NADDOD is a professional provider of innovative optical networking solutions to AI/HPC, Data Center, Enterprise/Telecom Networking customers!
Tel:+65 6018 4212
Efficient high-density fiber management starts with proper hardware setup. If you are planning your next rack deployment, here is a straightforward visual look at the physical installation of the NADDOD FEN-1U4SD 1U Rack Mount Enclosure.
📺https://t.co/UBz1Rm9nfe
#AI#RackMount
This article explores the most common causes of #opticalmodule failures, including #ESD damage, fiber contamination, overheating, and compatibility issues, along with practical protection measures to improve #networkreliability.🤔
https://t.co/0VyQ13lC63
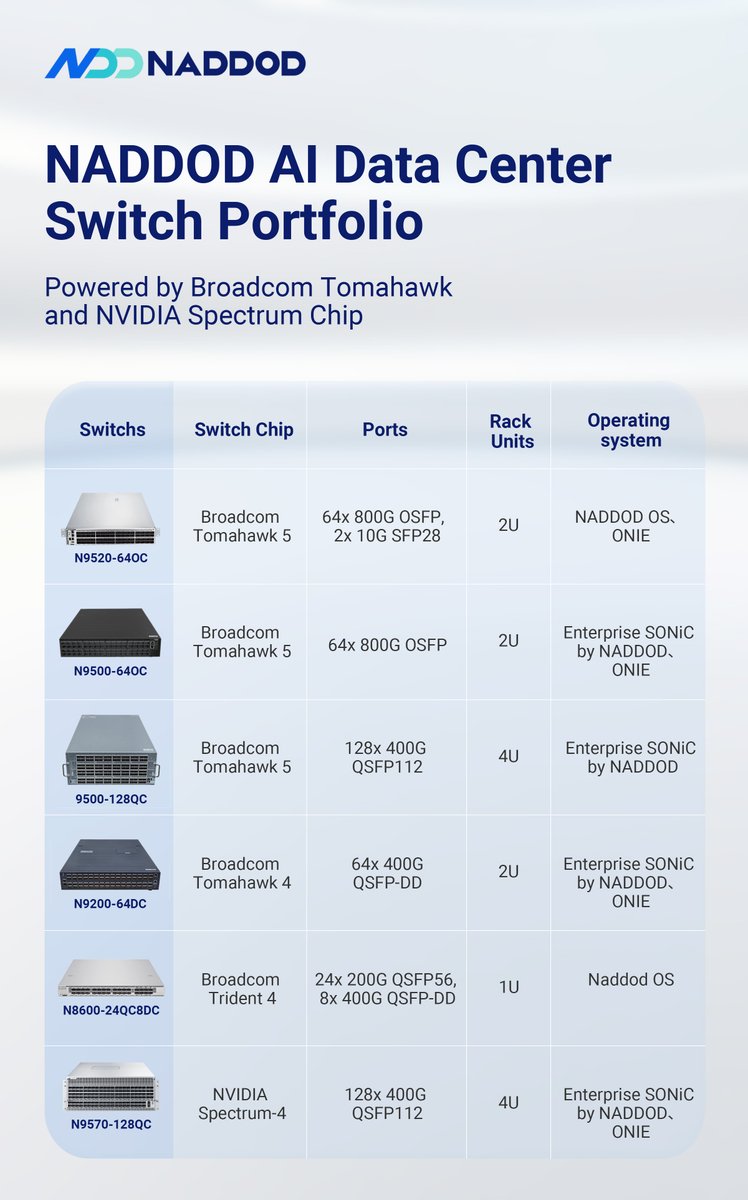
NADDOD remains able to supply #Tomahawk5 AI data center #switches for high-performance #AI networking deployments despite ongoing market shortages.
⏳Contact NADDOD now:
N9520-64OC:https://t.co/9OpMhmxVLW
N9500-64OC:https://t.co/bqWKIKpKpk
N9500-128QC:https://t.co/qhwo0IPyqc
Still confused about MTP®/MPO jumper, harness, and trunk cables? 🤔
Understanding the differences between these cable types can help simplify future upgrades and improve cable management.
Read more: https://t.co/caaB1nQJr7
Buying #InfiniBand products isn’t just about choosing a part number. This guide breaks down what actually matters when selecting high-quality InfiniBand networking products for #AI data centers and #HPC deployments.
