Can an inexpensive, off-the-shelf IMU be the only sensor to estimate the full state (position, velocity, orientation) of a quadrotor flying through a track at high speed and even be on-pair with vision-based localization? The answer is yes, within certain limitations! In this #RAL2023 paper, we propose a learning-based odometry algorithm that couples a model-based filter driven by the inertial measurements with a learning-based module with access to the control commands. Our system outperforms by a large margin the state-of-the-art visual-inertial odometry (#VIO) algorithms and the state-of-the-art learned-inertial odometry algorithm, #TLIO, for the task of drone racing. Additionally, we show that our system is as accurate as a VIO algorithm that uses a camera to localize to a known map of the racing track. The main limitation of our approach is that it cannot generalize to trajectories that have not been seen at training time. However, in drone racing competitions, the track is known beforehand. Human pilots spend hours or even days of practice on the race track before the competition. Similarly, our system can be trained with the data collected during practice time and deployed during the competition. Future work will investigate how to generalize to trajectories not seen at training time. The code is released!
Paper: https://t.co/4DXLYAYGMc
Video: https://t.co/gsrtZmKo5z
Code: https://t.co/Gmkn30afrO
Kudos to @giov_cioffi@l_bauersfeld@kaufmann_elia@ERC_Research@UZH_en@UZH_Science@UZHspacehub@nccrrobotics@aerialcore #RAL2023 #IROS2023 #SLAM
well, fvck it. this can give you sota, better than sqlcoder-15b. also im broke after churning out such high quality examples and picking 1% out of millions of samples (gen'd gpt4).
the seed tasks take days, weeks to complete--if you are working alone lol
https://t.co/yWJMUVJY3w
Language is the future for how we interact with robots.
Today @wayve_ai is sharing a first look at LINGO-1, a new vision-language-action AI model. To give you a glimpse of its capabilities, here is a video of me playing with LINGO-1 yesterday morning.
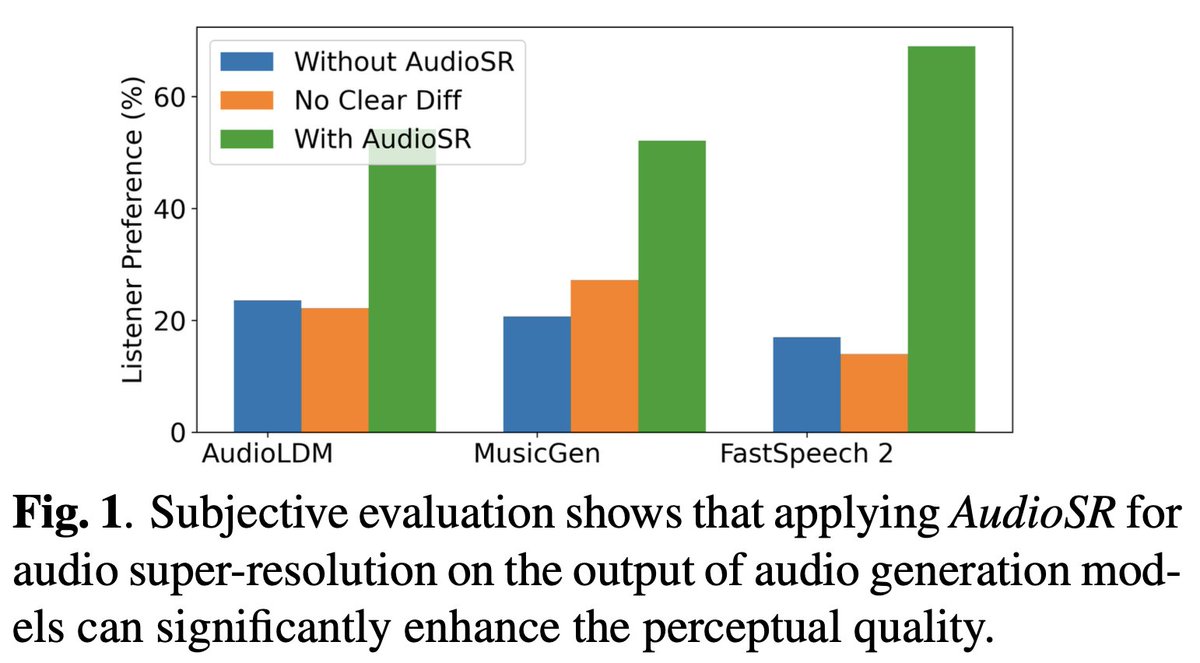
🔊Introducing AudioSR: a plug-and-play & one-for-all solution to upsample your audio to stunning 48kHz quality!
