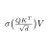A preview for Pro users: a new personal finance experience in ChatGPT.
Pro users in the U.S. can securely connect financial accounts, see where their money is going, and ask questions based on the information they choose to connect.
Your full financial picture, now in ChatGPT.
@kentcdodds@aiDotEngineer Yeah! That kind of turnout could’ve been expected; maybe a ballroom for the most hyped tech next time?
On a related note, we built Zapier MCP servers. Would love for you to check it out
https://t.co/YQLLpyVPup
My analysis for Llama 3.1
1. 15.6T tokens, Tools & Multilingual
2. Llama arch + new RoPE
3. fp16 & static fp8 quant for 405b
4. Dedicated pad token
5. <|python_tag|><|eom_id|> for tools?
6. Roberta to classify good quality data
7. 6 staged 800B tokens long context expansion
Long analysis:
1. New RoPE extension method
Uses an interesting low and high scaling factor, and scales the inv_freq vector - can be computed in 1 go, so no need for dynamic re computation. Used a 6 stage ramping up approach from 8K tokens to 128K tokens with 800B tokens.
2. Training
38% to 43% MFU using bfloat16. Pipeline parallelism used + FSDP. Model averaging for RM, SFT & DPO stages.
3. Data mixture
50% general knowledge
25% maths & reasoning
17% code data and tasks
8% multilingual data
4. Preprocessing steps
Uses Roberta, DistilRoberta, fasttext to filter out good quality data. Lots of de-duplication and heuristics to remove bad data.
5. Float8 quantization
Quantizes weights to fp8 and input to fp8, then multiplies by scaling factors. fp8 x fp8 then output is bf16. Faster for inference & less VRAM use.
6. Vision & Speech Experiments
The Llama 3.1 team also trained vision & speech adapters - not released though, but very cool!
Working on adding support into @UnslothAI!
Uploaded 4bit bitsandbytes quants for 8b, 70b and 405b ongoing to https://t.co/gHMS1CeFLF
@sirajraval BTC value preservation might be interesting in some rare cases. A decentralized compute network doing useful AI inference work makes more sense