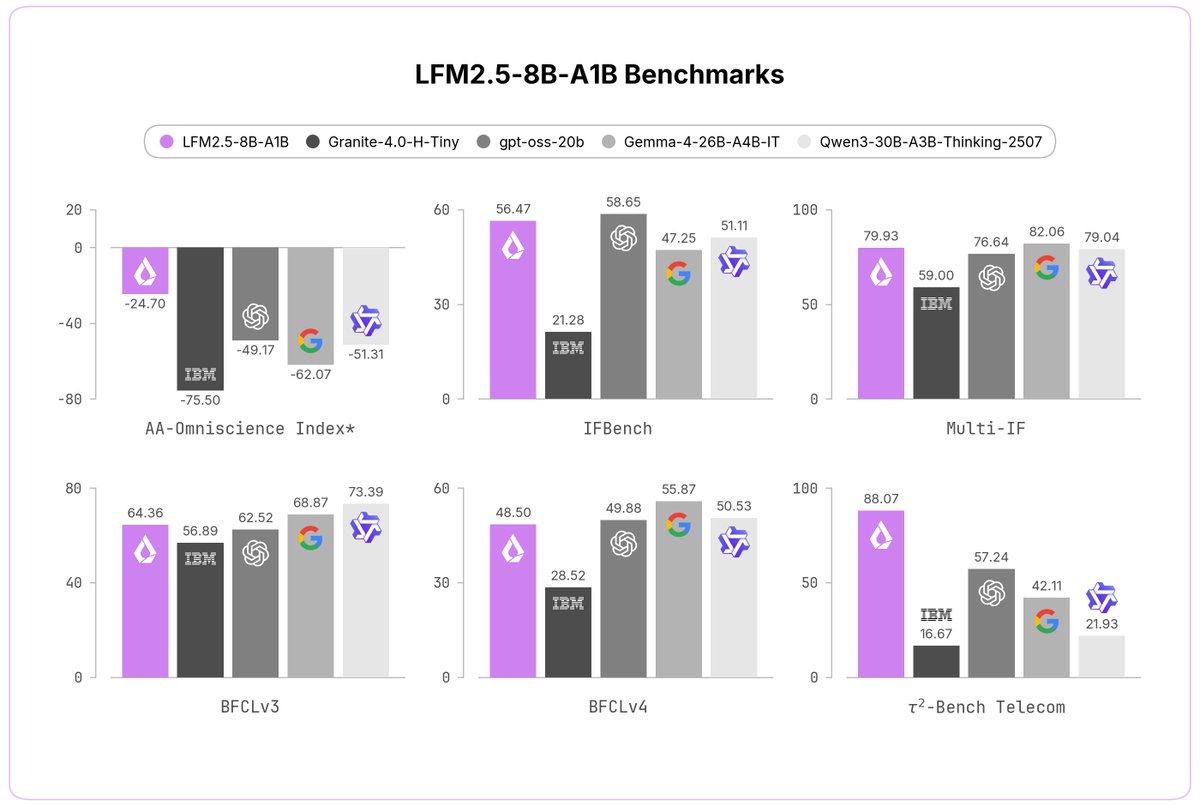
Today, we're releasing LFM2.5-8B-A1B, a device-optimized model designed to power real-life applications on phones, laptops, PCs, robots, and fast & lightweight server-side use-cases.
> 8B MoE, 1.5B active
> Expanded 128K context
> LFM2.5 flagship hybrid MoE architecture
> Trained on 38T tokens + large-scale RL
> fast, reliable tool calling, punching above its weight, comparable to models with up to 4x its size
> customizable on a single GPU for any specialized task
> LFM2 open-weight license
🧵
Effective today, we are:
1) Doubling Claude Code’s 5-hour rate limits for Pro, Max, and Team plans;
2) Removing the peak hours limit reduction on Claude Code for Pro and Max plans; and
3) Substantially raising our API rate limits for Opus models.