@mitsuhiko@trq212 yup, i just added a post on this :)
@badlogicgames / @mitsuhiko let me know if you want more details or if anything is unclear:
https://t.co/ugzhAkwtf2
With Opus 4.8, you can add system instructions mid-conversation without breaking the prompt cache.
More cache hits means lower cost and latency for your API requests.
3/ some Opus 4.8 tips from testing:
> for long horizon work: pair 4.8 w/ Outcomes in Claude Managed Agents or /goal in Claude Code
> high effort is recommended default
> provide explicit triggering guidance for custom tools + sub-agents
see:
https://t.co/QnPf7B2OTK
a number of useful tips + tricks for Opus 4.8:
1/ you can now update the system prompt mid-conversation w/o breaking the prompt cache.
previously, you had to add <system-reminder> tags to user messages (see @trq212's post).
https://t.co/wX5lYjBXvJ
https://t.co/hyd4vmxWXv
2/ to help with code migration to Opus 4.8, use our claude-api skill built-into Claude Code.
the skill bakes in the prompting guide + best practices for using Opus 4.8.
https://t.co/2Nv80iJDyo
We’ve updated Claude Code's built-in claude-api skill migration guidance for 4.8.
Run "/claude-api migrate" to update your model strings and suggest prompt improvements that are tuned for Opus 4.8.
BREAKING:
Anthropic just dropped Opus 4.8—and it is a MONSTER
We've been testing for about a week @every and our verdict is they could've just called it Opus 5, it's that good.
Here's our vibe check:
- Beats GPT-5.5 on Senior Engineer bench. On our toughest benchmark Opus 4.8 scores a 63—a hair higher than GPT-5.5's score of 62, and a full 30 points higher than Opus 4.7. It tackled a ground-up rewrite of a production codebase, and actually built something that works.
HOWEVER: Coding performance varied a lot at different reasoning levels. We recommend using it on xhigh for best results.
- Incredibly good writer. Opus 4.8 scored a 79.6 on our writing benchmark—measuring models on real-world writing tasks we do all of the time like essay writing, promo email writing, and more. It beats GPT-5.5 by 6 points. It produces well-written prose with fewer "AI-isms". It's also very good at writing in your voice given the right context.
HOWEVER: Writing performance also varied with reasoning levels. Medium reasoning had higher incidence of AI-isms—we found best results with high.
- Beast at knowledge work. Opus 4.8 is very good at general knowledge work tasks like report creation, research and more. It produced the best PowerPoint one-shot we've ever seen on our deck generation benchmark.
- Emotionally intelligent, willing to question the frame. I've also found it to be quite good at talking through psychological or interpersonal issues. It has a high EQ, and it's also good at not glazing and helping to expand your perspective. Its thought process feels extremely rich and dynamic.
THE BAD:
These days a model is only as good as its harness, and Codex is still a far superior harness to the Claude Desktop app. This has kept me using Codex + GPT-5.5 as my daily driver, but I am flipping back and forth a lot more between Codex and Claude.
Anthropic is back baby!
Read the rest on @every:
https://t.co/vuORiDXkxX
We’ve updated Claude Code's built-in claude-api skill migration guidance for 4.8.
Run "/claude-api migrate" to update your model strings and suggest prompt improvements that are tuned for Opus 4.8.
Huge credit to the OAI team for solving the unit distance problem with 5.5 - it is now my go to example that models can in fact pull together disparate ideas into new discoveries.
As with all 4 minute miles, we had to try and cross it too! Turns out mythos solves it with a cute, simple proof. This implies some serious overhang in discoveries!
"For the last few months, Anthropic has used Mythos Preview to scan more than 1,000 open-source projects, which collectively underpin much of the internet—and much of our own infrastructure.
