I've been thinking about why verifying AI agent output feels so much harder than writing the spec that produced it. That question led me to rethink where my attention actually belongs in the process, and eventually to build https://t.co/TpxaTqqqag https://t.co/UBbhJaFkFH
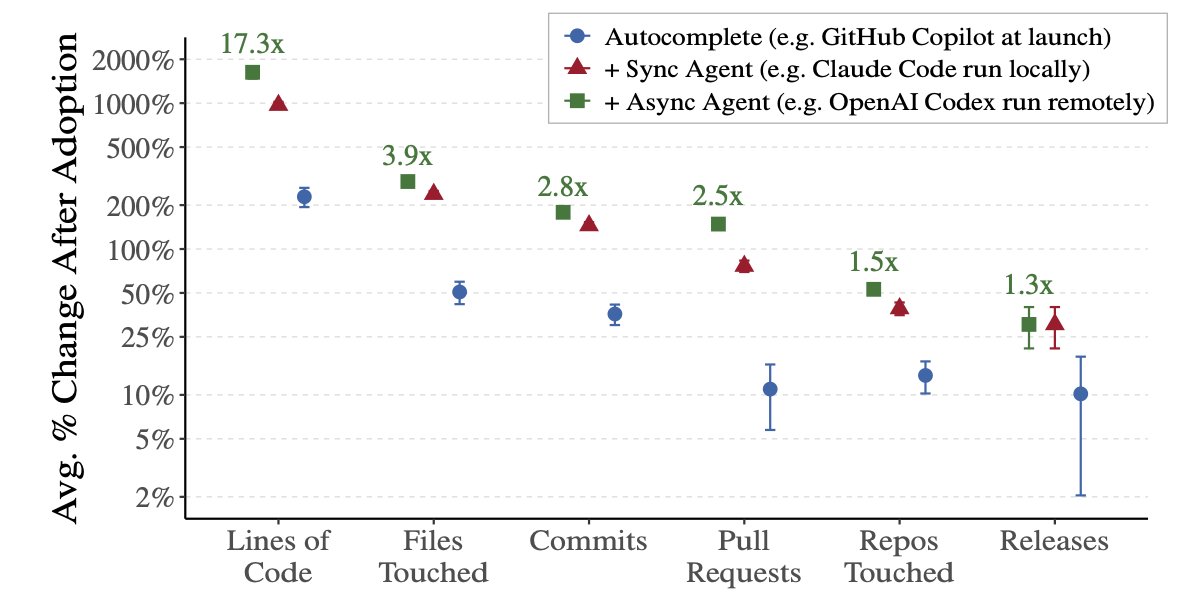
Big paper on AI coding agents using Github & other data
The auto-complete tools (Copilot) led to 2.2x more code, local agents like original Claude Code led to 7.4x, & current remote coding agents 17.3x(!)
But human bottlenecks in coding means actual releases "only" went up 30%
@tanishqk I've been thinking about this as well. But I've found that agents aren't great at divergent thinking. Without human guidance they revert to the safest, most generic options. In my experience, the human input has the most leverage at the beginning of each diamond.
This is how I use AI to augment my design process. Instead of having the agent show me a giant diff of changes, Atelier links each edit back to the original thread of feedback so I can review them in context
@Westoncb@mrtudl I suspect the RL training loop rewards solving the task in as few steps as possible and that discourages the agent from searching for additional constraints
@Westoncb@mrtudl Also hedge your questions. Instead of just "should I refactor this to a shared lib?" add "... or would that make it too strongly coupled?" so it has to weigh both sides
We desperately need better ways of evaluating models. Something that shows how helpful they are at working hand-in-hand with humans to help them get stuff done in a cooperative/iterative way.
The Claude models have consistently been better at this, and the market rewards that.
@Westoncb This was my first attempt at it last year: https://t.co/QFwaPkVQDz but I've been thinking a lot about it since then and I'm hoping to come back to that problem again
@Westoncb Totally agree. Deliberately delegating parts of the task to parallel subagents is a really powerful technique. I wrote up some similar ideas here: https://t.co/XBxiYRzBx0
This is how I use AI to augment my design process. Instead of having the agent show me a giant diff of changes, Atelier links each edit back to the original thread of feedback so I can review them in context
What are users thinking during their interactions with LLMs?
We introduce ThoughtTrace — the first large-scale dataset that captures what users think during real-world human–AI conversations, not just what they type.
→ 10,174 thought annotations
→ 2,155 multi-turn conversations, 17,058 turns
→ 1,058 users
→ 20 LLMs
These thoughts improve user behavior prediction (+41.7%) and model alignment (+25.6%).
This opens a new paradigm of user-centric LLM research. Full information in the thread 🧶
Read our paper: https://t.co/lRYJvGJ7bb
Check our project website: https://t.co/AupCn1YQOk
This is how I use AI to augment my design process. Instead of having the agent show me a giant diff of changes, Atelier links each edit back to the original thread of feedback so I can review them in context
I always found it hard to document large codebases in a way that made sense to me visually
Thanks to @tldraw I built CodeCanvas, my own infinite canvas documentation tool for mapping out my thought process
Excited to share some of my favorite features