Read more: https://t.co/SN2uypOoez
#Networking#NVIDIA
As data center networks scale toward 400G, 800G, and beyond, the way organizations source optical transceivers is evolving. More customers are no longer limiting their options to branded #OEM#optics. Why? This decision guide breaks down the key drivers: https://t.co/M22aeWFEcf
As #AI workloads scale, interconnect choices directly impact latency, throughput, and overall system efficiency. But how do you choose between #DAC, #AOC, and #optical transceivers?
👉https://t.co/r8oBAw4War
Scaling #AIInference at scale isn't just about compute—it's about beating memory bottlenecks and latency spikes. 🚀
⚡️ Discover how to solve these infrastructure hurdles for faster, more reliable AI deployments.
https://t.co/DOQruBQNvB
#AIInfrastructure#Networking
Optimizing #AI inference workloads is no longer just about adding more compute.
To reduce latency, sustain throughput, and control long-term costs, network architecture and interconnect choices matter just as much.
👉 : https://t.co/hY3WPkK3z3
How do you evaluate the stability of a high-quality #InfiniBand product? 🔥 Three things to look at:
✅ Sustained full-load stability
✅ Consistent high-load performance
✅ Fast and reliable link recovery
📺Watch the video for details:https://t.co/rCXLWDMhPq
#NVIDIA#800G
Speed matters. And network performance is no longer just infrastructure—it directly impacts your workflow.
High-bandwidth, low-latency interconnects like 800G are key to unlocking real-time inference at scale.
Great setup!👍
The lack of inference speed is what's killing your agentic workflows.
Multi-step agentic tasks stall the moment a single call lags.
Here is how I'm removing that bottleneck:
The ConnectX-8 SuperNICs with QSFP112 ports and 800Gb DAC cables finally arrived at my builder's shop today. This creates a direct 800Gbps link between my Threadripper 9985 (64C/128T) to the "secret machine" housing my AI models.
My agents live on the Threadripper.
When they ask, the models answer at the speed of thought. Every inference call moves between them at 800 gigabits with zero middlemen and no cloud dependency.
For agentic systems to scale and perform, this is a component every developer and vibe coder should aim for.
Yes speed matters.
@nvidia@naddodnetwork
The lack of inference speed is what's killing your agentic workflows.
Multi-step agentic tasks stall the moment a single call lags.
Here is how I'm removing that bottleneck:
The ConnectX-8 SuperNICs with QSFP112 ports and 800Gb DAC cables finally arrived at my builder's shop today. This creates a direct 800Gbps link between my Threadripper 9985 (64C/128T) to the "secret machine" housing my AI models.
My agents live on the Threadripper.
When they ask, the models answer at the speed of thought. Every inference call moves between them at 800 gigabits with zero middlemen and no cloud dependency.
For agentic systems to scale and perform, this is a component every developer and vibe coder should aim for.
Yes speed matters.
@nvidia@naddodnetwork
#PrefixCaching makes LLM inference more efficient by reusing #KVcache across requests 📷 Compared to standard KV caching, it reduces latency and compute—ideal for multi-turn chat, RAG, and few-shot learning. #LLM#AI#RAG#Inference
🔗:https://t.co/XAAsG60jlk
⚡#NADDOD now offers 128 & 256 Fibers #Shuffle#Cables, designed for high-density, multi-plane data center interconnects.
S2MPOA128M2:https://t.co/ZekzMdHfgX
M4MPOA128M2:https://t.co/JSSZYUGfAL
S2MPOA256M4:https://t.co/vI3wnnQtNY
M4MPOA256M4:https://t.co/JSpGSJGNq7
⚡What is an #XPO transceiver, and how does it compare to #CPO?
XPO redefines pluggable optics with higher bandwidth density, 50V power architecture, and module-level liquid cooling—while maintaining serviceability. ⚙️
Read more:https://t.co/TsqHgiFFis
#AI#NVIDIA#NADDOD
In NVIDIA GTC keynote, Jensen Huang made one trend clear: the AI inference era is scaling rapidly—closely aligning with NADDOD’s roadmap.
With deep industry insight, we continue to deliver cutting-edge, high-performance networking products and end-to-end AI network solutions.
⚡ NVIDIA Groq 3 LPX: Low-latency inference for the Vera Rubin platform. GPU + LPU architecture delivers high throughput and predictable latency for large models, powering intelligent agents and next-gen AI. 🚀
🔗:https://t.co/bWgB8zyl7m
🚀 #NVIDIA#MGX ecosystem—a modular, high-density AI infrastructure designed for large-scale training and inference.
👉 https://t.co/jSEFZTkYgH
#MGXecosystem#GTC2026