And you're routing prompts through a Chinese-built agent and consumer chat apps, a live data-governance question for teams. Cheap and chat-triggered is a new pitch. Whether GLM-5.2 holds up on your real repo is what nobody has benchmarked, so try it on a throwaway project first.
https://t.co/OXvR9sPE71 just shipped ZCode: its own coding agent for GLM-5.2, free to download, with a paid plan that starts at $16.20 a month. The lab that undercut Anthropic on the model is now going after Cursor and Claude Code on the tool.
The quota multipliers and speed numbers are all https://t.co/OXvR9sPE71's own copy, with no independent benchmark yet. One Max user reported a single 5-hour run eating 40% of the weekly limit, plus the service dropping repeatedly.
Fable 5 is back. Global since July 1, and on Pro, Max, or Team it's included in up to 50% of your weekly usage until July 7. After that, usage credits only. For reference the API runs $10 in, $50 out per million tokens, so this is a premium tier, not a daily driver.
Which means you've got about five days of the most capable model Anthropic makes broadly available, mostly included. The trap is spending it on what Sonnet or Opus already handle fine. Chat, boilerplate, a small refactor. Your usage drains and you got nothing you couldn't have gotten cheaper.
Point it at the one job you've been avoiding because it's too big to hand a normal model.
What that tier chews through, from Anthropic's own writeups:
Stripe ran a codebase-wide migration in a day that would have taken a team over two months by hand.
It wrote a browser-based CAD editor, then designed a 3D-printable model inside the editor it had just built.
It played a Pokemon game to completion from raw screenshots, vision only, no game state handed in.
Long-horizon, many files, holds context across hours. If you have a scary migration, a spec rotting in a doc, a refactor nobody wants to start, that's the window.
One thing before you fire it off: the redeployed build is locked down harder after the export-control mess, so security-shaped tasks get flagged or refused more often now. It also burns usage much faster than Opus, so that 50% goes quicker than you'd think.
Pick the one hard thing. Aim it there before the 7th.
Claude Sonnet 5 is here.
Top-tier performance on coding and tool use at Sonnet pricing, with a 1M context window.
It's the new default in Claude Code for Pro users, and available everywhere on the Claude Platform, including the API and Managed Agents.
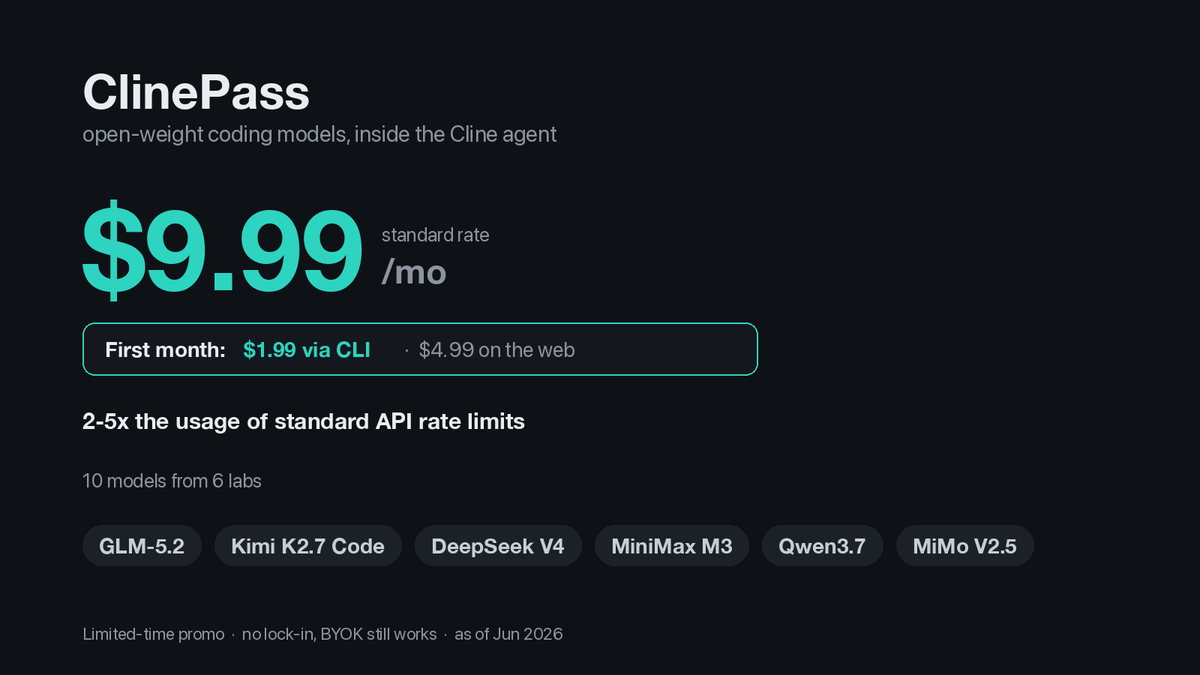
Cline just shipped ClinePass, and the pitch underneath it is the part worth reading. Cline is the open-source coding agent at 64k stars and 8 million developers, and their argument is blunt: the model stopped being the moat. Open-weight caught up, so the harness around it is where the engineering happens now.
