Excited to introduce our MAI Code model at Microsoft Build. As shared in the session, this is a MoE (5B active / 137B total) initialized from an MAI pretrained model and trained for real user scenarios with product harnesses. I’m proud to have served as the research lead for this effort, and even prouder of what the team has achieved. It’s a beast for its size. Stay tuned — a larger model could come :)
MAI-Code-1-Flash is here! Built and optimized for GitHub Copilot. From quick fixes to complex engineering challenges, write better code with more return on token. Rolling out to GitHub Copilot individual users in Visual Studio Code in the model picker and under the default auto picker now.
Excited to introduce our MAI Code model at Microsoft Build. As shared in the session, this is a MoE (5B active / 137B total) initialized from an MAI pretrained model and trained for real user scenarios with product harnesses. I’m proud to have served as the research lead for this effort, and even prouder of what the team has achieved. It’s a beast for its size. Stay tuned — a larger model could come :)
MAI-Code-1-Flash is here! Built and optimized for GitHub Copilot. From quick fixes to complex engineering challenges, write better code with more return on token. Rolling out to GitHub Copilot individual users in Visual Studio Code in the model picker and under the default auto picker now.
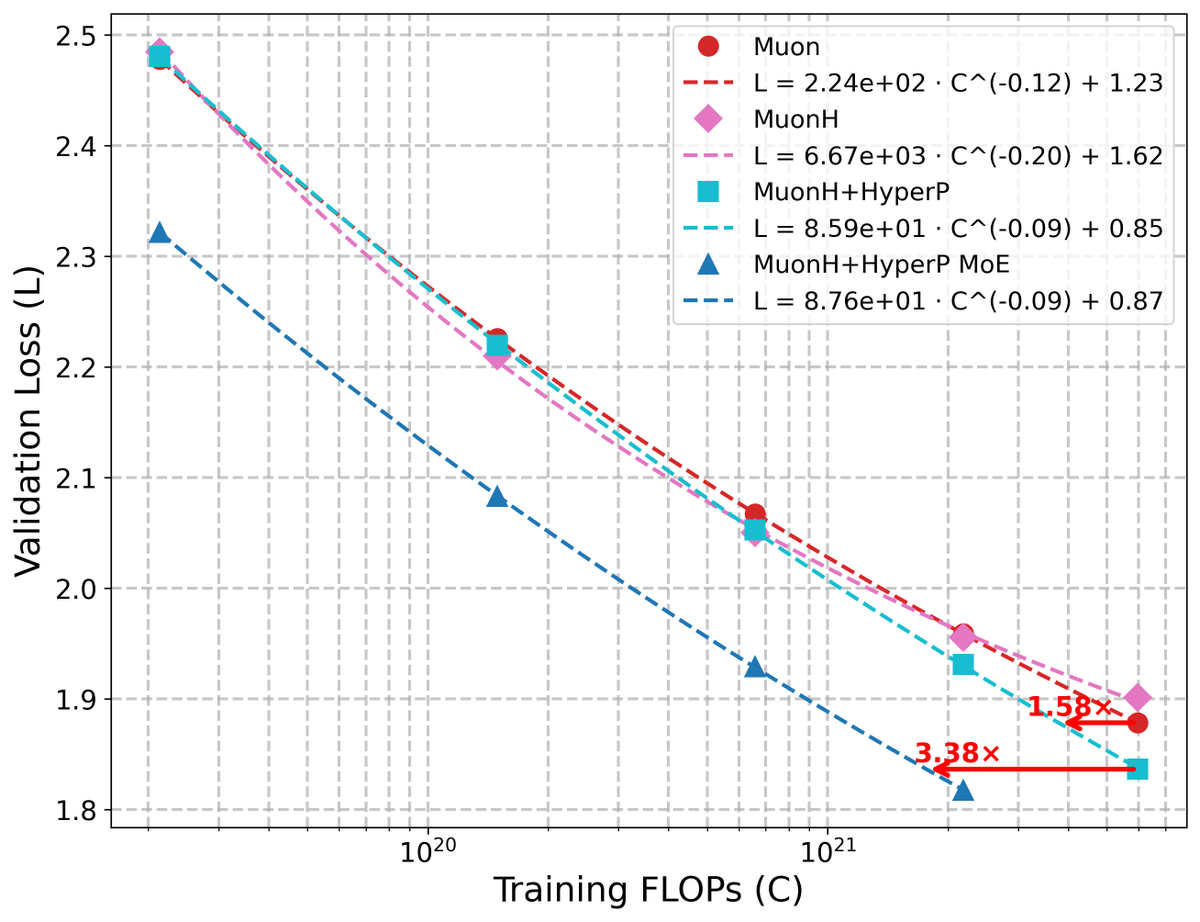
Introducing HyperP, a scaling framework gives you better compute efficiency & transferable stability. At 6e21 FLOPs, HyperP reaches 1.58× compute efficiency over a strong Muon baseline; +MoE further gets 3.38× over dense. Gains even grow with scale🤯
📖: https://t.co/gZRvX9qAIi
Missing coding data in your R1? Introducing KodCode 🐱: a diverse, challenging, and verifiable synthetic dataset for LLM coding!
With 447K verified question-solution-test triplets, KodCode is designed for supervised fine-tuning (SFT) and reinforcement learning (RL).
💡Key Features
✨Diverse & Challenging: 5 synthesis methods, 12 subsets covering multiple domains (algorithms to package-specific knowledge) and difficulty levels (basic exercises to competitive programming tasks).
