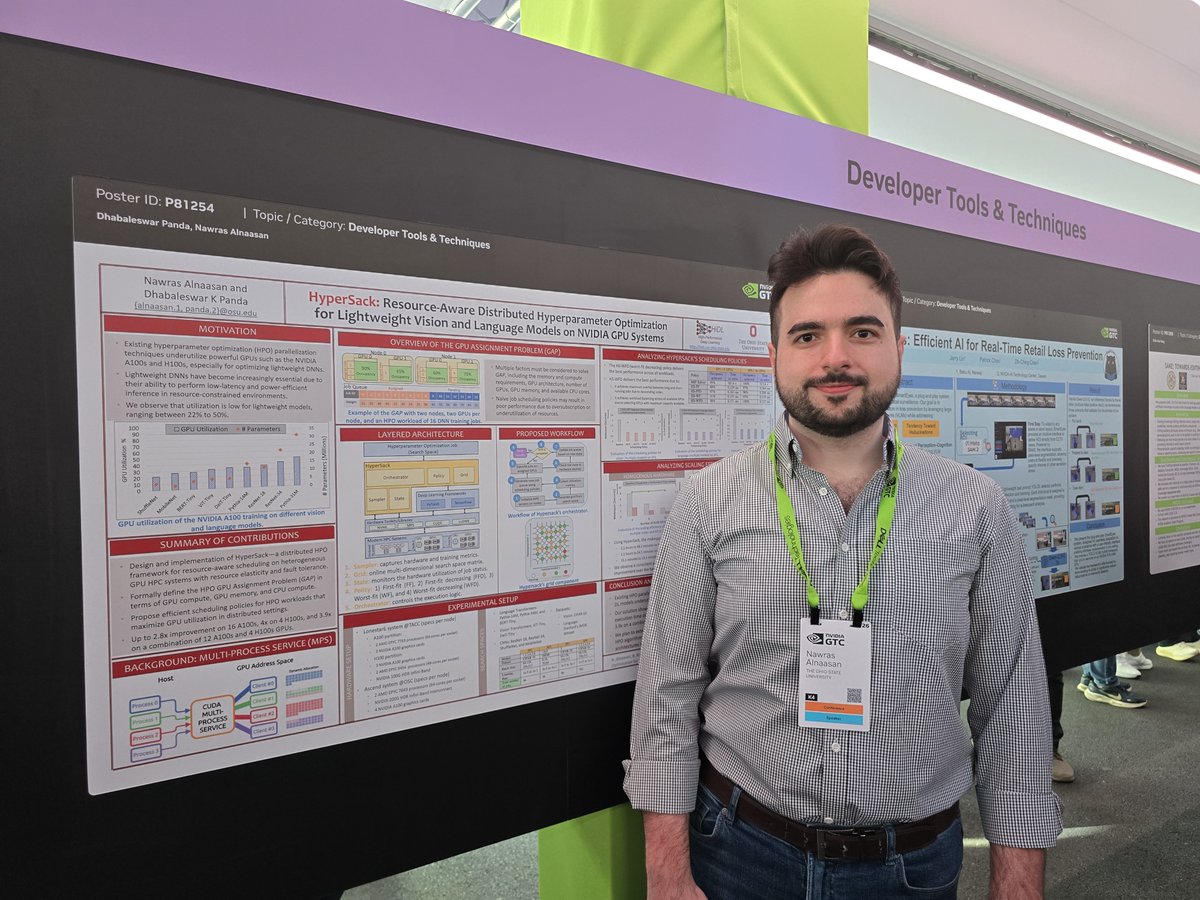
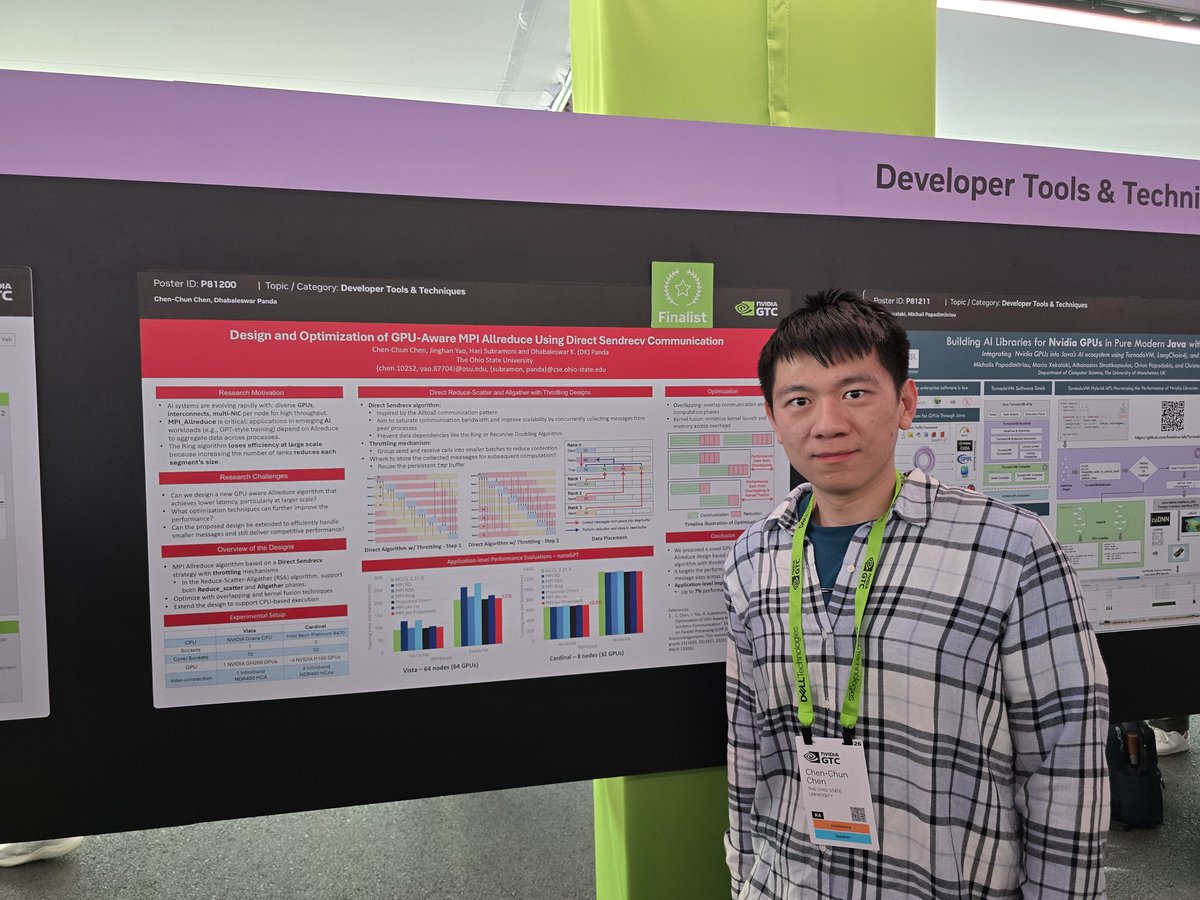
@mvapich is at @NVIDIAGTC 2026 with posters focusing on #LLM inference, enhanced #GPU-Aware #MPI optimizations, and Vision #AI models. Major congratulations to our PhD Student Chen-Chun Chen for being nominated as one of the best poster finalists at #NVIDIAGTC this year!
We are proud to announce that the @mvapich#MPI library has hit over 2 million downloads!! We are so thankful for everyone who has helped develop, design, and optimize the library for #HPC, #AI, and #BigData solutions over the past 25 years!
We are back again at #HiPC25!! Aside from some upcoming paper and poster presentations, we have @mvapich lab leader DK Panda at the Workshop on High Performance Fabrics! Hope to see folks around!
