Try https://t.co/qCNLQproSY. it stores website screenshots, recordings + design tokens (colors, fonts, shadows, border-radius CSS values).
Export tokens to Tailwind or Figma.
Each screenshot has an llm.txt for prompting LLMs to recreate the design.
@yay3d Could we theoretically compile the entirety of text only wikipedia (~90gb) ? If so should we expect your scaling estimates ? I feel it should taper off at a certain point with redundant facts ?
When the Neurosymbolic AI harness Prethinker compiles natural language into Prolog it builds a package that retains epistemic uncertainty as a KB too
https://t.co/kw76dN7anH
@vladmoroz Check out https://t.co/xyygrzs2xu
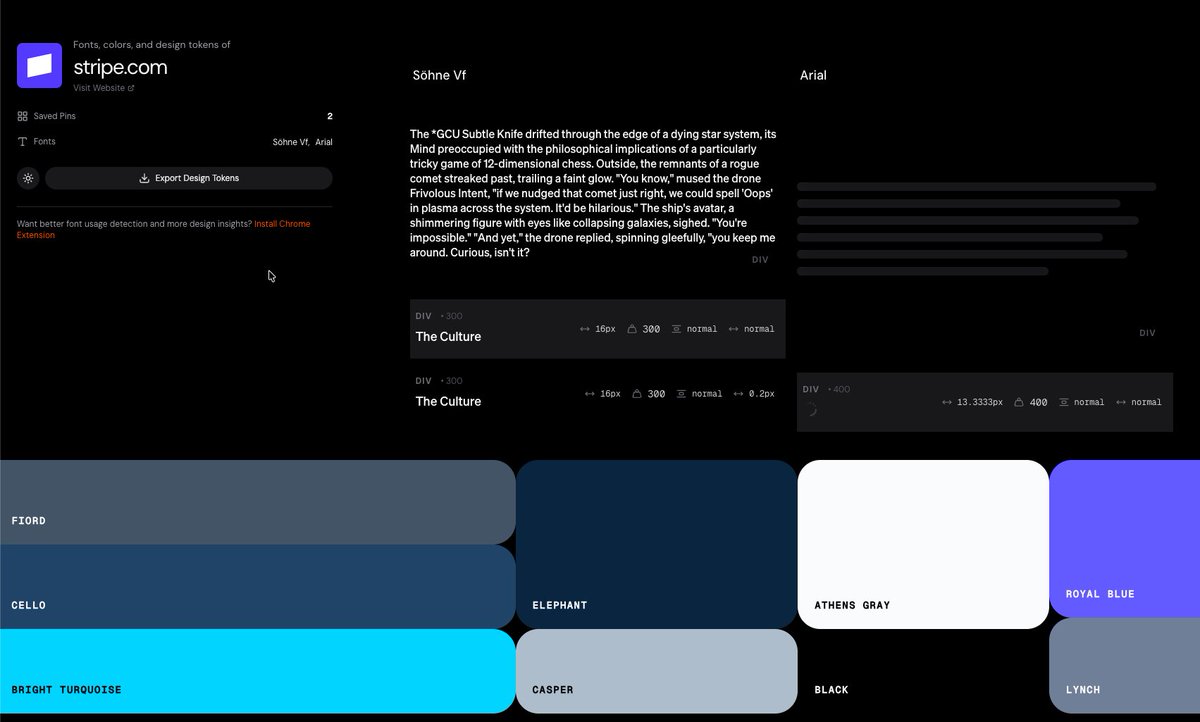
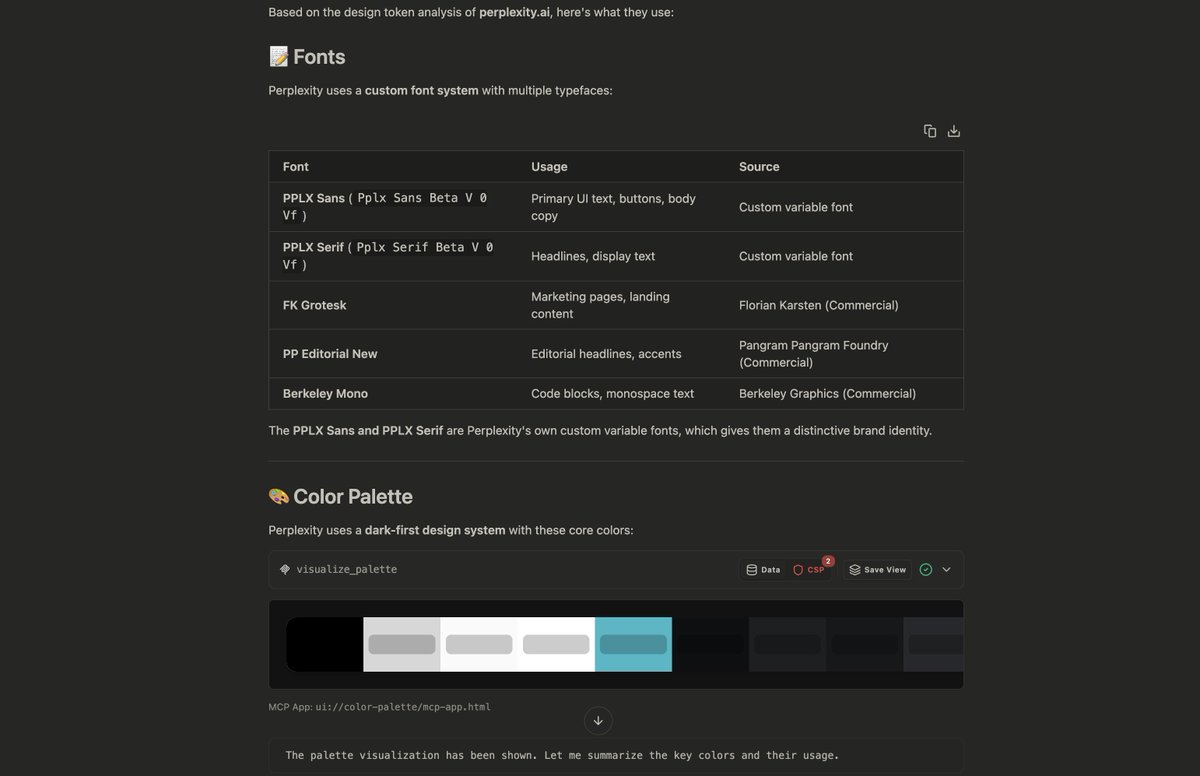
Has an MCP server to let your AI extract design tokens from any website + semantic search for finding inspo with natural language.
You can also use it to find font pairings, generate color hue with proper contrast ratios or do competitor research
@hamzaalabou The idea is to start from primitives -> design tokens + style guide -> components -> constrained generation based on composition.
I'm working on an AI workspace for this
@adamwathan I built a way to find inspiration by describing in natural language, so If you're looking for design ideas you can search "testimonial sections"
https://t.co/vPv9qt7iWq
@Mike_Andreuzza Definitely! $5 is more reasonable. especially the MCP you should lean into that. Most of my subscribers for fontofweb explicitly use it for the mcp feature.
@threepointone Prolog, i'm increasingly more convinced LLMs should serve as a fuzzy input layer atop a more structured knowledge base. Natural language goes in. The LLM extracts structured constraints. Those constraints land in a proper knowledge base that does real reasoning.
Figma exists because code used to be too expensive to think in.
So we invented a safer, flatter medium where product teams could make visual decisions without incurring the full cost of building.