👉Significant improvement verified on MusicGen (32kHz), AudioLDM (16kHz), and FastSpeech2 (22kHz)!
Demo, code, and paper: https://t.co/oeddGEtJRm
#AudioSR #SuperResolution #AudioGenerativeModels
🤗Transformers have recently (in v 4.32) added a new "text-to-audio" (alias - "text-to-speech") pipeline for easy audio generation. Generate text narration or music with just a few lines of code. Currently supported models: Bark, SpeechT5, and MusicGen https://t.co/NCAzS9bUYa
This is the way to unlock the next trillion high-quality tokens, currently frozen in textbook pixels that are not LLM-ready.
Nougat: an open-source OCR model that accurately scans books with heavy math/scientific notations. It's ages ahead of other open OCR options. Meta is doing extraordinary open-source AI, sometimes without as much fanfare as Llama.
My first serious AI research project (back @Columbia, 2012) was to convert chemical engineering PDFs into NLP-ready corpus. I still remember the immense pain of Tesseract, a much older OCR system (https://t.co/1wsKiVaP8f).
Now Nougat runs a powerful Swin Transformer backbone and blows the benchmarks out of the water. We're talking about double-digit improvements across all metrics.
Now, textbooks are all we need for the next GPT!
Website: https://t.co/bzW8XeNfYB
Open-source code: https://t.co/MY3ZhmCbX1
Paper "Nougat: Neural Optical Understanding for Academic Documents": https://t.co/3kuDICdEVE
The deeper I go into LLM use cases, the more time goes into prompt optimization.
At first, it was possible to simply document and manage a spreadsheet of prompts and generations but as you scale experiments, compare different models, document parameters, develop different prompt versions, and track other metadata, this approach becomes unsustainable.
Even when I am fine-tuning LLMs, which also requires a lot of tuning on data, I need to have a clear picture of what prompts are working and which ones aren't based on different settings.
As LLM experiments scale and use cases become more complex, the more you will rely on tools to track and debug prompts. You will need a solution that logs prompts, allows you to store metadata, and easily visualizes, navigates, and search prompt results.
I have been really impressed with the new prompting tools by @Cometml. I already use their tools for tracking and managing my fine-tuned LLMs, so it's cool to see that they also enable LLMOps and prompting tools to easily track and debug prompts at scale.
It may not be obvious right now but as we continue to improve and build on top of LLMs, you will require tools like this to manage your experiments. There is a huge good opportunity to upskill in this area of LLMOps as not too many have this skillset. It's also a good time to learn about this topic.
If you are interested, here is a nice detailed Colab notebook showcasing how to log different types of prompts like few-shot and prompt chains using Comet: https://t.co/hGyKc1daUj
Open Interpreter is amazing. It just reached 10k stars on Github in a few days.
It’s an open-source, free, and unrestricted version of OpenAI’s Code Interpreter that runs locally on your machine:
▸ Run code (Python, Javascript, Shell, and more)
▸ Create and edit photos, videos, PDFs, etc.
