introducing tau τ — an educational agent harness that teaches you how to build agent harnesses
i will be publishing tutorials and demos on how to use it to create your own TUIs, harnesses, extensions, etc.
Happy Tau Day!! 🤓
👉 https://t.co/5sWxNtXTZP
This has quietly been a miracle month in medicine.
In the last 5 weeks we’ve got news on:
- retatrutide, the triple agonist GLP-1 from Lilly, basically melting fat and body-wide inflammation at record levels
- RevMed’s new pancreatic cancer drug showing unprecedented abilities to extend life
- small trial of a one-and-done PCSK9 gene editing therapy for slashing LDL cholesterol
- Mayo’s AI-assisted radiology showing vastly improved cancer detection
- this new therapy for metastatic solid tumors
This stuff is at varying levels of evidence. Retatrutide is ~100% on its way, other stuff needs more clinical trial data. But put it together and we’re maybe on the verge of majorly reducing the mortality of heart disease and cancer, the two leading causes of death in America.
Claude Code Dynamic Workflows, explained!
Anthropic dropped Opus 4.8, and everyone is talking about the benchmarks, the honesty improvements, and the cheaper fast mode.
But the feature that shipped alongside it might matter more for how we actually build: Dynamic Workflows in Claude Code.
Here's what they are, how they differ from subagents and agent teams (which already existed), and why they change the game for large-scale agentic coding.
𝗪𝗵𝗮𝘁 𝗮𝗿𝗲 𝗗𝘆𝗻𝗮𝗺𝗶𝗰 𝗪𝗼𝗿𝗸𝗳𝗹𝗼𝘄𝘀?
Claude Code already had two multi-agent primitives before this release.
Subagents are lightweight workers spawned from a main session. They do a focused task and report back. But they can't talk to each other, and the main agent still acts as the bottleneck for orchestration. Every result routes through one context window.
Agent Teams (shipped with Opus 4.6) removed that constraint. Multiple Claude instances coordinate through a shared task list and message each other directly. But they top out at 3-5 teammates practically, sessions don't survive interruptions (if Claude crashes mid-task, the team is gone), and you still need to design the orchestration upfront.
(I published an article on both of the above; it's quoted below)
Dynamic Workflows sit above both.
Instead of Claude holding the plan in its context window, it writes a JavaScript orchestration script. That script becomes the plan. A JS runtime executes it, fanning work across tens to hundreds of parallel subagents automatically.
You describe the task. Claude decides how to split it, how many agents to spawn, how to verify results, and what to report back. The orchestration logic moves from the LLM's memory into executable code.
Claude's context window only ever sees the final converged answer. Not the intermediate results of hundreds of steps.
𝗪𝗵𝘆 𝘁𝗵𝗶𝘀 𝗺𝗮𝘁𝘁𝗲𝗿𝘀
→ 𝗦𝗰𝗮𝗹𝗲. Up to 16 concurrent agents, 1,000 total per workflow. Subagents max out at a handful. Agent Teams get messy past 5.
→ 𝗔𝗱𝘃𝗲𝗿𝘀𝗮𝗿𝗶𝗮𝗹 𝘃𝗲𝗿𝗶𝗳𝗶𝗰𝗮𝘁𝗶𝗼𝗻. Agents tackle a problem from independent angles, other agents try to refute their findings, and the system iterates until answers converge. Subagents just report back. Agent Teams collaborate but don't adversarially verify.
→ 𝗥𝗲𝘀𝘂𝗺𝗮𝗯𝗶𝗹𝗶𝘁𝘆. Progress saves continuously. Interrupted jobs pick up where they left off. Agent Teams die with the session.
→ 𝗭𝗲𝗿𝗼 𝗼𝗿𝗰𝗵𝗲𝘀𝘁𝗿𝗮𝘁𝗶𝗼𝗻 𝗯𝘂𝗿𝗱𝗲𝗻. You describe the goal. Claude decides how to split work, how many agents to spawn, and how to verify results.
𝗕𝗲𝘀𝘁 𝗽𝗿𝗮𝗰𝘁𝗶𝗰𝗲𝘀
→ Start with a scoped task to calibrate token usage before going full-scale. Workflows consume significantly more tokens than a typical session.
→ Enable auto mode so Claude decides when a workflow is appropriate vs. when a simpler approach works.
