🎉 🎉🎉 NuMind (YC S22) is OUT! 🎉🎉🎉
After a long R&D phase, we are finally coming out of private beta! 😀
Here is a presentation video & the release blog post: https://t.co/ZclK0SJEnq, https://t.co/2whheyGOVE
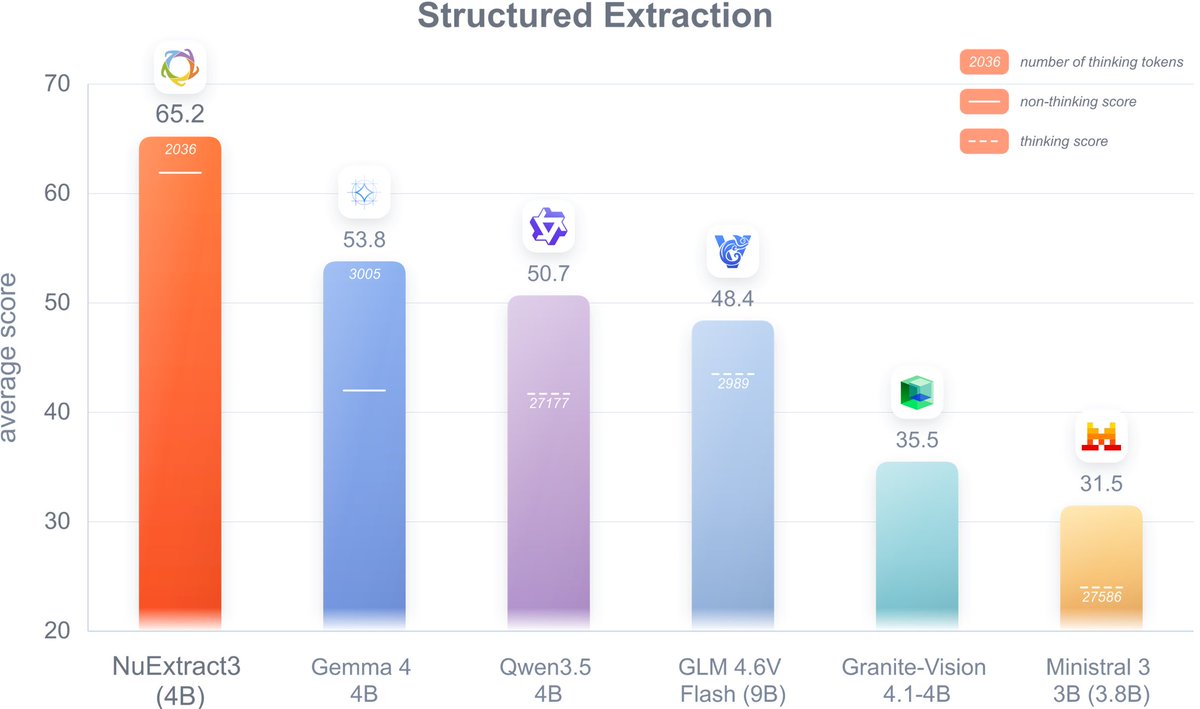
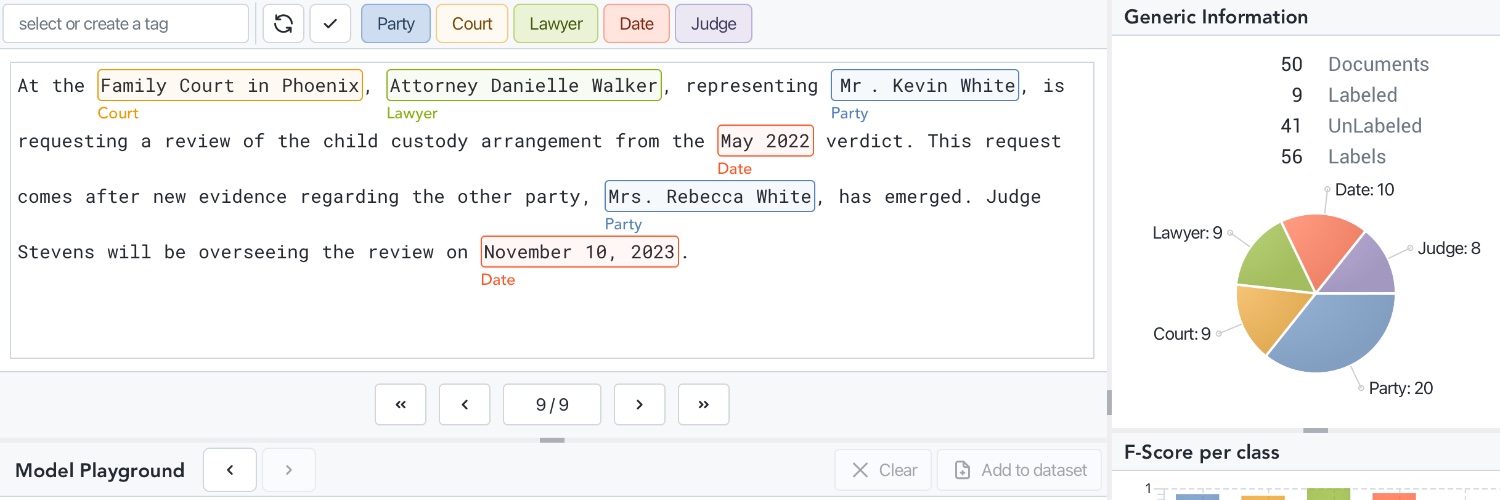
We are releasing NuExtract3, a 4B open-source (Apache 2.0) reasoning OCR & Structured Extraction VLM 🧠📷📄
NuExtract3 is the first reasoning VLM specialized in both OCR (converting PDFs/Scans/Spreadsheets into Markdown) and structured extraction (document to JSON via a schema).
We trained NuExtract3 from Qwen3.5 4B via an SFT and an RL phase to provide its reasoning abilities which can be turned on and off. We find that NuExtract3 outperforms similar size models (<30B) in both the structured and OCR tasks, including specialized OCR models, making it the new reference for open-source document extraction😀.
Congrats Alexandre Constantin, Sören Dréano, and @NathanFradet for this model! Looking forward to the Pro version :)
Available on @huggingface. Links in the reply.
🎉 🎉🎉 NuMind (YC S22) is OUT! 🎉🎉🎉
After a long R&D phase, we are finally coming out of private beta! 😀
Here is a presentation video & the release blog post: https://t.co/ZclK0SJEnq, https://t.co/2whheyGOVE
This is just a start. We are working hard to take this baby way further. We firmly believe that this "AI teaching" process is the way to go and will be the way humans create all sorts of advanced AIs.