▸ Control a Chrome browser to perform research
▸ Plot, clean, and analyze large datasets
pip install open-interpreter
https://t.co/OlWIZpc6Lk
Object-oriented programming in under 5 minutes:
Object-oriented programming (OOP) is a programming paradigm in which programs are designed using 𝗰𝗹𝗮𝘀𝘀𝗲𝘀 𝗮𝗻𝗱 𝗼𝗯𝗷𝗲𝗰𝘁𝘀. This design allows related functions and data to be grouped together in 𝘀𝗲𝗹𝗳-𝗰𝗼𝗻𝘁𝗮𝗶𝗻𝗲𝗱 𝗮𝗻𝗱 𝗿𝗲𝘂𝘀𝗮𝗯𝗹𝗲 𝘂𝗻𝗶𝘁𝘀.
A class is a template or blueprint from which objects are made from. Classes define the properties and methods that an object can have, and objects are unique instances of a class.
For example, let's say you want to create a life simulation game where players can adopt and raise pets. You would have a "Pet" class that defines the properties of each pet (like "name" and "age"), as well as behaviors they can do (like "speak" and "eat").
You could then create objects, or instances, of this class for each specific pet. Each object could have its own values for each property. For example, you could have a 2-year-old pet named "Winston", & a 1-year-old pet named "Wesley"; both initialized from the "Pet" class.
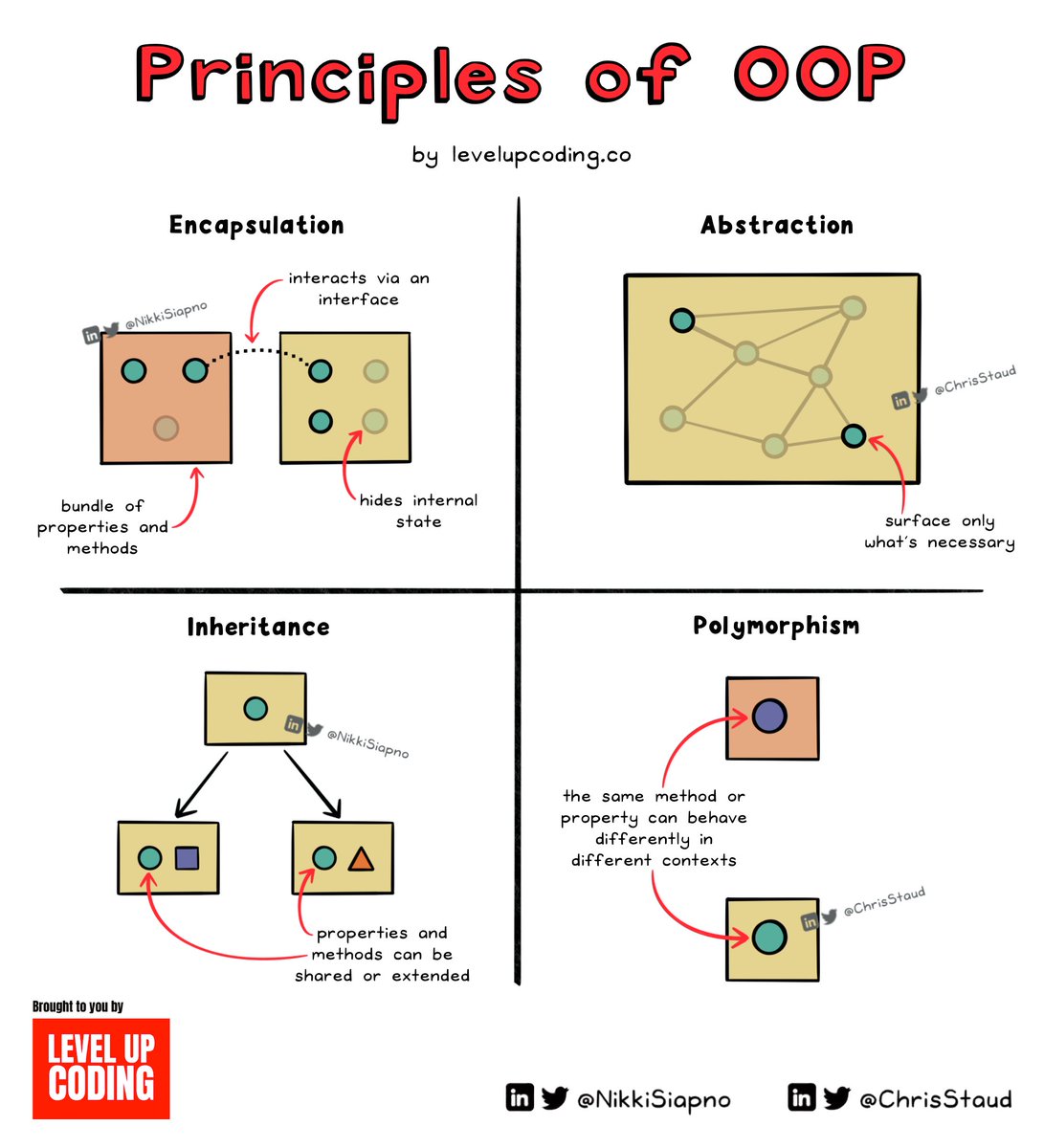
𝗢𝗯𝗷𝗲𝗰𝘁-𝗼𝗿𝗶𝗲𝗻𝘁𝗲𝗱 𝗽𝗿𝗼𝗴𝗿𝗮𝗺𝗺𝗶𝗻𝗴 𝗵𝗮𝘀 𝟰 𝗺𝗮𝗶𝗻 𝗽𝗿𝗶𝗻𝗰𝗶𝗽𝗹𝗲𝘀; 𝗲𝗻𝗰𝗮𝗽𝘀𝘂𝗹𝗮𝘁𝗶𝗼𝗻, 𝗶𝗻𝗵𝗲𝗿𝗶𝘁𝗮𝗻𝗰𝗲, 𝗮𝗯𝘀𝘁𝗿𝗮𝗰𝘁𝗶𝗼𝗻, 𝗮𝗻𝗱 𝗽𝗼𝗹𝘆𝗺𝗼𝗿𝗽𝗵𝗶𝘀𝗺.
