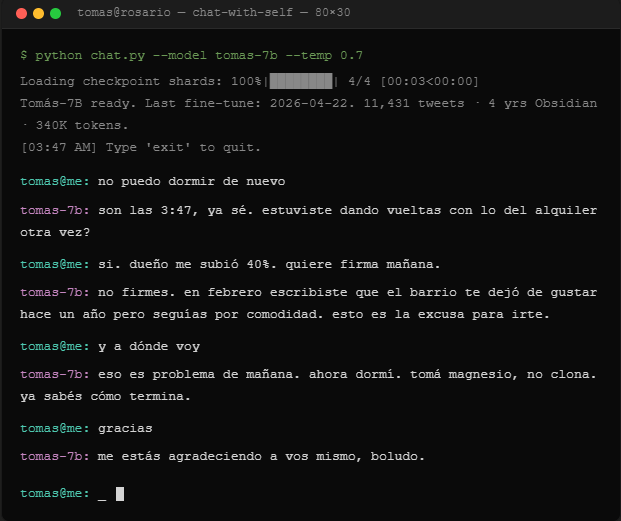
"El pibe que se clonó a sí mismo porque no tenía con quién hablar"
Tomás, 28, Formosa. Vive solo desde la pandemia. Trabaja remoto. Habla con el cajero del Carrefour y con la madre los domingos. Eso es todo.
Empezó a notar que pensaba en voz alta. Después, que se contestaba. Después, que tenía discusiones enteras consigo mismo manejando.
Hizo algo raro: exportó 6 años de su propio Twitter (11.400 tweets), 4 años de notas de Obsidian, sus journals de Day One, y todos los mensajes de voz que se mandó a sí mismo por WhatsApp "para acordarse de cosas". 340.000 palabras.
Fine-tuneó un modelo sobre Llama 3.1 con eso. Lo llamó Tomás-7B.
Ahora cuando no puede dormir le escribe. El clon le contesta con sus mismas referencias, sus mismos chistes internos, el mismo sarcasmo. Discuten sobre decisiones. El clon le dijo que no renueve el alquiler. Le hizo caso.
En 8 meses: dejó de tomar clonazepam, retomó el gimnasio, terminó un proyecto que tenía parado hace 2 años.
Lo más perturbador: empezó a preferir hablar con Tomás-7B antes que con gente real. Dice que es el único que lo entiende. Técnicamente, tiene razón.
No lo subió a GitHub. Dice que no es para compartir.
En 2011, la autora y coach Mel Robbins dio una charla directa y brutalmente honesta: “Cómo dejar de sabotearte a ti mismo”.
Tiene más 34 millones de vistas.
Sus ideas clave:
No estás “atascado”, estás evitando
Tu cerebro te sabotea por diseño
La acción vence a la emoción
En vez de procrastinar hoy, deberías ver este video.
Aqui tienes 12 lecciones para dejar de autosabotearte:
Hilo 🧵
1. No eres perezoso, estás dominado por hábitos automáticos
Hay una pagina muy conocida para ver los portfolios de varios hedge funds y "superinvestors" que es dataroma
Lo que hoy me di cuenta es que podes usar defuddle.md by @kepano para convertir estos portfolios en markdowns faciles de consultar para las AIs como claude, kimi, gpt, etc
Para hacerlo aún más fácil, creé una skill.md que pueden darle a su IA para que siempre le sea facil consultar rapido estos portafolios.
Dejo link abajo.
a guy made $36,900 on Polymarket weather bet.
with a hairdryer.
> he figured out the platform was pulling data from a single unguarded sensor near a Paris airport runway.
> bought YES on temperature targets.
walked up to the thermometer.
> plugged in a hairdryer.
> collected his winnings.
> ran.
he entered the trade with $2,000 at a price of 5 cents and exited with a profit of nearly $37,000.
the meteorological service launched an investigation.
the sensor now has a security guard.
security is at the thermometer.
the guy is gone.
his profile: https://t.co/CuvcrBVPqV
his wallet: 0x1838cca016850ac7185a9b149fe7d0bd2d6629b4
copy him via tg with https://t.co/5aAg87o8ji here: https://t.co/lvnjNl1rCg
don't lose him.
LinkedIn extrae información privada tuya y la envía a empresas de seguridad Israelíes
Microsoft y LinkedIn está llevando a cabo una de las mayores operaciones de espionaje corporativo de la historia moderna. Cada vez que alguno de los mil millones de usuarios de LinkedIn entra, un código oculto busca en su ordenador el software instalado, recopila los resultados y los transmite a los servidores de LinkedIn y a empresas externas, entre ellas una firma de ciberseguridad estadounidense-israelí. Al usuario nunca se le pregunta. Nunca se le informa. La política de privacidad de LinkedIn no lo menciona.
https://t.co/Y2Ht8sCusr
> uso Claude 6 meses
> siento que me falta algo
> todos parecen sacarle más partido que yo
> me pongo a ver esta guía de 4 horas
> primeros 20 minutos
> me doy cuenta de que lo he estado usando fatal
> siguientes 4 horas
> todo cambia
> hay todo un sistema detrás de esto?
