Nextstrain is happy to announce a major update to our tuberculosis analysis, making it our first real-time (continually updated) analysis for a bacterial pathogen. Please see our new blog post for details:
https://t.co/Rb7ccpIuRh
On Oct 1, 2025, @GISAID informed us that they had ended updates to the flat file of SARS-CoV-2 genomic sequences and associated metadata that we had used to update Nextstrain analyses since Feb 2020. GISAID's stated rationale was that their "resources are limited". 1/5
Closing these public analyses puts the world more in the dark and concretely harms surveillance as it becomes more difficult for variant spotters to contribute to global situational awareness. 4/5
@0bFuSc8@USDA_APHIS @LouiseHMoncla @RajlabN Thanks to quick work by Karthik G and Praneeth G to update SRA assemblies at https://t.co/CdYVPrvDNP, we now have house mouse sequences up at the live site at https://t.co/tWllyUAUTg
@0bFuSc8@USDA_APHIS @LouiseHMoncla @RajlabN Thanks for the pointer! It looks like these 4 sequences are in a separate USDA BioProject (https://t.co/vjM7Rf1Ko4) from the primary USDA BioProject for the cattle sequences (https://t.co/ronBxKBDwO). BioProject PRJNA1122849 wasn't included in ingest. We'll look into including.
@0bFuSc8@USDA_APHIS @LouiseHMoncla Looking now, I don't see "mouse" represented in NCBI GenBank sequences, NCBI SRA sequences or GISAID sequences. If you have an accession that would be helpful.
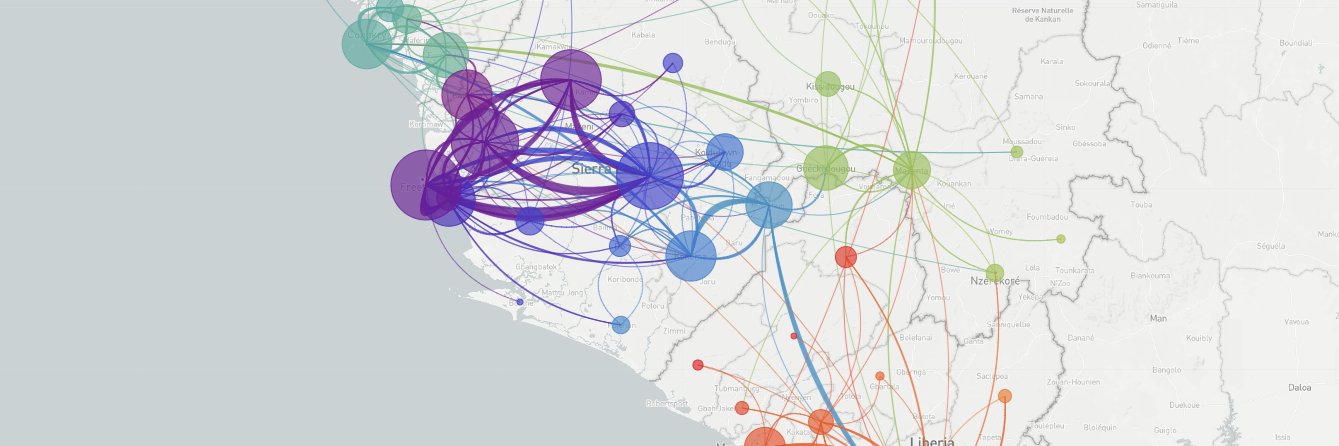
We've set up automated ingest routines to combine data from NCBI GenBank with data from the SRA. Including SRA data allows for a more up-to-date view of evolution. 2/3
We also include a new Nextclade dataset to call measles genotype at https://t.co/NyyF6bfRvM. This work is described on the Nextstrain blog at https://t.co/WL3B05ZEyY.
Thanks to work by Kim Andrews, we've recently updated our analyses and resources for measles virus. We now include automatically updated views of evolution of both the full genome at https://t.co/cUvKinxjvy as well as the N450 segment at https://t.co/AdSH5KDrv0. 1/2
@eyalherlin We've been generally mirroring content between here and Mastodon (quiet there as well since Jan). We'd plan to continue this pattern of posting to both for the time being.
We've been less active on Twitter / X for the last few months. A decent summary of recent Nextstrain activities and future directions can be seen in our annual update posted to the blog in March: https://t.co/QmzJGjMchk
We hope that this will enable many exciting applications in the future.
Let us know if anything doesn’t work, what you like or don’t like, and what can be improved!
Ask a question on: https://t.co/LWv64s4gd0
Or open a Github issue: https://t.co/b82ANO6Txl
9/9
Nextclade might be useful for many more viruses that our team can support. We therefore added the possibility of community datasets and hope that some of you will contribute datasets!
We have a new tutorial to help get started: https://t.co/hDScmsLaB3
6/9
The seed matching step of the pairwise alignment now copes with sequences up to 15% divergence such that diverse viruses like HIV-1 can be aligned.
5/9