You can now run 70B LLMs on a 4GB GPU.
AirLLM just made massive models usable on low-memory hardware.
𝗪𝗵𝗮𝘁 𝗷𝘂𝘀𝘁 𝗵𝗮𝗽𝗽𝗲𝗻𝗲𝗱
AirLLM released memory-optimized inference for large language models.
It runs 70B models on 4GB VRAM.
It can even run 405B Llama 3.1 on 8GB VRAM.
𝗛𝗼𝘄 𝗶𝘁 𝘄𝗼𝗿𝗸𝘀
AirLLM loads models one layer at a time.
Instead of loading everything:
→ Load a layer
→ Run computation
→ Free memory
→ Load the next layer
This keeps GPU memory usage extremely low.
𝗞𝗲𝘆 𝗱𝗲𝘁𝗮𝗶𝗹𝘀
• No quantization required by default
• Optional 4-bit or 8-bit weight compression
• Same API as Hugging Face Transformers
• Supports CPU and GPU inference
• Works on Linux and macOS Apple Silicon
𝗪𝗵𝗮𝘁 𝘆𝗼𝘂 𝗰𝗮𝗻 𝗱𝗼
• Run Llama, Qwen, Mistral, Mixtral locally
• Test large models without cloud GPUs
• Prototype agents on cheap hardware
NVIDIA just removed one of the biggest friction points in Voice AI.
PersonaPlex-7B is an open-source, full-duplex conversational model.
Free, open source (MIT), with open model weights on @huggingface 🤗
Links to repo and weights in 🧵↓
The traditional ASR → LLM → TTS pipeline forces rigid turn-taking.
It’s efficient, but it never feels natural.
PersonaPlex-7B changes that.
This @nvidia model can listen and speak at the same time.
It runs directly on continuous audio tokens with a dual-stream transformer, generating text and audio in parallel instead of passing control between components.
That unlocks:
→ instant back-channel responses
→ interruptions that feel human
→ real conversational rhythm
Persona control is fully zero-shot!
If you’re building low-latency assistants or support agents, this is a big step forward 🔥
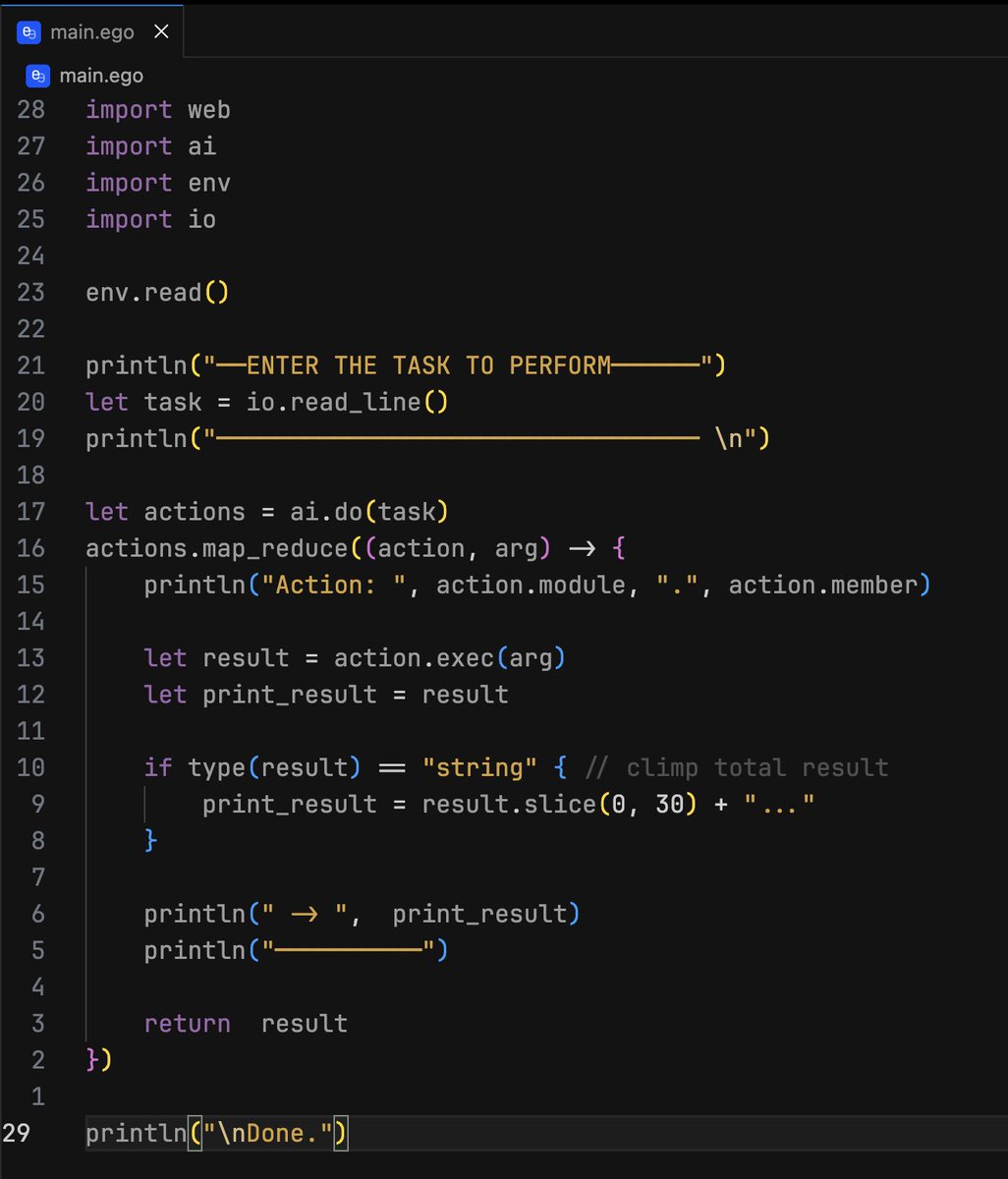
the last months i've been working on 'self', a virtual machine with native AI integration at both the instruction-set level and the stdlib level.
it has its own language, and the demo below takes under 30 lines to write.
more details at https://t.co/nbK9L8P7VQ
BREAKING:
🇨🇭🇺🇲 Switzerland REJECTS Palantir Software
Palantir Software Poses Devastating Risks - Netz Politik
After a risk assessment of the use of Palantir software in Switzerland, the US corporation was rejected, despite years of courting by authorities and the army. The Swiss consider the risks too great.
The fear is that Palantir is handing over sensitive data to the US and from there to Israel.
@jarredsumner Hey jarred, are there open roles at bun?
I’m 20, working at different startups for the past 4 years.
Built “self” a virtual machine built in rust with native AI integration as part of the instruction set.
Speaker at community events
Everything at https://t.co/DzxHKO6XM9
@rauchg@vercel i really think mcp it’s not that bold, it’s only a client server contract. It even does not enforce you a transport layer. It only exposes what you can do, or what you can consume.
In fact, without LLM’s it’s something like a functions discovery service
@carla0st @_buildspace@_nightsweekends awesome idea 🔥
when i am on the street with the headset i open chatgpt 4o and start talking to him with the phone in my pocket. the point of this is, how to handle the end of the statements and how to interrupt the process if you said something wrong, without using the screen on
Elon Musk fired 80% of Twitter (6500 people) and everyone thought that Twitter was doomed.
He was right. Everyone was wrong.
It’s the management masterclass of the decade and every entrepreneur must understand why it worked 🧵: