TL;DR: We just opened our antibody patent extractor to the entire community!
There is a strange asymmetry in antibody data.
The richest public record of what has been engineered, against which targets, and with what functional and developability characteristics are patents. And yet, that information is remarkably difficult to use.
Not because the data is missing. Because it is buried.
A patent may disclose sequences as ST.26 XML, a decades-old ST.25 sequence listing, plain text in the body, a supplementary FASTA file, or even a scanned image that requires OCR before it can be read. Numbering is inconsistent. The experimental data that gives a sequence meaning is often located in a completely different section.
Over the past several months, we focused on the harder version of this problem:
• Reading antibody sequences across all of these formats
• Correctly pairing heavy and light chains
• Resolving targets so antibodies can be compared across patents
• Extracting the functional data that matters, including binding affinity, stability, developability, epitope specificity, selectivity, in vivo efficacy, and more
Some results:
-Correctness: Our heavy/light chain pairings agree with 98% of PLAbDab's verified entries while recovering 2.8× more antibodies.*
-Evidence trail: Every target assignment, pairing, and measurement is linked back to the exact sentence or table in the source patent.
-Functional data extraction: We recover structured experimental data whenever it is disclosed, including kinetics, selectivity, stability, in vivo efficacy, epitope specificity, and other key attributes.
-Scale versus manual curation: We extract 8.7× more antibodies than expert-curated ground truth on the same patents, delivering results in pipeline runtime rather than analyst-days.**
Today, we're releasing this as a free tool to help accelerate R&D across the life sciences industry. Just paste a US, EP, or WO patent ID and get structured antibody data back. We'd love feedback from anyone working with antibody patents.
Try it here: https://t.co/UEdMHzZK1w
*Based on a comparative analysis of more than 500 patents against PLAbDab.
**Based on comparisons with internal expert manual curation across eight patents.
We’re excited to share that @Converge_Bio has entered into a multi-year collaboration with the @gatesfoundation, including a $2.5M grant to harness our AI-powered virtual cell capabilities for the research of crop genomics.
It’s a privilege to help pioneer the next generation of foundation models for the molecular world and apply them to challenges that can impact global health and food security.
Landed in Boston yesterday.
First time.
American Memorial Day.
37,000 flags on the Common. One for every Massachusetts service member who fell since the Revolutionary War. Planted by hand.
Walked through at sunset.
Thank you for our freedom. 🇺🇸
Eli Lilly's weight loss drugs are generating roughly the same revenue as ChatGPT and Claude combined.
All three products launched within a 10-month window of each other (May 2022 to March 2023).
Today's annualized run rates:
Lilly's Mounjaro + Zepbound: $51B
ChatGPT + Claude: $55B
But revenue alone misses the real story. Look at the margins.
ChatGPT and Claude are running at roughly 40% to 50% gross margins, with energy and hardware costs showing no signs of coming down. Lilly, by contrast, is operating at approximately 80% margins.
Translating that to expected annual gross profit: Lilly's Mounjaro + Zepbound: $40B ChatGPT + Claude: $22B
Despite all the hype around Generative AI (and trust me, I'm hyped), it's striking that a single drug class from a single company is generating nearly double the profit of the two most prominent AI labs combined.
New case study: ConvergeCELL™ tackles multiple myeloma zero-shot.
https://t.co/9Bw7qi0qYc
Highlights:
• AUROC 0.72 active vs. precursor MM (baselines: ~0.41–0.50)
• 3 of 4 major MM immunotherapy targets ranked in the top 1% (BCMA #3, CXCR4 #28, SLAMF7 #154)
I refuse to mix Shakespeare with amino acids. “Chatty” bio‑LLMs waste model weights on English tokens or bolt giant chat heads onto protein models. Use lean tools like ESM‑2 for folds and ProtGPT‑2 for design, then add a tiny LLM to use the output. Stop paying for bloated prose.
...application paradigms. Because users accept this latency, the 'AI chatbot' emerges as a viable front-end for increasingly complex tasks, even entire apps. This tolerance for non-instantaneity fundamentally reshapes product design & architecture. (2/2)
What's a critical, often overlooked factor boosting large AI models? User patience. Accepting latency cuts real-time infra needs, simplifying engineering & costs dramatically. This fundamental shift enables new... (1/2)
🎙️ Excited to share my recent conversation with Ben from @TheSaaSCFO on his podcast! We dive into the future of biotech and our work at @Converge_Bio .