#MPI#MVAPICH#HPC#AI
The final day of #SC25 featured a paper presented by @mvapich member, PhD Student Goutham Kuncham, showcasing a characterization of #MPI on @AMD 's new MI300A #APU products for #HPC and #AI. Many thanks to @SDSC_UCSD for letting us use their COSMOS system for experiments!!
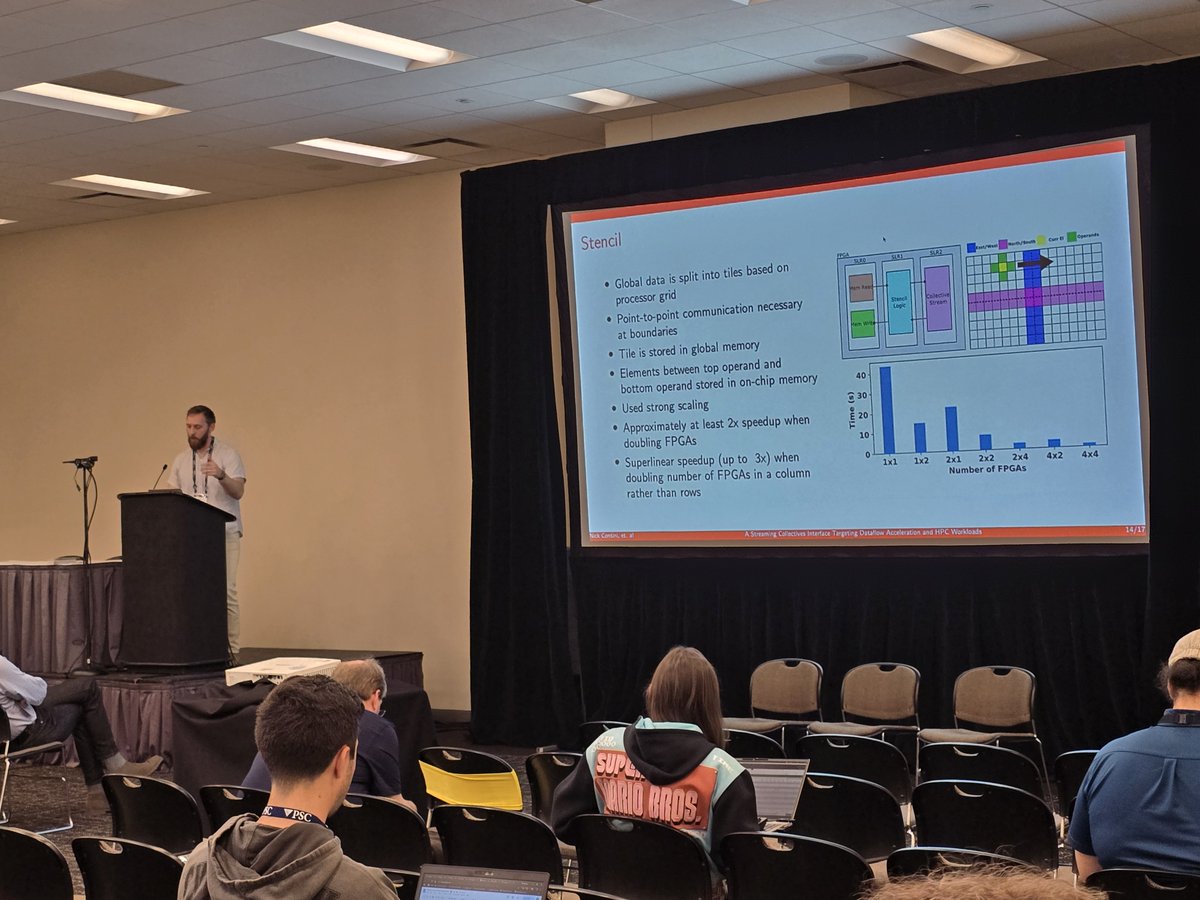
Wrapping up the last two days of #SC25 last week, we start off with a paper presented by @mvapich team member, PhD Student Nick Contini, on Streaming Collective Frameworks in #HPC for #Dataflow/#FPGA architectures! See the paper here: https://t.co/EKCWueASm7
Kicking off our last day of @mvapich#SC25 talks is Dr. John Cazes and Dr. Amit Ruhela of @TACC with their upcoming #HPC#Supercomputer Horizon and some performance numbers! Stop by booth 414!
