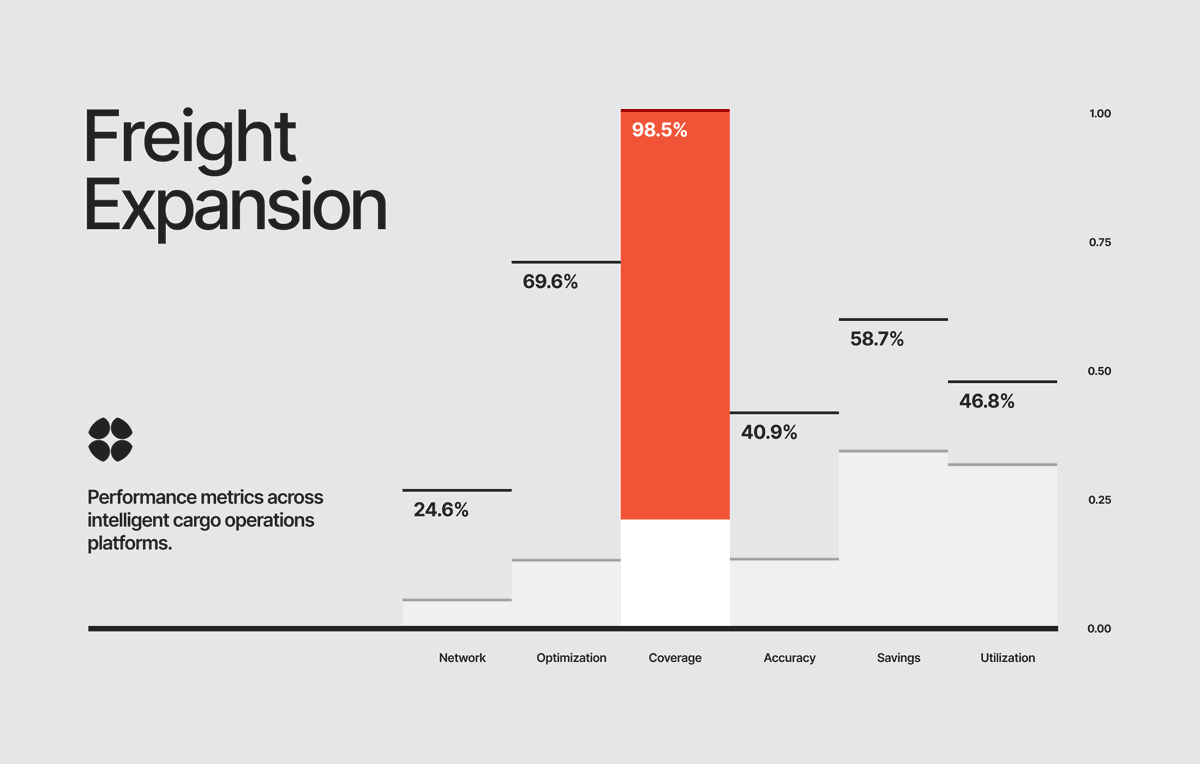
CREAMOS TU ESPACIO!
Utilizamos las últimas tecnologías para ofrecerte el diseño y la programación de un espacio web funcional, atractivo y autogestion.
Alguien creó una versión de Gemma 4 llamada gemma4-12b coder, una IA especializada en programar que funciona 100% en tu propia computadora, sin internet y sin pagar nada.
La probé hoy en un DGX Spark y aunque esperaba que fuera rapidísima, aprendí dos cosas útiles, sobre todo para no caer en el marketing de los que venden estos modelos como la solución a todo:
1.Lo que hace lenta o rápida a una IA no es lo “potente” que sea tu equipo (el cómputo de la GPU), sino qué tan rápido puede leer su información de la memoria (el ancho de banda). Es como un chef buenísimo atascado porque la despensa está lejos: no importa lo rápido que cocine si tarda en traer los ingredientes. Por eso una versión más comprimida del modelo (un quant más bajo, Q4 en vez de Q8) corrió 57% más rápido.
2.Más grande no siempre es mejor. La versión de máxima calidad (Q8) casi no se nota frente a una más ligera (Q4), que va mucho más rápido y rinde casi igual. Bajar demasiado (a Q2) sí arruina el código. El punto dulce está en el medio.
Tener una IA local, privada y gratis está increíble. Pero conviene entender cómo funciona antes de creer que solo se necesita mucha potencia
.@NeowinFeed highlights AMD Ryzen AI Halo, powered by Ryzen AI Max+ 395 and designed to give developers and creators the Windows 11 support, ROCm tools and high-capacity memory needed for powerful local AI performance.⚡
Read more here: https://t.co/JXqdLvwXHK
AMD acaba de dar un golpe fuerte en la IA local.
Lisa Su subió al escenario con un mini PC del tamaño de un libro grueso en una sola mano y ejecutó en vivo un modelo de 235 mil millones de parámetros. Sin datacenter. Sin cloud. Sin alquilar GPUs.
El protagonista es el Ryzen AI Max+ 395 (Strix Halo). Es el primer chip x86 que une CPU y GPU con 128 GB de memoria unificada. En Linux, el GPU puede usar hasta ~110 GB de esa memoria.
Para ponerlo en contexto: una RTX 5090 tiene 32 GB y una 4090 tiene 24 GB. Este pequeño equipo ofrece más del triple de memoria accesible para modelos grandes, en un chasis compacto.
En pruebas específicas de inferencia (como DeepSeek R1), superó en más de 3x al rendimiento de una RTX 5080 cuando el modelo no cabe en la VRAM de la tarjeta de Nvidia.
El precio real del equipo con 128 GB (GMKtec EVO-X2) suele estar entre $1,800 y $2,500 según ofertas (el kit oficial de AMD es más caro).
Para quien usa mucho IA, esto cambia las cuentas: en vez de pagar cientos de dólares al mes en suscripciones (Claude, ChatGPT Pro, Cursor, etc.), puedes correr modelos potentes localmente con Ollama, LM Studio o similares. Privacidad total, sin límites de tokens y sin que te corten el servicio a las 3 a.m.
No es que las suscripciones vayan a desaparecer mañana, pero para muchos casos de uso (RAG con documentos privados, prototipos, agentes locales, etc.) esta opción se vuelve muy atractiva.
Estamos viendo el inicio de una nueva etapa de IA local accesible y potente??
Community Week took us to @vercel's HQ in San Francisco🚀
A conversation with @rauchg, Founder & CEO of Vercel, investor across our portfolio, and one of the most influential builders shaping how the world ships software.
#NewtopiaVC
🌍 El ESG cambia demasiado rápido como para seguirlo todo.
Seleccionamos lo más importante sobre:
- sostenibilidad y ESG
- regulación y tendencias
- entrevistas y casos reales
- eventos y opinión experta
Ya lo reciben +13.000 profesionales.
¡Suscríbete gratis a la newsletter!
As CEO of OpenAI, Sam Altman unleashed ChatGPT, mainstreaming artificial intelligence and creating a $500 billion behemoth. While he might not play technical role as an engineer, his efforts as an accelerator has landed him a spot on the #Forbes250 list, featuring America’s greatest living innovators.
Get the full list: https://t.co/kszvRsR2NB Photo: Cody Pickens for Forbes