✨Verifiable Correctness: Question-solution-test triplets are systematically validated via a self-verification process with GPT-4o.
✨ Supports RL & SFT: Unit tests enable RL tuning, plus verified CoT responses generated by DeepSeek-R1 🐳 via reject sampling to support SFT.
---------------
>> Project Page: https://t.co/9IL4gEofmH
>> KodCode-V1 (for RL): https://t.co/CWE7SRBZXA
>> KodCode-V1-SFT-R1 (for SFT): https://t.co/4kK5eAhpCs
>> Paper: https://t.co/9J8uLMy3CU
>> Codebase for creating this dataset: https://t.co/EwKHpbdMsM
Thanks to my great mentor @nlpyang for invaluable guidance and support on this project! 🤩
[1/5]
Missing coding data in your R1?
🔥 Introducing KodCode—the largest verified synthetic coding dataset for Code LLM training!
• 447K question–solution–test triplets
• 12 diverse subsets
• 10-trial solution verification for rock-solid correctness
https://t.co/HILpz70PTT
Evaluating LLMs usually requires sophisticated human designs and with the continuous improvement of LLMs, it is difficult for humans to find their limitations.
Can LLMs find their own limitations by proposing questions to themselves? Check our new paper: https://t.co/lDkBCQsIVR
Microsoft GenAI is looking for a summer intern to work on Sparse LLMs, if you are interested, please DM me or send a resume to yaliu10 at microsoft dot com
Introducing Samba 3.8B, a simple Mamba+Sliding Window Attention architecture that outperforms Phi3-mini on major benchmarks (e.g., MMLU, GSM8K and HumanEval) by a large margin.😮 And it has an infinite context length with linear complexity.🤯
Paper: https://t.co/KwMpeyaDxc
(1/6)
Introducing Samba 3.8B, a simple Mamba+Sliding Window Attention architecture that outperforms Phi3-mini on major benchmarks (e.g., MMLU, GSM8K and HumanEval) by a large margin.😮 And it has an infinite context length with linear complexity.🤯
Paper: https://t.co/KwMpeyaDxc
(1/6)
GPT-4o is also natively multilingual. We've improved our tokenizer for various languages, resulting in, for example, a 3-4x speed improvement for Indian languages.