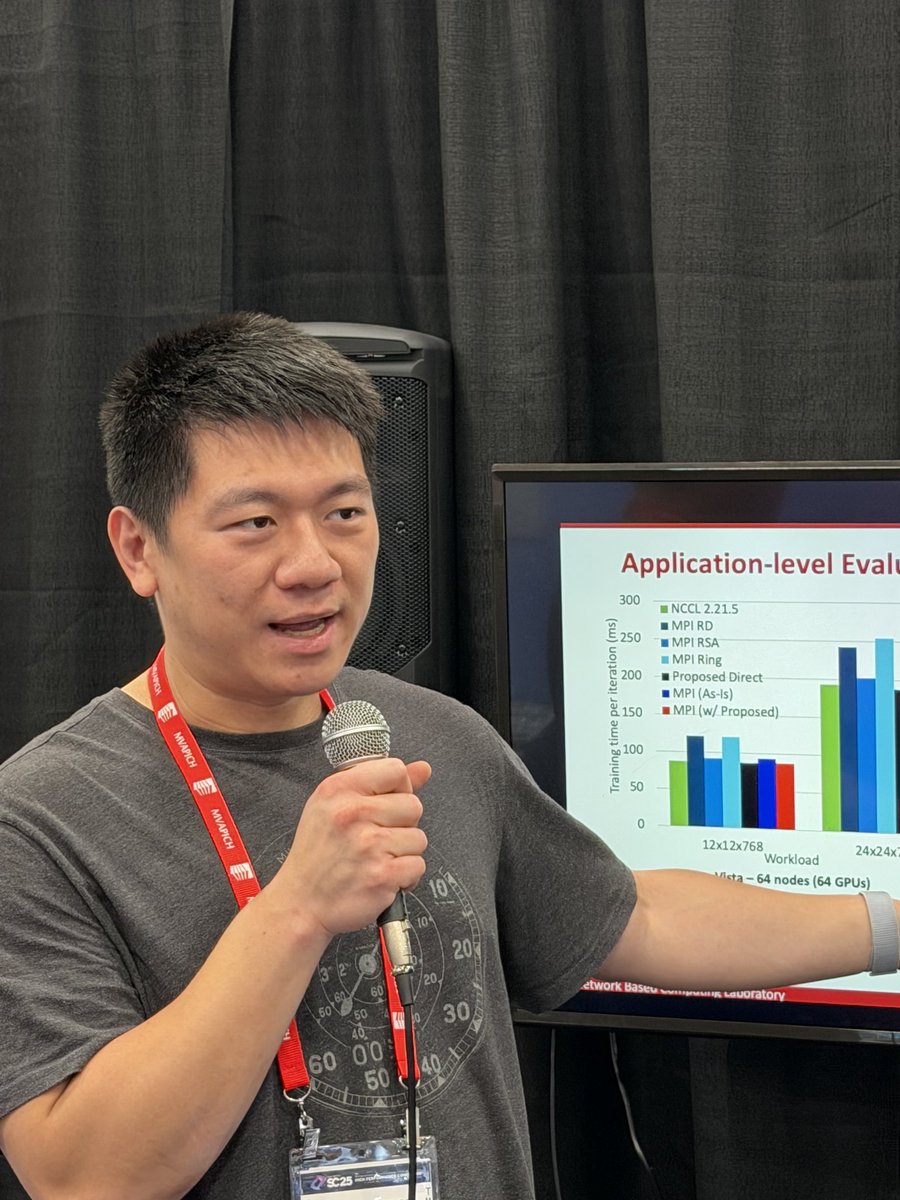
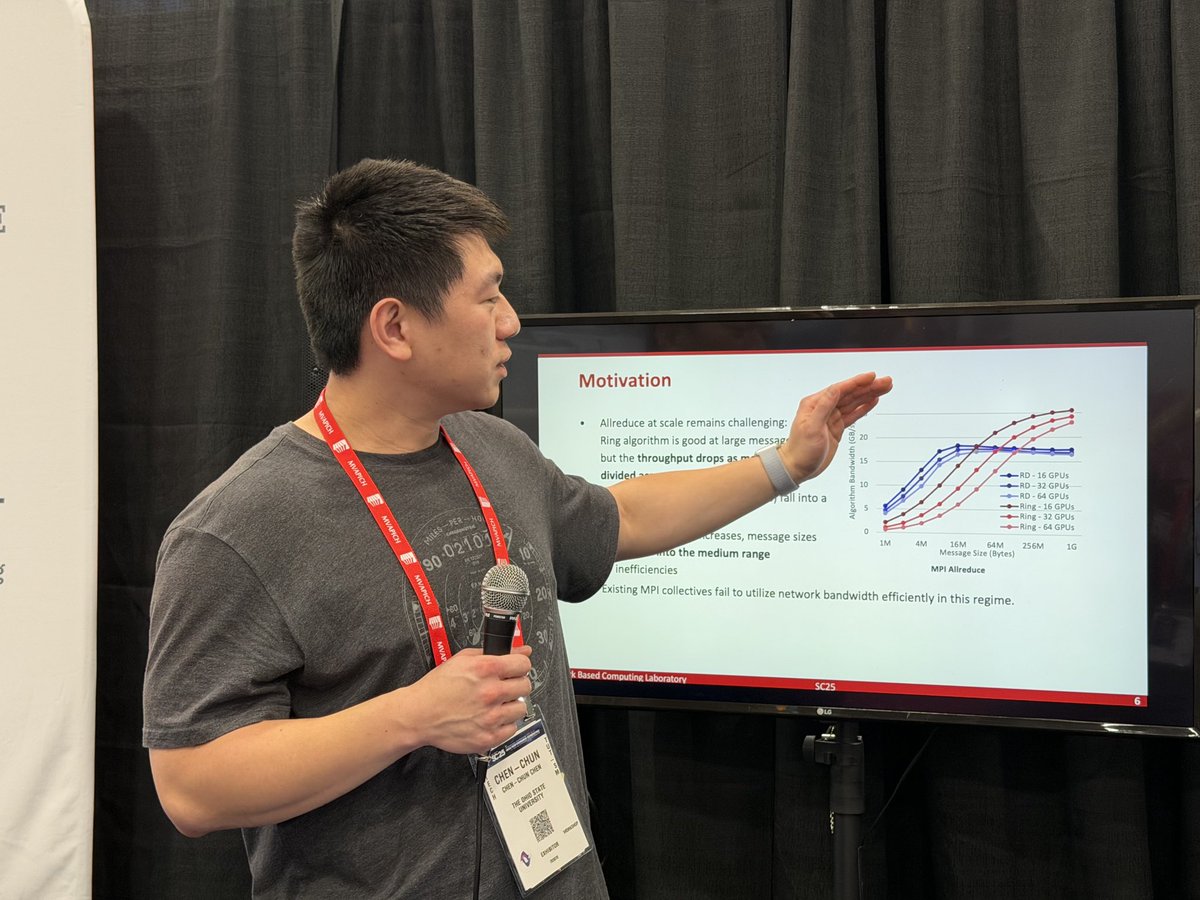
In another one of our student talks, @mvapich lab member Chen-Chun Chen presents new #GPU-enable #MPI results for collectives used commonly in #HPC and #AI workloads! We have plenty more exciting talks coming tomorrow to wrap up #SC25 on a high(-performance) note!
Dr. Soham Ghosh of X-ScaleSolutions returns to the @mvapich#SC25 booth to present the company's products and commercial support for #HPC and #AI users and researchers alike!!