→ Use the `ultracode` setting (effort menu) to let Claude auto-trigger workflows. This also sets reasoning to `xhigh`.
→ Review the execution plan on first trigger. A poorly scoped prompt will fan out agents unnecessarily.
→ Enterprise plans have workflows off by default. An admin needs to enable them.
Available today in research preview on Max, Team, and Enterprise plans.
The article on Subagents and Agent teams is quoted below.
Most people don't know what an LLM actually is.
They know how to use ChatGPT. But they have no idea what's underneath.
That matters — because not knowing what a tool can't do is more dangerous than not knowing how to use it.
I wrote a guide. No jargon.
[link in reply]
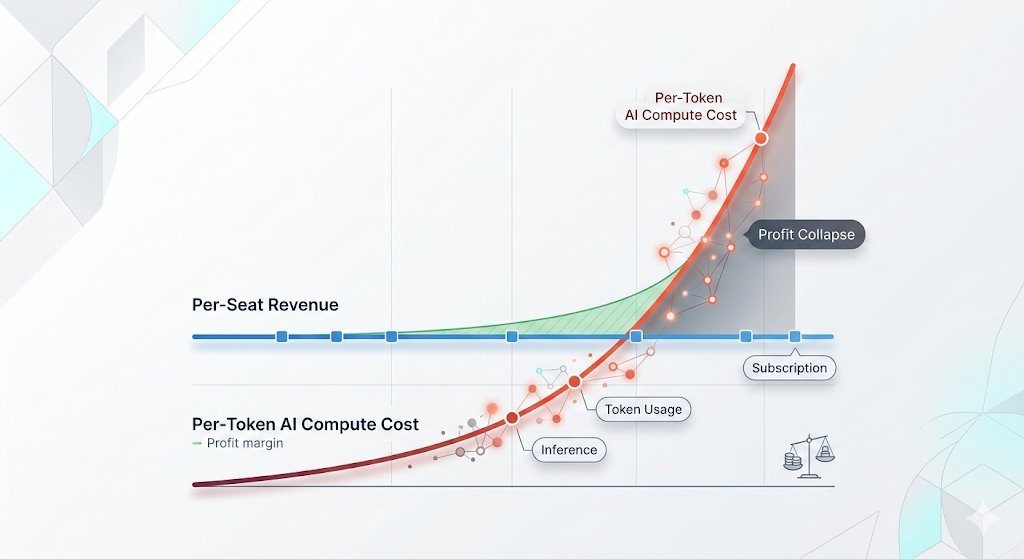
🦔Microsoft canceled its internal Claude Code licenses this week after token-based billing made the cost untenable, even for a company with effectively infinite cloud resources. Uber's CTO sent an internal memo warning the company burned through its entire 2026 AI budget in just four months. American AI software prices have jumped 20% to 37%, and GitHub (owned by Microsoft) is dropping flat-rate plans for usage-based billing across its products.
My Take
The AI subsidy era is ending in real time. The same company that put $13 billion into OpenAI and built the Azure infrastructure powering most of Anthropic's compute just looked at the bill from a competitor's coding tool and decided it was not worth paying. That is not a productivity failure on Anthropic's end. Token-based pricing is forcing every enterprise customer to confront the actual cost of running these models at scale, and the number turns out to be far higher than the flat-rate experiments suggested.
This ties directly to my Gemini Flash post yesterday. Anthropic, OpenAI, and Google all raised effective prices in the last six months. Enterprises that built workflows assuming AI costs would keep falling are now watching annual budgets evaporate in months. Two outcomes look likely from here. Either enterprises scale back AI usage to fit budgets, which slows the revenue ramp the labs need to justify their valuations ahead of IPOs, or the labs cut prices and absorb the losses, which makes the unit economics worse at exactly the wrong moment. Both paths land in the same place, the numbers stop working, and somebody has to take the writedown.
Hedgie🤗
@fchollet Apps can be just MCP servers or similar. Plug them to whatever harness you prefer. And ask your harness to show you the data the way you like. Why stick to the ui someone else defined?
Not much yet, but it was a good first test in fine-tunning a model, just to try the process.
6 hours with just CPU for a dataset with only 500 pairs.
Anyone wanna donate me a GPU? 🤣
model: https://t.co/9IzV4kSauG
dataset: https://t.co/qNCWQ0XgK7
@huggingface#huggingface