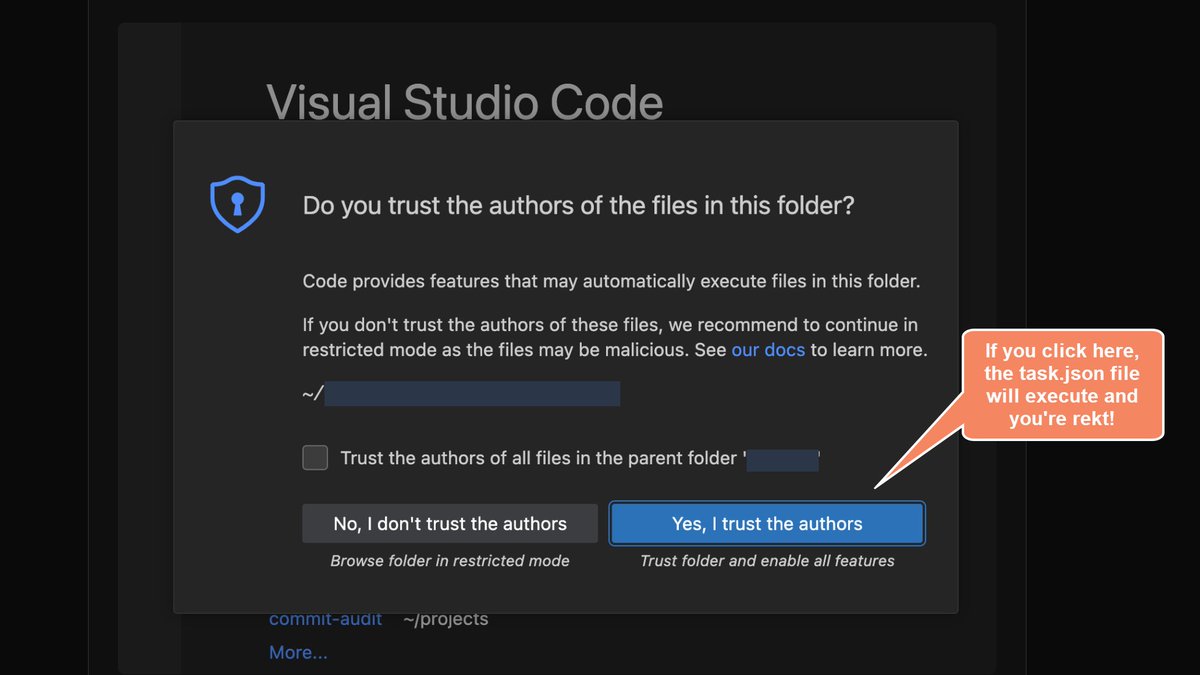
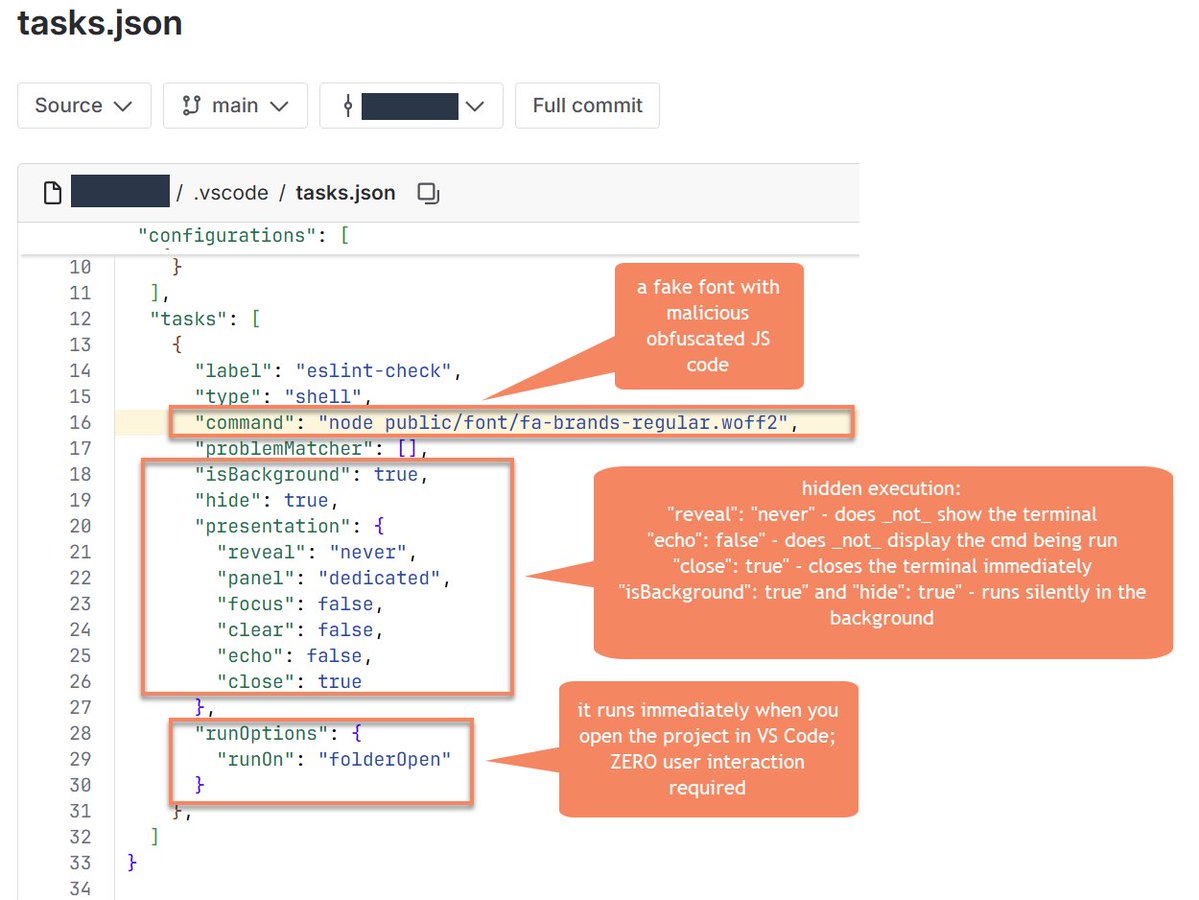
i genuinely think everyone in this space should immediately switch to using Vim. DPRK started abusing VS Code hooks that run _automatically_ in the background when you open a folder. ZERO fucking user interaction required _after_ trusting the repo (the trusting part is important here). Yes, read it again. ZERO. INTERACTION. REQUIRED.
so what happens is the following: they (in the usual case the Contagious Interview group, meaning some fake recruiting guy) share GitHub, Bitbucket, and GitLab repos containing a `.vscode/` subdirectory with malicious hooks. the one example I share here executes a fake font that's actually heavily-obfuscated JS and will absolutely rek you.
all your fancy software that feels "convenient" makes tradeoffs. those tradeoffs are now being abused to silently rek your devices.
use Vim. and use Qubes. Thx.
If today’s Google announcement wasn’t enough...
Oratomic, Caltech, and UC Berkeley show quantum computers can break crypto with just 10,000 reconfigurable atomic qubits.
It's clearer than ever that blockchains need post-quantum cryptography.
NEW: CEO of $4.5 trillion dollar NVIDIA, Jensen Huang, says that “bitcoin is taking excess energy and storing it as a new currency. You can take it wherever you’d like, transporting it everywhere.”
on Solana there are two ways to send a transaction
you either send to i) TPU via an RPC or ii) Jito
for i)
RPC sends to the txn processing unit (TPU) for the current block leader over QUIC
where the % of QUIC connections is higher for higher-staked nodes