So far, Mythos Preview has found what it estimates are 6,202 high- or critical-severity vulnerabilities in these projects (out of 23,019 in total, including those it estimates as medium- or low-severity)."
https://t.co/9XzxxDFOnB
The release candidate for MCP 2026-07-28 is out. The protocol is now stateless: no handshake, no session id, any request can hit any server instance. Plus extensions as first-class (MCP Apps, Tasks), auth hardening, and a proper deprecation policy so we don't have to do this again.
https://t.co/XRLTu1BSkB
we've updated the claude-api skill to help onboard on self-hosted sandboxes.
you can invoke this in the latest version of Claude Code (with the "/claude-api" command) and ask questions.
see repo here:
https://t.co/wKlvKQDwJu
more cookbooks here:
https://t.co/WOYFBmkwHB
we just added self-hosted sandboxes to Claude Managed Agents.
i've been excited about this for a while: you can now connect many more "hands" (customizable execution environments) to the agent.
here's a few interesting articles covering what you can do ...
@vercel: use a Vercel Sandbox for fine control over both networking and credentials. Vercel runs compute inside / adjacent to your own network. lets you reach internal databases, private APIs, or services.
https://t.co/0vxiLJbYsv
Personal update: I've joined Anthropic. I think the next few years at the frontier of LLMs will be especially formative. I am very excited to join the team here and get back to R&D. I remain deeply passionate about education and plan to resume my work on it in time.
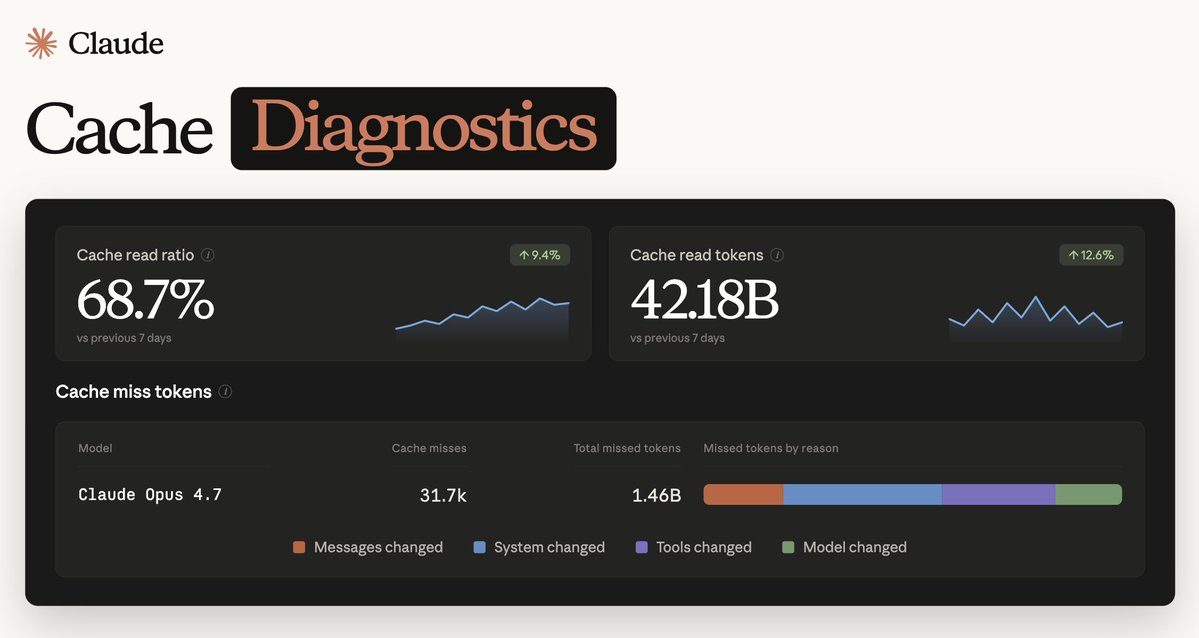
this pairs well with the claude-api skill (bundled with Claude Code).
ask Claude Code to investigate the cache misses using the diagnostics to guide.
console link:
https://t.co/02EOpLFNgm
docs:
https://t.co/eUmyBLWXkB
https://t.co/AnImwG6ojk
Claude Code ships with a built-in skill for working with the Claude Platform.
Useful for model migrations, using API features (e.g., prompt caching), or onboarding to newer APIs like Claude Managed Agents.