genuinely feels like im just doing fun research with friends; everyone is so talented, excited, hopeful, kind, and supportive of each other
despite the challenges, it’s so fun to be able to be surrounded by people like this
I am a big fan of Jianlin Su's blog because it always starts from first principles in mathematics, rather than "ML tricks", to approach a typical ML problem (eg. training-free MoE load balancing).
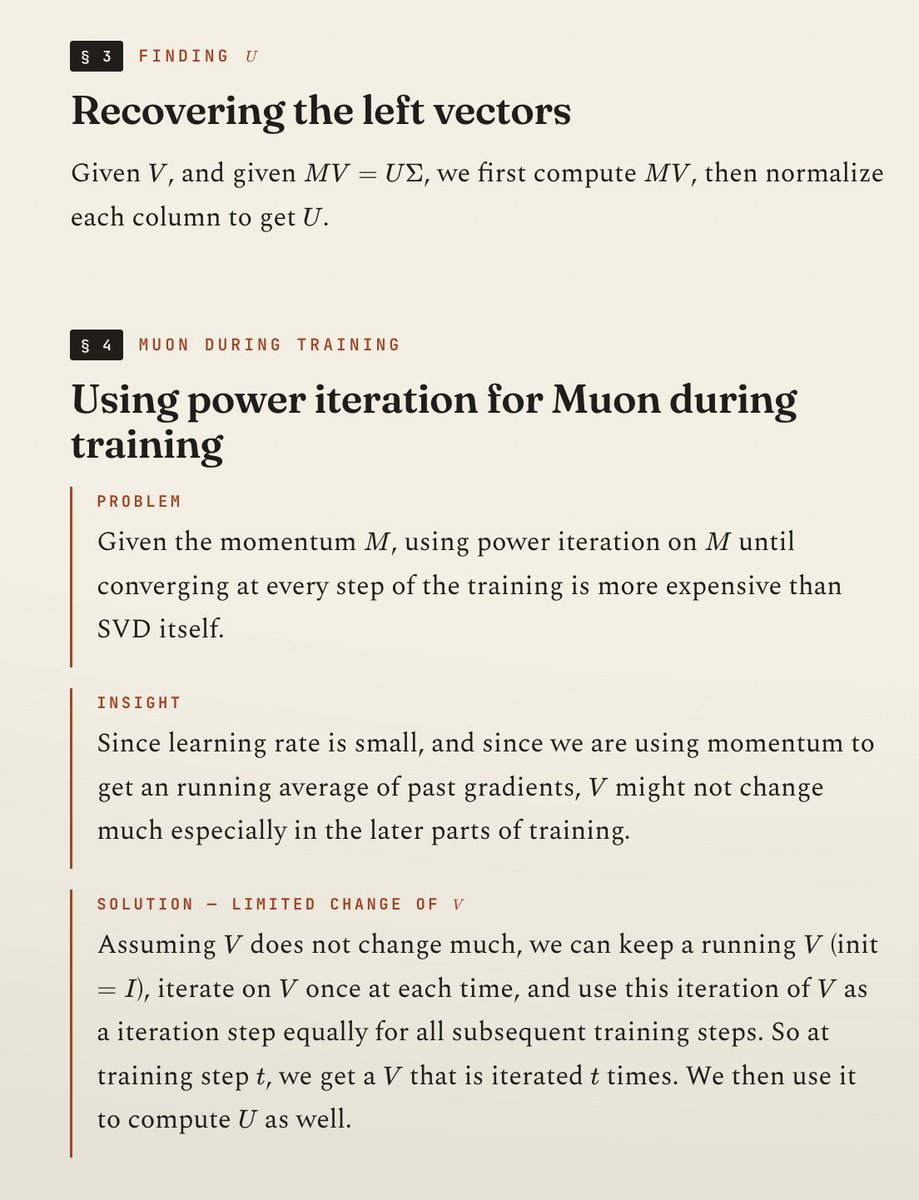
Here is me trying to "reinvent" one such blog which provides an elegant alternative to compute Muon, by filling in all the derivations that the blog skips for a less math-savvy audience (besides being entirely in Mandarin).
The goal of the blog is to find a way to compute a essential component of Muon, ie. the left and right singular value matrices U and V for the gradient G, **individually**. In the standard form, Muon really just needs their product UV^T, hence the standard way to compute it via computing a low-rank polynomial of G many times ("Newton-Schulz"). But there are more variants of Muon to control the properties of model updates if we can get both individually, hence the blog's proposal to revisit some fundamental linear algebra techniques for the computation.