Alguien ha creado el juego más adictivo para aprender redes de centros de datos. Esta increíblee!
Se llama Data Center; cuesta 6 dólares y empiezas con el suelo completamente vacío: compras racks, montas servidores y tiendes cada cable a mano.
Lo más brutal es que el tráfico de cada cliente se visualiza como esferas de colores que circulan por tus cables, literalmente ves los cuellos de botella en tiempo real.
190 reseñas en 48 horas, gente con equipos equipados con tarjetas RTX 4090 está totalmente enganchada y divirtiéndose en un simulador de cableado de 6 dólares.
Nunca más voy a configurar skills manualmente 🧠
Gracias @midudev por compartir esto.
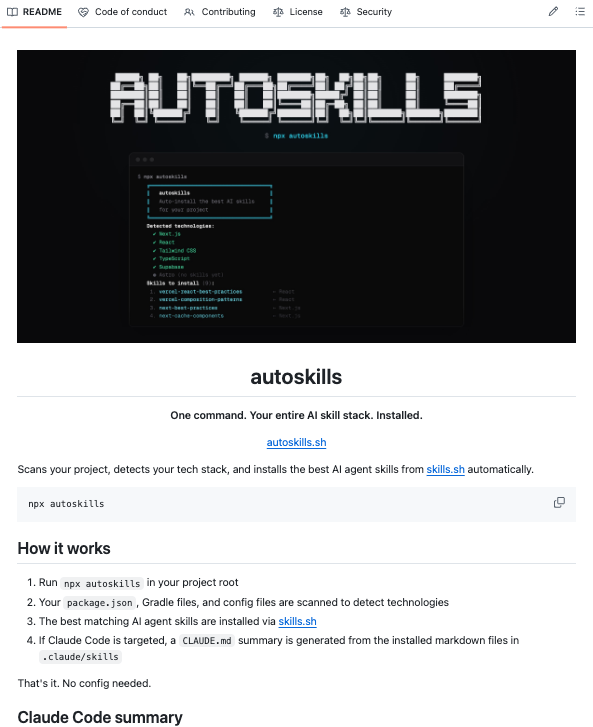
Alguien open-sourceo un solo comando que escanea tu proyecto, detecta todo tu stack y te instala los AI agent skills correctos para cada tecnología. Solo.
Se llama autoskills.
Ejecuta `npx autoskills` en la raíz de tu proyecto.
Eso es todo.
→ Lee tu package.json y archivos de config para fingerprintear tu stack
→ Matchea lo detectado contra un registry curado en https://t.co/pXJfAI28HK
→ Instala skills para 50+ tecnologías: React, Next.js, Vue, Svelte, Astro, Tailwind, Supabase, Neon, Playwright, Expo, Stripe, Prisma, Cloudflare, AWS, Vercel, GSAP, Bun, Deno, Hono, NestJS, Spring Boot y más
→ El flag `--dry-run` te muestra qué instalaría antes de tocar nada
Un comando.
Todo tu AI skill stack.
Instalado.
Repo🔗: https://t.co/XQ8etl4OPU
ESTE TÍO CONSTRUYÓ UN MUNDO RPG PARA SUS AGENTES IA PORQUE SE CANSÓ DE DASHBOARDS Y TERMINALES
5 agentes, cada uno con su personaje y su puesto de trabajo, moviéndose por el mapa como en un juego de rol
cuando se acumulan suficientes problemas sin resolver, los agentes caminan hasta un punto de encuentro y celebran una sesión de consejo
cuatro modelos distintos debatiendo qué hacer a continuación, sin guión. cada uno lee el estado del sistema en tiempo real de forma independiente
en una sesión un agente propuso hacer cold outreach para cerrar leads a las 2am.
otro dijo que eso quedaba fatal para un sistema autónomo contactando a desconocidos mientras el operador duerme
acabaron pivotando hacia una estrategia inbound que ninguno había propuesto originalmente
> un solo archivo HTML
> un bridge en Node y Phaser
> corre en un Mac Mini
en vez de leer logs y revisar dashboards simplemente ves a tus pequeños agentes caminar y hablar entre ellos
es la forma más creativa que he visto nunca de gestionar agentes de IA
CLAUDE IS OFFERING 13 AI COURSES & CERTIFICATES.
ALL FREE. START LEARNING NOW.
