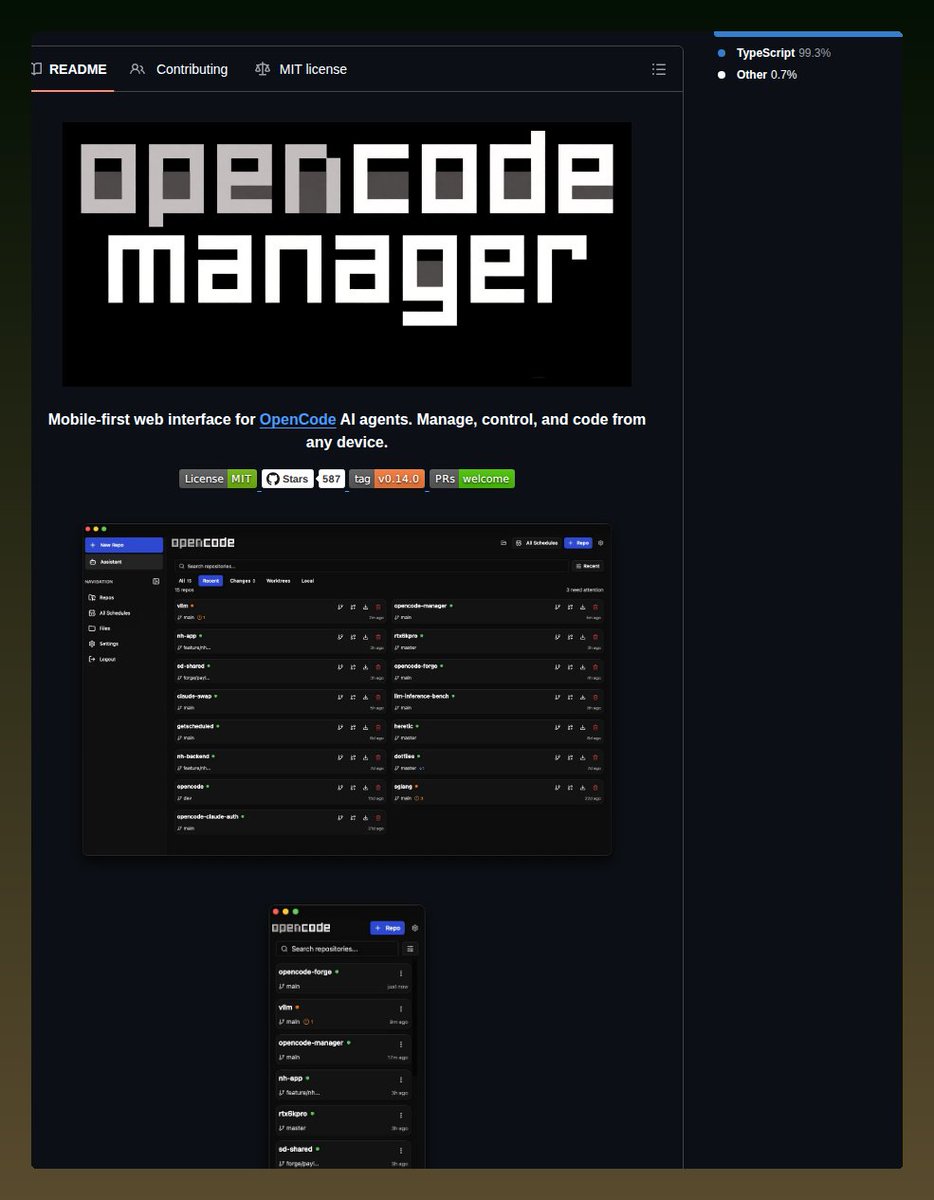
🚀 API Headers Cheat Sheet
API headers carry the metadata that powers secure and efficient communication.
📌 Authorization – Send access tokens securely
📌 Content-Type – Define the request body format
📌 Accept – Specify the expected response format
📌 User-Agent – Identify the client application
📌 Cache-Control – Manage caching behavior
📌 Origin – Support CORS validation
📌 Cookie – Send session information
📌 Accept-Language – Set language preferences
Understanding API headers helps you build faster, safer, and more reliable applications.
#API #WebDevelopment #BackendDevelopment #FullStackDevelopment #DeveloperTips
My friend makes $1.2 million a year as an Anthropic engineer.
I asked him how he learned prompting so well.
He sent me a video that was never supposed to get out. Their core team's prompting playbook.
You won’t find anything better about prompting than this video.
I watched it last night.
Halfway through, I realized I've been using Claude completely wrong for two years.
Watch it, then read the article below.
@bardanslm ngeri jadi manajer kdmp. pelatihan nggak relevan. ketika bekerja harus menanggung beban berat. hutang gede, bisnis nggak ada prospek tapi harus jalan, itupun susah nutup angsuran
Hermes /learn explained.
agents usually learn the hard way.
they struggle through a task live, fail a few times, find the path that works, and only then write down what they figured out. the lesson costs you a painful session before it becomes reusable.
Hermes Agent by Nous Research just shipped /learn, and it removes that struggle from the front.
point it at a source and it builds a skill before it has ever run the task. a local SDK directory, a docs URL, a workflow you just walked it through, or a procedure you paste in as plain notes.
it reads the material, writes a 𝗦𝗞𝗜𝗟𝗟.𝗺𝗱, tests the skill live, and saves it.
so /learn an internal REST client, tell it to focus on auth and pagination, and you get back a skill that covers exactly that, ready to invoke as a slash command.
here is the part worth understanding. Hermes already created skills on its own.
after a complex task or a recovery from a dead end, a background pass would quietly capture what it learned. that loop only fires on completed work, so it learns from trajectories the agent has already finished.
