🚀 New Paper: Scaling Laws and Efficient Inference for Ternary Language Models.
Thrilled to share that our work was presented at ACL 2025! We explore ternary LMs (TriLMs), studying their scaling laws and efficiency compared to traditional FloatLMs. 🧵
1/6
🎉 Thrilled to share that our paper "Surprising effectiveness of pretraining ternary language models at scale" earned a spotlight at #ICLR2024! We dive into Ternary Language Models (TriLMs), systematically studying their training feasibility and scaling laws against FloatLMs.
1/5
🚀 SpectraSuite of Ternary and FP16 LLMs 🚀
We’re thrilled to release the Spectra Suite of open ternary (TriLMs) and FP16 (FloatLMs) language models from 99M to 3.9B parameters. At billion+ parameter scale, TriLMs upto 10x smaller can match the performance of FloatLMs.
1/5
A little Xmas present 4 you!🎁🎄🎉 Excited for the first release of our open-source Robin vision-language models built by the team at @irinarish’s @cercaai lab @ @UMontreal as part of our INCITE project https://t.co/vJSt6wVEzZ. Blog/models/code: https://t.co/KnaUMFf5RD 🧵
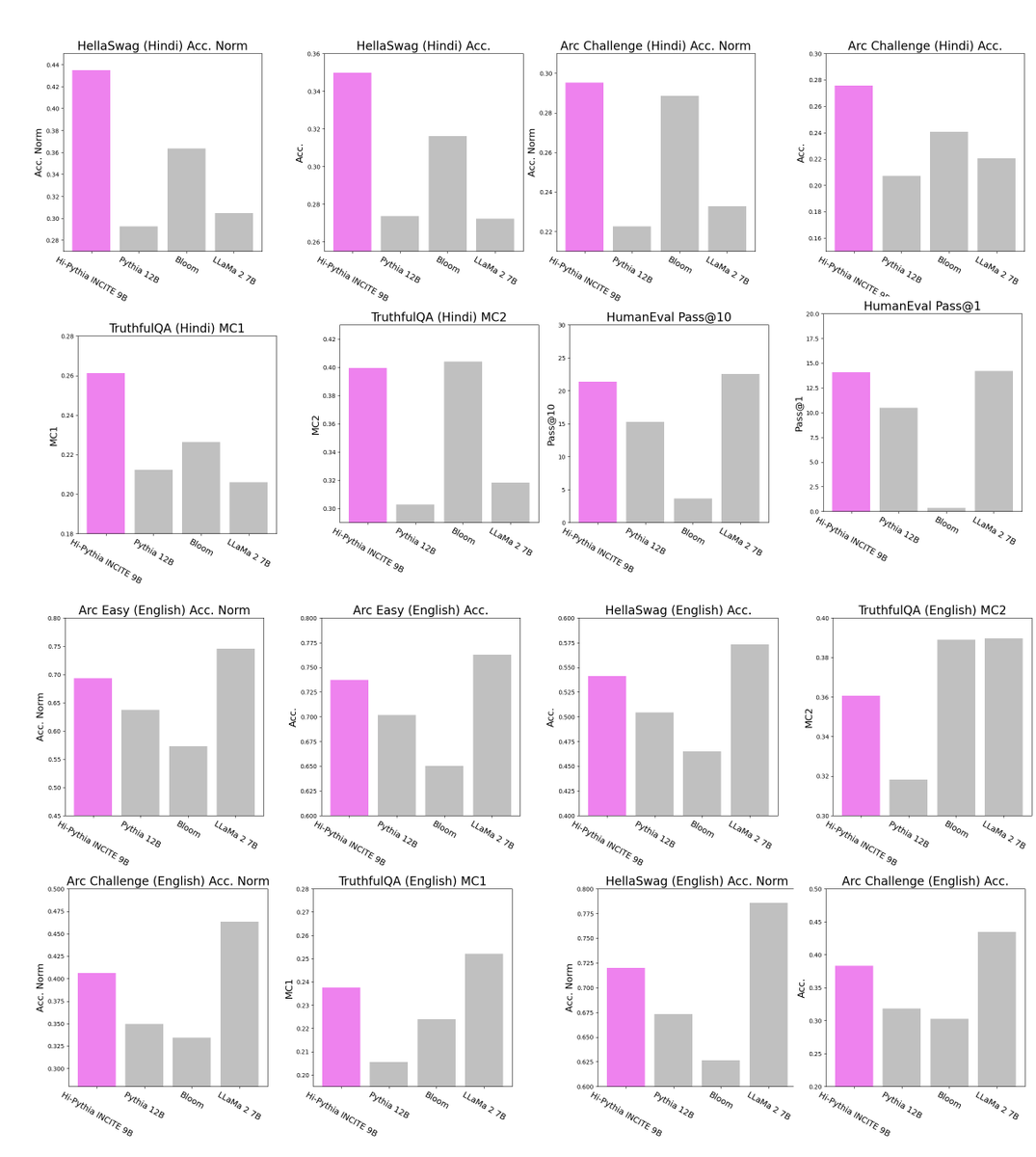
At 60% training completion, it is already outperforming BLOOM and Pythia 9B across most Hindi, English and Coding benchmarks and closes the gap to LLaMa on Coding and English tasks.
8/ LoRD provides a novel approach to LLM compression, maintaining full differentiability and trainability of parameters. It is efficient, compatible with existing methods, and holds immense potential for advancements in the field of monolingual code generation.
7/ Our findings suggest that LoRD is a promising new paradigm for compressing LLMs, offering significant reductions in model parameters without sacrificing model quality or differentiability, and enabling faster inference on modern hardware.