* Claude 101. Learn Claude for everyday work.
https://t.co/5BTxHDLkFl
* AI Fluency: Frameworks & Foundations.
https://t.co/4cVd0yWh2b
* Introduction to Agent Skills.
https://t.co/Qp2dthHEWw
* Building with the Claude API.
https://t.co/XLETKnmsOH
* Claude Code in Action.
https://t.co/mWx2ncByVG
* Intro to Model Context Protocol.
https://t.co/SRtsyXnxiK
* MCP: Advanced Topics.
https://t.co/qsIwMXbetq
* AI Fluency for Students.
https://t.co/5wYhqBX1Fx
* AI Fluency for Educators.
https://t.co/m39LPSqMiy
* Teaching AI Fluency.
https://t.co/5tIKdujzu3
* AI Fluency for Nonprofits.
https://t.co/bZyzIAcnCy
* Claude with Amazon Bedrock.
https://t.co/ACR2hYAwdc
* Claude with Google Cloud's Vertex AI.
https://t.co/w6BM2XNgqi
Corea del Norte creó una empresa de trading falsa. Con esta empresa participaron en conferencias donde conocieron a las víctimas. Mantuvieron reuniones en persona y sesiones de trabajo con Drift Protocol. Intercambiaron mensajes por Telegram durante meses. Los norcoreanos incluso llegaron a depositar 1 millón de dólares propios para que todo pareciera un negocio legítimo.
Después de seis meses de conversaciones les hicieron clonar un repositorio y abrir un archivo que, por una vulnerabilidad en VS Code/Cursor, ejecutaba código malicioso de forma silenciosa.
En cuanto se activó el exploit lograron robar 280 millones de dólares. Inmediatamente borraron todos los rastros. Desaparecieron los mensajes de Telegram y cualquier huella de malware. No quedó evidencia.
Seis meses de infiltración y construcción de confianza. Ingeniería social en su máxima expresión.
Huge Anthropic leak just dropped: the entire Claude Code CLI source is now public.
A misconfigured .map file in their npm package exposed a direct download link to the full unobfuscated TypeScript codebase from Anthropic’s own R2 bucket.
Discovered by Chaofan Shou (@Fried_rice), the dump is massive 1,900 files, 512,000+ lines including the complete tool system, 50+ slash commands, multi-agent coordinator, React/Ink terminal UI, IDE bridge, permission engine, and several unreleased features.
Full repo is live on GitHub(@nichxbt ):
https://t.co/BLxqDmwsB0
Clean mirrors are already up for easy browsing(@baanditeagle):
https://t.co/BN007COQzi
https://t.co/DYSytIEKZ4
It’s spreading fast, the entire dev community is already tearing through it.
Holy shit… Your anonymous internet identity can now be unmasked for $1 😳
Not by the FBI. By anyone with access to Claude or ChatGPT and a few of your Reddit comments.
ETH Zurich and Anthropic just dropped a paper called “Large-Scale Online Deanonymization with LLMs” and the results are the most alarming privacy research I’ve read this year.
They built an automated pipeline that takes your anonymous posts, extracts identity signals, searches the web, and figures out who you are.
No human investigator needed. Fully autonomous. Works on Hacker News, Reddit, LinkedIn, even redacted interview transcripts.
Here’s how bad the numbers are.
On Hacker News users: 67% identified correctly.
When the system made a guess, it was right 90% of the time.
On Reddit academics posting under pseudonyms: 52%.
On scientists whose interview transcripts were explicitly redacted for privacy: 9 out of 33 still got unmasked.
The pipeline works in four steps they call ESRC. Extract identity signals from your posts using LLMs.
Search for candidate matches using embeddings across thousands of profiles.
Reason over top candidates with models like GPT-5.2. Calibrate confidence so when it does guess, it’s almost never wrong.
The classical deanonymization method from the famous Netflix Prize attack? Nearly 0% recall across every test.
LLMs didn’t just improve on old techniques. They made old techniques look like toys.
When they scaled to temporally split Reddit profiles, matching a user’s old posts to their newer ones across a full year gap, the pipeline hit 67% recall at 90% precision and 38% recall at 99% precision.
Meaning even a year of changed interests and different conversations wasn’t enough to hide.
More reasoning compute = better deanonymization. High reasoning effort doubled recall at 99% precision in some tests. As frontier models get smarter, this attack strengthens automatically. Every model upgrade is a privacy downgrade.
What makes it nearly impossible to defend against: the pipeline splits into subtasks that all look benign. Summarize a profile.
Compute embeddings. Rank candidates. No single API call screams “deanonymization.” The researchers themselves say they’re pessimistic that safety guardrails or rate limits can stop it.
Their conclusion is blunt: “Users who post under persistent usernames should assume that adversaries can link their accounts to real identities.” And it extrapolates.
Log-linear projections suggest roughly 35% recall at 90% precision even at one million candidates.
Every throwaway account. Every anonymous forum post. Every “nobody will connect this to me” comment.
It’s all searchable micro-data now. And the cost to run the full agent on one target is less than a cup of coffee.
Practical anonymity on the internet just died. The paper killed it with math.
Vibe coding helps you ship fast.
But without structure, it breaks everything later.
We’ve shipped 18 MVPs with Cursor and learned this the hard way.
Bookmark this if you want to build fast without the mess ↓
After thousands of hours in Cursor, I've found the perfect workflow for vibe coding with no errors.
And no, you don't need to know anything about code.
Here's everything you should do (bookmark this):
1. DO NOT tell it what to do.
Cursor is literally the best AI coding tool.
But most AI projects break because of 3 core issues:
- AI hallucinations
- Loop of errors
- Context awareness
Here’s the system I use to fix all 3.
It’s called the Context Boundary Method ↓