ClinePass is their answer. One $9.99 a month subscription that bundles ten open-weight coding models behind Cline's own agent loop, with no separate provider keys to wire up. The lineup is the current open-weight roster: GLM-5.2, Kimi K2.7 Code and K2.6, DeepSeek V4 Pro and Flash, MiniMax M3, Qwen3.7 Max and Plus, and MiMo V2.5. Quotas run around 2 to 5 times what those models give you at standard API rate limits.
The intro pricing is aggressive. Standard is $9.99 a month. First month is $4.99 on the web, or $1.99 if you start through the Cline CLI (npm i -g cline). It is a limited-time promo, so treat the $1.99 as a door, not the rate.
Why it matters past the discount: this is the harness-over-model idea turned into a product. Semgrep just showed an open-weight model beating Claude on a bare prompt, and Cline is betting the same thing, that a good-enough model plus a strong loop covers most coding work at a fraction of frontier cost. Most tasks never needed frontier polish.
Getting started is short: npm i -g cline (or the VS Code extension), subscribe to ClinePass, pick it as your provider, and code. It runs across CLI, VS Code, JetBrains, and the SDK, and your own API keys still work next to it, so there is no lock-in.
The catch: you are routing through Cline's managed gateway, a paid layer on top of the open tool, and open-weight is good-enough, not frontier-polished for the hardest problems. Cline's own benchmark looks strong, but they say plainly they are not overclaiming from one run.
If you have wanted to live on open-weight models without juggling six provider accounts, this is the cleanest on-ramp right now. Cline stays open source; ClinePass just makes the cheap path easy.
In the next version of Claude Code: subagents run in the background by default, so you can keep talking to Claude while your subagents work
If you want your agent to run in the foreground, just tell Claude
Semgrep is blunt: one task, one dataset, one run, IDOR is non-deterministic. GLM beat the next open-weight model by 16 points, so it's one model on one task, not open weights catching up. Builder takeaway: don't lock to one model, the harness matters more than the name on it.
An open-weight model just beat Claude on a real security benchmark. Semgrep tested models on IDOR detection, the missing-authorization bug that is genuinely hard to catch. GLM-5.2, on a bare prompt, scored 39% F1. Claude Code on Opus 4.8 got 28%, at about a sixth of the cost.
But the ranking is the trap. The top two spots went to Semgrep's own harness wrapping GPT-5.5 (61%) and Opus 4.8 (53%): the same models, fed the right endpoints by purpose-built scaffolding. The harness moved the score far more than the model choice did.
TradingAgents is the most-starred open-source AI trading framework on GitHub, 89k stars. The interesting part is not that it trades. It is how it is built: as a small trading firm staffed entirely by LLM agents.
The work moves through roles, not one prompt. Four analysts go first, covering fundamentals, sentiment (news, StockTwits, Reddit), macro news, and technicals like MACD and RSI. Their reports go to two researchers, one bull and one bear, who argue it out in a structured debate. A trader agent reads that debate and sizes the trade. Then a risk team and a portfolio manager sign off or kill it before anything reaches the simulated exchange. It runs on LangGraph, with checkpoints and a persistent decision log.
The reusable lesson sits above trading. The pattern is role-specialized agents, an adversarial bull vs bear step that forces both sides to actually be argued, and a risk gate that can veto before any action. That shape works for any agent making a high-stakes call, not just buying stock.
Now the honest part, straight from their own docs. It is built for research, not financial advice. Because it is LLM-driven, the same ticker on the same date can return different calls on two runs. Orders hit a simulated exchange, not your brokerage. So 89k stars is interest in the design, not proof of returns. Treat any backtest as a starting point, not a track record.
Setup is short and standard:
1. Clone the repo (link below) and cd in.
2. Create a Python 3.12 environment and activate it.
3. Install it: pip install . (or skip local setup and run it in Docker: docker compose run --rm tradingagents).
4. Set one model provider key, like export ANTHROPIC_API_KEY=... It also takes OpenAI, Gemini, Grok, DeepSeek, or a local model through Ollama. Add a data key such as ALPHA_VANTAGE_API_KEY for market data.
5. Run tradingagents, then pick your ticker, date, provider, and research depth.
It works on any market Yahoo Finance covers.
If you want a clean reference for multi-agent design, this is one of the best to read. Just read it as an architecture, not a money printer.