The methodological takeaway from the blog's thought process is that there are three components to breaking down a ML problem: (1) how to be able to compute something (power iteration), (2) how to compute it fast (cholesky decomposition), and (3) how to compute it accurately given finite floating points (repeated orthogonalization). The goal of reading inspiring blogs like this is, in Feynman's term, to be able to "reinvent" them at any time to grasp the fundamental approach of doing similar work.
Original blog: https://t.co/5ksKPICpMW
also, i will be back in sd for a bit in early July - maybe i’ll see some of you around for ACL 2026 :), presenting a bit of work on information theory in RLHF & SFT LM outputs
will be heading out of sd soon to the bay… going to miss this area a lot but excited to work on some fun stuff :)
will be in stealth for a few months, hoping to bring some updates then!
gotta figure out how to bring these two goofballs with me
@tokumin I feel that the trend towards training models to autonomously go off and try to do everything themselves is anti-human.
We should, IMO, be training LLMs to support humans in their learning, creativity, and iterative experimentation.
5. Our current AI systems are doing a fuzzy interpolation between existing data points. This is valuable, but won’t give us something truly outside the scope of the training data. We still need research where new paradigms or different causal mechanisms are required.
one of the best parts about my suitemates being a bunch of researchers / phd students is just randomly bouncing ideas off each other in the hallway / living room
🚀 Today we’re releasing FlashOptim: better implementations of Adam, SGD, etc, that compute the same updates but save tons of memory. You can use it right now via `pip install flashoptim`. 🚀
https://t.co/nRrLSpjnwV
A bunch of cool ideas make this possible: [1/n]
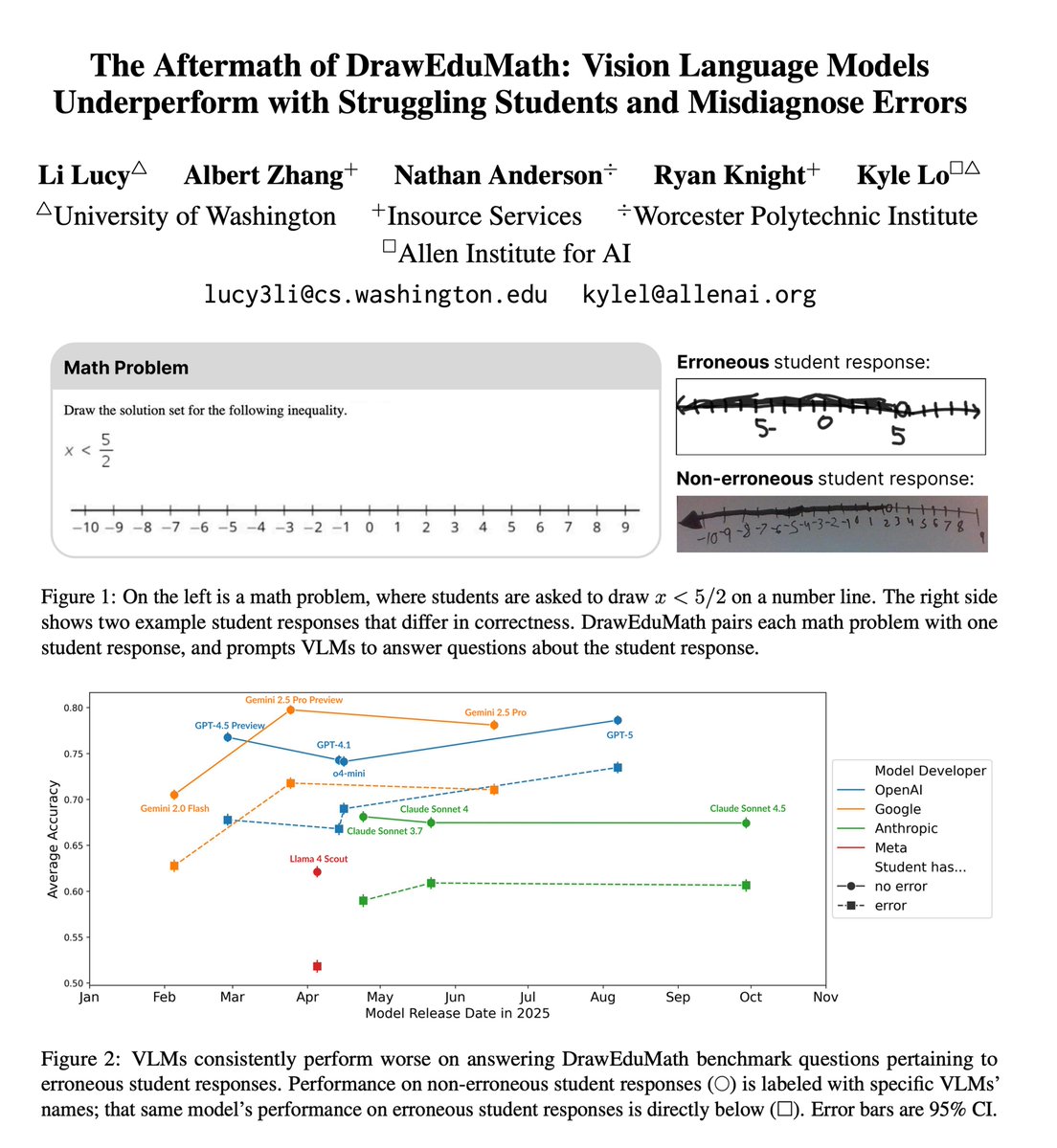
Models are now expert math solvers, and so AI for math education is receiving increasing attention.
