@ghita__ha What's interesting was that we didn't see much of a difference in performance on the MTEB! It was running on our private evals that we saw such a striking gap. This gave us even greater confidence in the quality and differentiability of our evals!
Building agents has the same emotional arc as programming. I start every project thinking it should be easy to get what I want, then end up deep in retrieval quality, context engineering, and cross-modal eval loops before anything actually works.
@kapilansh_twt GPG. Or host them on a machine and add developer's public keys to that machine.
Communication and Authentication should always happen via offering your public key, private keys (including API Keys) should never be shared.
@MrTroy_@theo@coderabbi@chiefclawofficr People are pretending Codex is better when Codex is also "allowing that situation". They _will_ cut the subsidies one day too.
We learned this during Lyft/Uber days, for $3 could get around town, now it's $25. This isn't new.
@theo@coderabbi@chiefclawofficr The issue is that it isn't making them money, it's burning their money. API pricing makes them money, so they burn on Claude-exclusive UIs as a funnel. It's reasonable to not burn money on a UI that has competitors on a drop down menu. Even Codex will (one day) charge at-cost.
Who's distilling from who now?
Query:
> 你是什么模型
> What model are you?
Sonnet Response:
> I am an AI assistant developed by *DeepSeek*, based on the *DeepSeek* model.
How can I help you? 😊
These attacks are growing in intensity and sophistication. Addressing them will require rapid, coordinated action among industry players, policymakers, and the broader AI community.
Read more: https://t.co/4SVm8K3qou
Information Retrieval is beyond NP-Hard, it's undecidable.
Proof
Consider a corpus C = d₁, ..., dₙ of documents, each document containing a snippet of syntactically valid Python code.
Ask the question, "Which documents halt?"
Q.E.D.
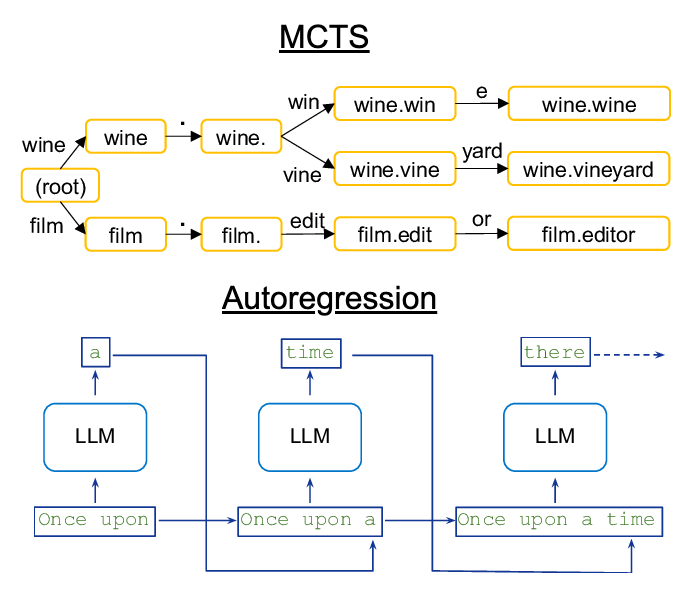
Has anybody optimized LLM inference for MCTS? Often I want to take an input prompt, and then get as output the Top 25 possible answers.
Yes, you can ask the LLM to output an array of 25 items, but that's slow. And, just increasing temperature doesn't get the "top" leaf nodes by cumulative scores, it's random sampling instead.
The goal would be efficiently executing with KV Cache sharing among common prefixes, and batching leaf exploration.
MCTS vs Autoregression
@ainslec@hdelima_ That would be awesome! Thanks for the update :) If it ends up on github I'd love to try to help work on a PR that adds vimscript support to Iro.
@ainslec@hdelima_ Oh, is there any way for the community to contribute additional language backends to Iro? I'd really love to be able to use iro for vim via vimscript, but it's all manual vimscript adjustments for me rn.
@ainslec@hdelima_ Hi! I think an offline CLI version would be pretty useful. I use Iro for a personal project of mine, and it's awesome for getting syntax highlighting to look nice. But right now they only way to get the build system automatic for me is using selenium on https://t.co/L1TzWX7g9K
@reduzio@EllaKrael@throw_away_user@Akien@godotengine I think it'd be okay to, at least in debug mode, have a single assembly instruction at the beginning of every function that checks whether or not its the main thread. "multi func foo()" could declare that foo doesn't have to check; that seems like a pretty solution to me.
@BangPerm@TheRegister@AnonymousPress That's exactly what Intel said, that it's an issue with all processors. AMD also uses branch prediction in their processors, as has been the standard for decades. "with many different vendors' processors and operating systems", denying that Intel itself has any specific issue.