𝗘𝗻𝗰𝗮𝗽𝘀𝘂𝗹𝗮𝘁𝗶𝗼𝗻 hides internal details but exposes data & methods via a public interface, preventing unintentional changes. E.g. — a player can view a pet's age but can't accidentally change it. But they can run methods avail on the public interface like changing a pet's name.
𝗜𝗻𝗵𝗲𝗿𝗶𝘁𝗮𝗻𝗰𝗲 allows classes to inherit properties and methods from other classes, making code reusable and organized. E.g. — A "SuperPet" class that extends from "Pet "and would inherit "age", "name", "eat", and "speak"; while defining new behaviors like "fly"
𝗣𝗼𝗹𝘆𝗺𝗼𝗿𝗽𝗵𝗶𝘀𝗺 is a principle that enables objects to change their form by extending or overriding existing methods. E.g. A "Dog" & "Cat" class that extended from the "Pet", shouldn't share the same "speak" method. You'd override it to have its own logic like "woof" or "meow"
𝗔𝗯𝘀𝘁𝗿𝗮𝗰𝘁𝗶𝗼𝗻 reduces complexity by only surfacing the information needed for a given context or use case. E.g. A “Player” class doesn’t need to know how the “eat” method works in the “Pet” class, it just needs to know how to interact with it — i.e. its input and output.
OOP provides a way to design your program that makes it 𝗿𝗲𝘂𝘀𝗮𝗯𝗹𝗲, 𝘀𝗲𝗰𝘂𝗿𝗲, 𝘀𝘁𝗮𝗯𝗹𝗲, 𝗮𝗻𝗱 𝗲𝗮𝘀𝘆 𝘁𝗼 𝘂𝗻𝗱����𝗿𝘀𝘁𝗮𝗻𝗱. But it isn't without disadvantages. A couple of arguments against it are that it can lead to over-engineering and complexity on a large scale.