Tune in here:
🍏 Apple Podcasts:https://t.co/n1EPIfxSIk
🎧 Spotify: https://t.co/2XyIMOio8s
Converge Bio uses #GenerativeAI for de novo & guided antibody generation, optimizing binding, developability & specificity. We're building the future of ethical, efficient antibody discovery.
Wondering how to leverage this for your org? Let's talk! Reach out to us.
#Pharma
FDA shifts from animal testing for mAbs & drugs!
New roadmap embraces AI models & human-based NAMs for safety. Huge step for ethics & faster dev!
But what if GenAI could generate antibodies too, not just test them? Combine FDA's move + AI design = skip animal use entirely!
Imagine: ✅ Less animal use ✅ Faster discovery pipelines ✅ Better therapeutic candidates.
This convergence of regulatory change (see FDA roadmap) & #GenerativeAI tech is revolutionizing drug development.
At @Converge_Bio we are building AI-powered solutions across the entire drug life cycle, from R&D to production, such as binder design, transcript optimization target discovery, and drug MoC with RNA single-cell sequencing
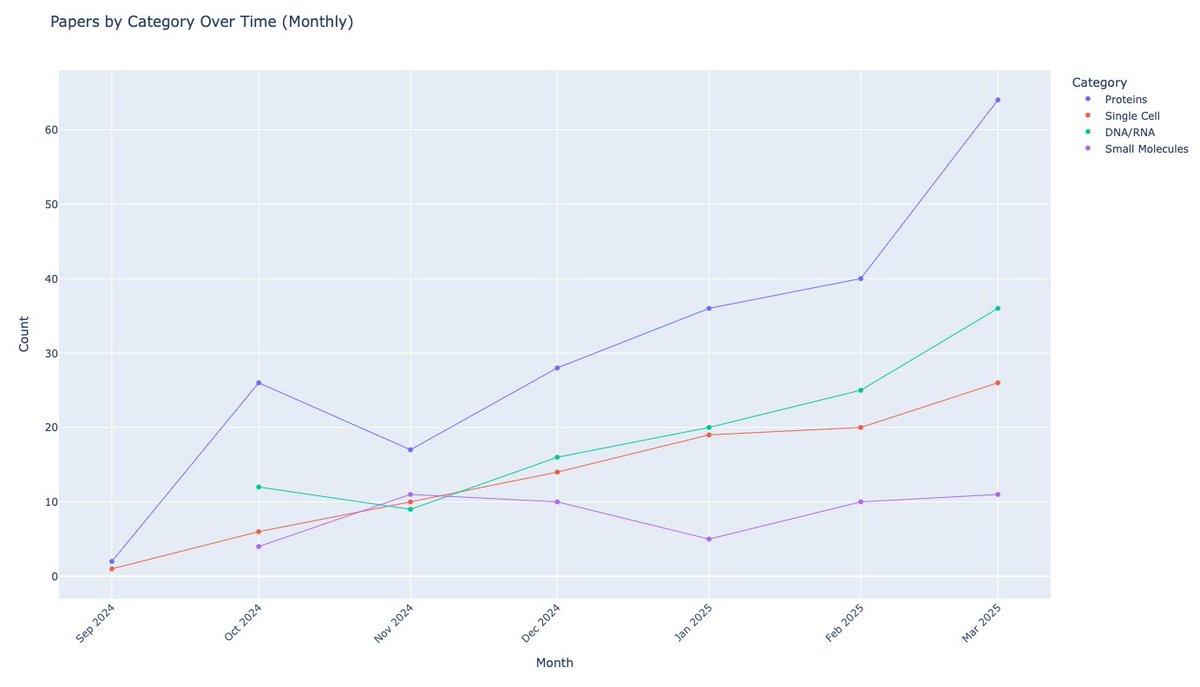
I'm amazed to see just how much the AI x Bio trend is accelerating.
Models & datasets on Hugging Face are growing fast across DNA/RNA, proteins, small molecules & single-cell.
At @Converge_Bio, we build solutions powered by biological foundation models applied to real R&D.