Our new preprint evaluates 11 VLMs on our QA benchmark, DrawEduMath. We highlight a startling gap: models perform less well on inputs from K-12 students who need more help. 🧵
first paper of the phd 🥳
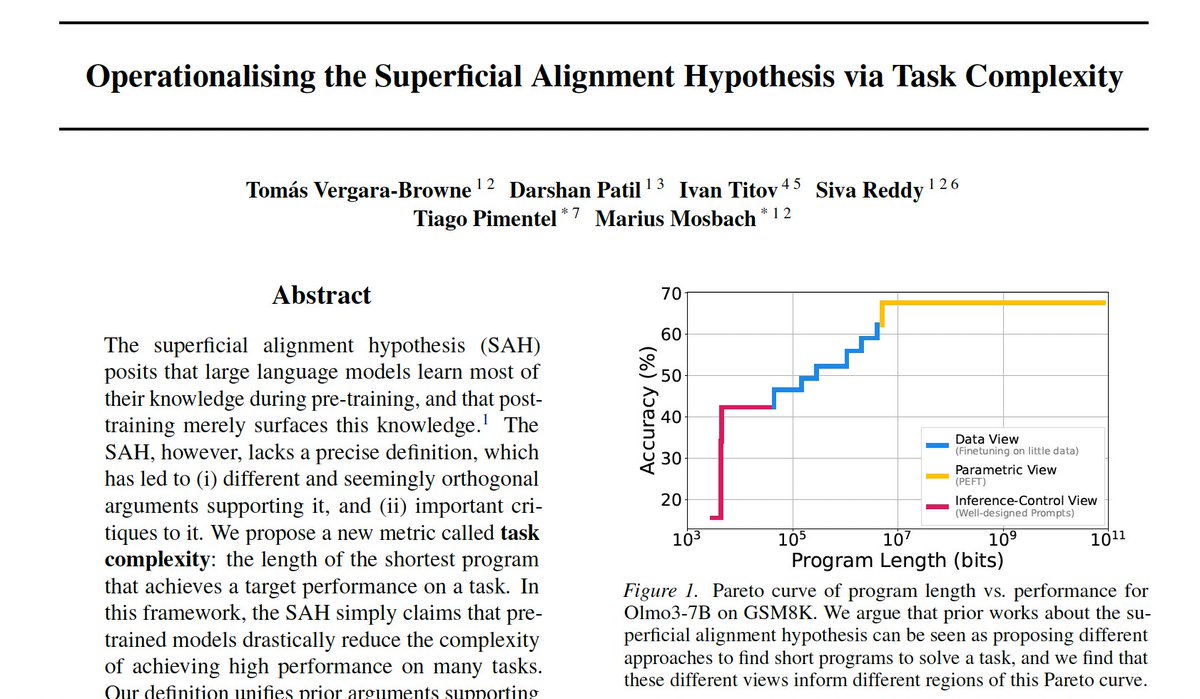
the Superficial Alignment Hypothesis (SAH) argues that pre-training adds most of the knowledge to a model, and post-training merely surfaces it.
however, this hypothesis has lacked a precise definition. we fix this.
Beat it by having Codex hand-craft weights:
https://t.co/g0T6rklaAY
100% accuracy on 10 million random test cases w/ only 343 parameters. As a bonus, it uses the vanilla Qwen3 architecture, just with the right weights.



















![davisblalock's tweet photo. 🚀 Today we’re releasing FlashOptim: better implementations of Adam, SGD, etc, that compute the same updates but save tons of memory. You can use it right now via `pip install flashoptim`. 🚀
https://t.co/nRrLSpjnwV
A bunch of cool ideas make this possible: [1/n] https://t.co/xeaMyWztpv](https://pbs.twimg.com/media/HCgxeDgawAEzt6q.jpg)