/learn is the deliberate version. you invoke it, and it learns from material the agent has never touched. docs it has not read, a repo it has not run, someone else's runbook.
the mechanism is the cleanest part. there is no separate ingestion engine.
/learn builds a standards-guided prompt and hands it to the agent as a normal turn. the agent gathers the material with tools it already has, then authors the skill and saves it through the same skill tooling.
because it is just a turn, it works everywhere the agent does. the CLI, the messaging gateways, the dashboard, with nothing new to deploy.
the advantages stack up from there.
→ onboarding collapses to one command. a private API that meant re-reading the docs every session becomes a skill your whole team invokes.
→ a repo turns into a playbook. point /learn at a codebase and it captures the patterns and workflows, so the next session starts from how to work with it.
→ a one-time walkthrough becomes repeatable. deploy the staging server once, /learn it, and the procedure outlives the session.
→ the output is verifiable. every skill ships with a verification section and gets tested live before saving, so you get a draft that already ran.
memory remembers facts. skills remember how to do the work.
/learn is the front door to the second one, and it lets you fill that store on purpose instead of waiting for the agent to earn each entry the hard way.
the best builders stopped re-teaching the agent the same procedure every session. they hand it the source once and keep the skill.
That said, if you’re looking to set up Hermes, I wrote a full deep dive covering the Hermes agent’s architecture, memory system, self-evolving skills, GEPA optimization, and how to set up multiple specialized agents.
The article is quoted below.
You can also watch my YouTube crash course on the Hermes agent: https://t.co/QjVu0FKr97
𝗟𝗮𝘁𝗲𝗻𝗰𝘆 𝘃𝘀 𝗧𝗵𝗿𝗼𝘂𝗴𝗵𝗽𝘂𝘁 𝘃𝘀 𝗕𝗮𝗻𝗱𝘄𝗶𝗱𝘁𝗵: 𝗪𝗵𝗮𝘁'𝘀 𝘁𝗵𝗲 𝗗𝗶𝗳𝗳𝗲𝗿𝗲𝗻𝗰𝗲?
"The network is slow, let's buy more bandwidth." We hear from time to time, but it rarely fixes anything. The three terms measure different things, and confusing them up leads to the wrong fix.
Here is what each one means:
𝟭. 𝗕𝗮𝗻𝗱𝘄𝗶𝗱𝘁𝗵 𝗶𝘀 𝘁𝗵𝗲 𝗰𝗲𝗶𝗹𝗶𝗻𝗴
The maximum amount of data the link can carry. A 100 Mbps connection means the pipe can move 100 megabits per second under ideal conditions. It says nothing about what we actually get (this part is important).
𝟮. 𝗧𝗵𝗿𝗼𝘂𝗴𝗵𝗽𝘂𝘁 𝗶𝘀 𝗿𝗲𝗮𝗹𝗶𝘁𝘆
Data successfully delivered per second. On that same 100 Mbps link, real throughput comes out at 62 Mbps. Packet loss, congestion, protocol overhead, and retransmissions takes the difference. This is the number that matters when we move large amounts of data.
𝟯. 𝗟𝗮𝘁𝗲𝗻𝗰𝘆 𝗶𝘀 𝘁𝗵𝗲 𝘄𝗮𝗶𝘁
How long one packet takes to get from sender to receiver. Part of it is physics, distance and the speed of light. The rest is routing hops and queues under load. A geostationary satellite link can have huge bandwidth and still feel sluggish because every round trip takes 600ms.
𝟰. 𝗪𝗵𝘆 𝘁𝗵𝗲 𝗱𝗶𝘀𝘁𝗶𝗻𝗰𝘁𝗶𝗼𝗻 𝗺𝗮𝘁𝘁𝗲𝗿𝘀
Different workloads care about different metrics. Gaming and trading need low latency, backups and streaming need throughput, and bandwidth matters only when the pipe itself is the limit. When users say an app feels slow, the first job is finding which of the three is the bottleneck.
𝟱. 𝗛𝗼𝘄 𝘁𝗵𝗲𝘆 𝗶𝗻𝘁𝗲𝗿𝗮𝗰𝘁
High latency also caps throughput. TCP waits for acknowledgments, so on a high-latency link the sender sits idle instead of pushing data. This is why a transatlantic transfer on a 1 Gbps link can be slow at a fraction of capacity.
Quick check: ping tells us latency, iperf tells us throughput, and the provider contract tells us bandwidth.
Which one do you measure first when debugging a slow system?
RUMUS TIGA LANGKAH
Jangan mulai dari nama. Jangan dari gelar. Jangan juga cerita panjang soal masa lalu.
Langsung gas dari apa yang lagi lo kerjain sekarang.
"Saat ini saya sebagai [jabatan] di [perusahaan], fokus saya di [skill utama]."
Itu cukup buat 10 detik pertama.
Lanjut satu kalimat soal pengalaman sebelumnya.
"Sebelumnya saya kerja di [bidang lama] dan di sana saya ngembangin [skill relevan]."
Terakhir, sambungin ke perusahaan mereka.
"Posisi ini menarik buat saya karena [alasan kenapa cocok sama tujuan lo]."