Grokking modular arithmetic is widely studied for the seemingly unique emergent abilities of neural networks.
Instead, we find that iteratively solving a kernel machine and estimating the Average Gradient Outer Product (AGOP) recovers this phenomenon identically:
@iclr_conf shoutout to @eaboix and @nmallinar for actually doing the work that made this paper happen, and Misha Belkin for advising.
paper here: https://t.co/FKsDjCRv84
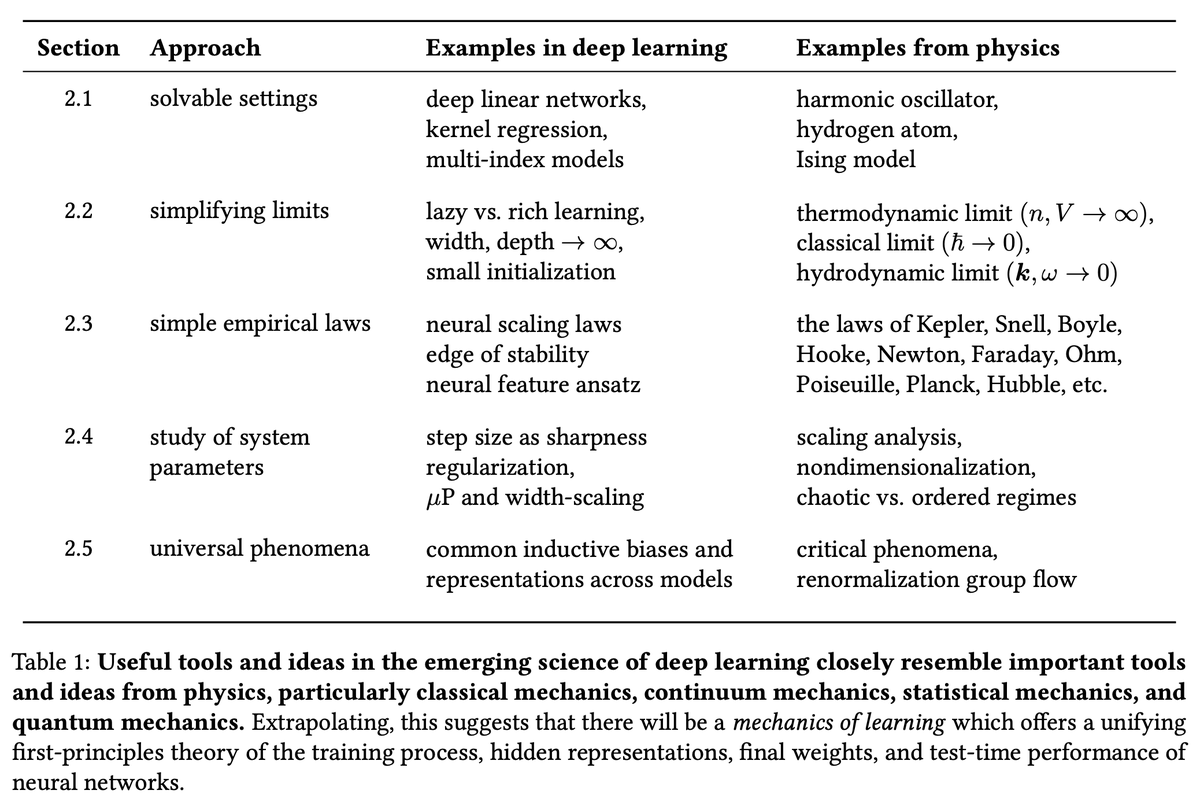
1/ Deep learning is going to have a scientific theory. We can see the pieces starting to come together, and it's looking a lot like physics!
We're releasing a paper pulling together these emerging threads and giving them a name: learning mechanics.
🔨 https://t.co/92nSIHameW 🔧
Super excited to share that we have an Oral presentation for this paper next week at ICML!
It will be on Tuesday at 10am (Oral 1E) in West Ballroom D, I'll be presenting 4th at 10:45am :)
Our poster will be on Wednesday at 11am and I encourage you to stop by and chat!
Grokking modular arithmetic is widely studied for the seemingly unique emergent abilities of neural networks.
Instead, we find that iteratively solving a kernel machine and estimating the Average Gradient Outer Product (AGOP) recovers this phenomenon identically:
Two generalization regimes in ICL: (1) context-scaling, where performance improves with more in-context examples, and (2) task-scaling, where performance improves with more pre-training tasks. While MLPs show task-scaling but not context-scaling,
https://t.co/fWBMHhrqs7
@thdbui@pfau Anyway I enjoyed your paper and would love to get a chance to discuss these topics further sometime and hear more about your observations!
@thdbui@pfau Another difference we see compared to grokking in low-rank settings like k-parity is that the circulant features we learn for modular arithmetic (MA) are full rank! It wasn't obvious to us that you could do MA with kernels as the MA experiments we see all use neural nets still
Grokking modular arithmetic is widely studied for the seemingly unique emergent abilities of neural networks.
Instead, we find that iteratively solving a kernel machine and estimating the Average Gradient Outer Product (AGOP) recovers this phenomenon identically:
Iterating kernel ridgeless regression with AGOP computation groks modular arithmetic… and this grokking is remarkably similar to the phenomenon in neural networks.
I found these results very surprising!
Please check out our paper here: https://t.co/A4Vz2d1X2S
This was an amazing collaboration with Daniel Beaglehole (@dbeagleholeCS), Libin Zhu (@BusyZhu), Adit Radhakrishnan, Parthe Pandit (@PartheP), and Misha Belkin.
In our setting, grokking appears to occur solely due to feature learning. We decouple from neural architectures and gradient-descent based optimization by using kernels equipped with feature learning through AGOP and find many of the same phenomena as observed in neural networks.