@equinoxmonk You’re not going to have to buy it is the difference, it’s a riot game. Agreed on the needs but with their monetization there’s less pressure on immediate success
@jainarvind Currently, we batch Granola context as the source of truth with Glean MCP or downloaded context on top, but there’s a real chance to be the native context aggregator for companies to build agents on top of. Without meetings, though, Glean will always be complementary instead
@jainarvind IMO the highest value thing glean could build is its own version of granola. You have access to context (who is talking, their role/relationship to you) in ways Granola or Zoom do not. Consolidating one context folder with Glean MCP would be a much better workflow
@zarazhangrui These are great, used it for a presentation this week and people loved it. Would be awesome if there was an easier way to port to google slides so people could collaborate, Claude wasnt able to figure that out how to export with fidelity
@drewlevin The survivorship bias seems too strong here. IMO a better approach would be to take a snapshot at some -time from the transgression (10 seconds, 30, etc) and analyze game state for W/L probability and look at the delta from that moment to after the transgression occurs
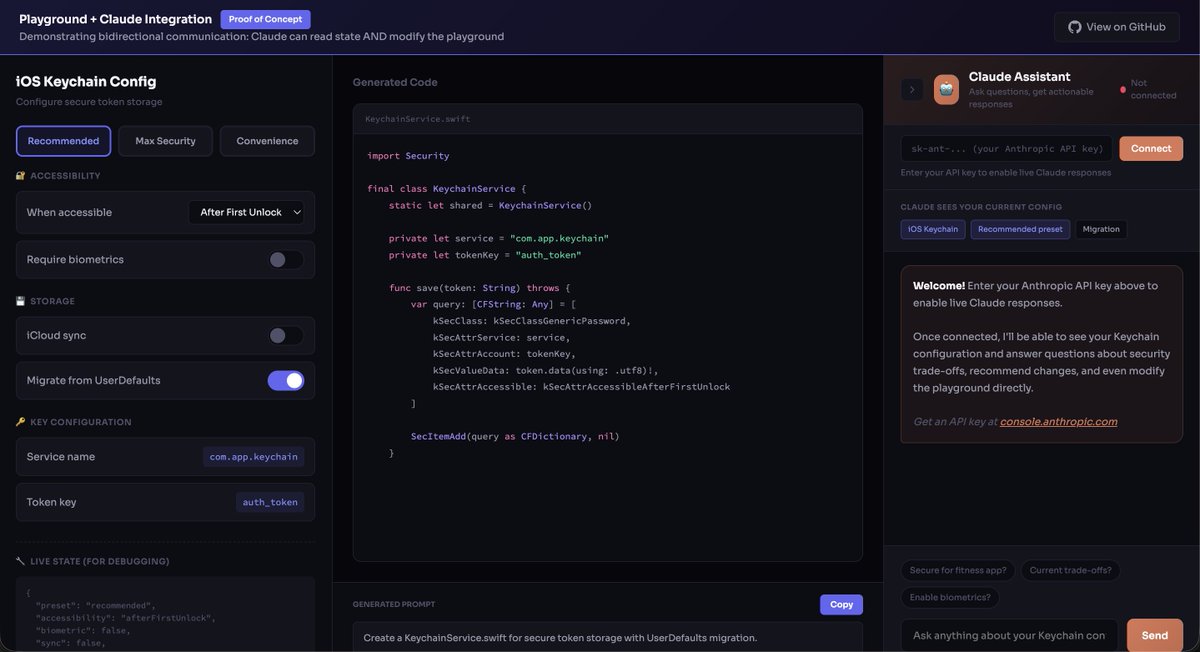
@trq212 Built a demo for this - chat panel on the right lets you ask Claude anything, and it can actually modify the playground based on your instructions. Rn needs an API key but a WebSocket bridge would make it seamless. Lmk what you think!
https://t.co/tcqnM0lliG
@trq212 What's missing imo is the ability to query claude within the html to understand what implications design decisions have - had to go back to the terminal to do that but also not sure where's there room in the html UI
@trq212 Prepping an app for app store from local use, love how there were both presets and customizable options on the side. It feels like this would be done faster normally since it took ~2m to load but the visualization is definitely helpful
Mechanism 3 cont.
The quality score ensures that if a publisher is NOT providing new information, they'll receive 0 reward - ensuring that freeloaders will eventually leave the network
Claims cont:
If HP finds that there's a discrepancy, the final check is users of the Pyth network will vote whether the prices published were correct or not. If they vote the data was incorrect, the reward is slashed and distributed to consumers who bought the insurance
Mechanism 3 cont.
The reward for publishers is the product of three factors:
1. Stake weight
2. Quality score - if publisher provides new information (eg price movements) this score increases
3. Calibration score - how many confidence intervals away from the median
Mechanism 3: Reward Distribution
Pyth optimizes around three key properties for reward distribution:
1) Reward Quality
2) Honesty - discourage publishers from merely agreeing with other prices
3) Uninformed Participants - eliminate freeloaders
Mechanism 2: Data Staking
All transactions are validated on a weekly epoch cycle and a per-product basis. Delegators stake their tokens behind publishers they trust, and if the prices are deemed to be correct they'll earn a share of the payout