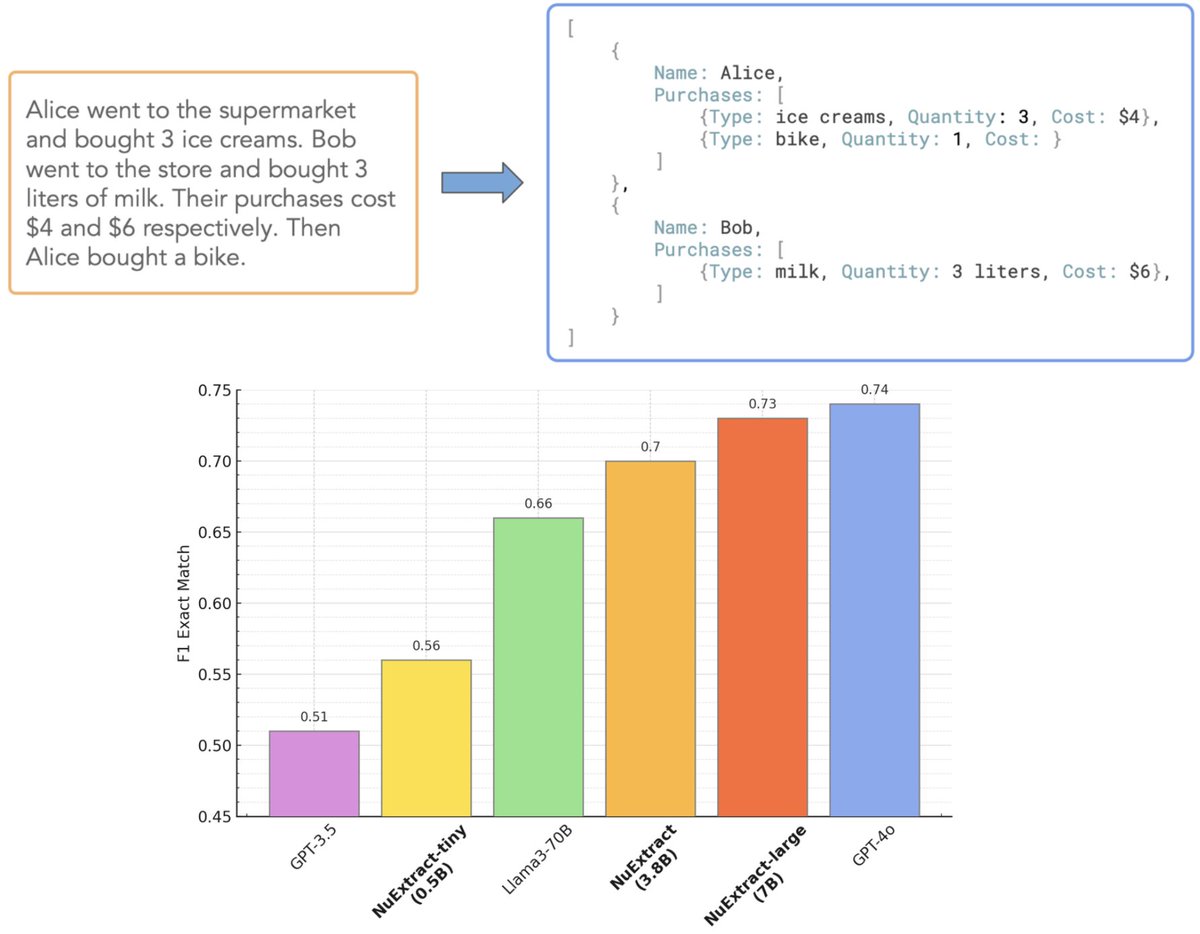
Our information extraction model NuExtract is out! A lightweight text-to-JSON LLM reaching GPT-4o levels. It is open-source (MIT licence) and available on @huggingface. Check the blog post: https://t.co/ABFCREKds2
In a nutshell, we used GPT-3.5 to annotate a part of the C4 dataset with 80k individual concepts, and then used this dataset to train the foundation model. Research done by Sergei Bogdanov (@serega6678), Alexandre Constantin, and Etienne Bernard (@etiennebcp)
Check our new open-source foundation model for Entity Recognition (NER): https://t.co/XcGgXT9pn2
It allows to create custom NER model with typically 5x (sometimes 10x!) less annotated data than before :)
Here is the blog post explaining how we created it: https://t.co/ZyreR00tWm
Hi everyone! I am starting a series of blog posts about NLP, ML, and AI. Here is the first one where I talk about how LLMs work, their history, the current state of affairs, and what we can expect next:
https://t.co/DL5wJgrnx5
Hope that is interesting/useful to some!
Some @numind_ai news: our early-access program is on! So if you have any need for text processing (topic identification, sentiment analysis, information extraction...), contact me - we will give you access to the tool and help you to make sure your NLP project is a success!