for ii), this gets complex
but essentially, most Jito nodes have a reverse-proxy relayer in front of the TPU, and these relayers hold the txn for a duration
there are several micro auctions that happen during this time, and you increase your priority via your ratio of CUs to Jito tips
what matters for the RPC path is i) latency to the leader queue, ii) priority, which is determined by how much priority fee you're paying divided by CUs, iii) stake, iv) a bunch of other infra shit
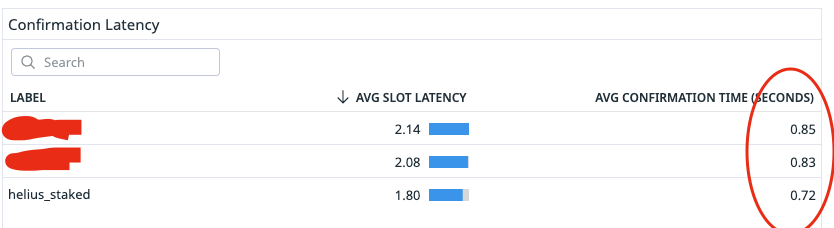
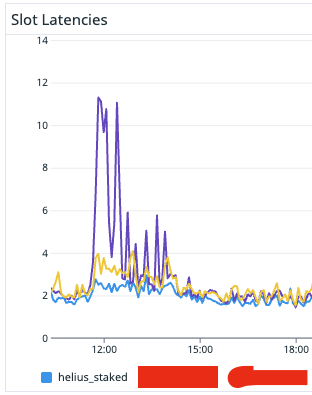
we've made a lot of improvements to the TPU sending logic in the past week and are consistently finding good results when compared to other RPCs
(1st screenshot shows average latency being lower, and the 2nd screenshot shows much better performance during high congestion events)
we have a new product called Sender (lol), that sends to both i) and ii) above, so you don't have to think too hard and can plug in this endpoint
you can also choose to send to i) only and not ii) if you don't want
a lot of traders have reported positive results, more for some regions than others (especially Tokyo), and we're making improvements every day
link below to try it out, you don't even need a helius api key
Apple's timing could not be better with this.
The M3 Ultra 512GB Mac Studio fits perfectly with massive sparse MoEs like DeepSeek V3/R1.
2 M3 Ultra 512GB Mac Studios with @exolabs is all you need to run the full, unquantized DeepSeek R1 at home.
The first requirement for running these massive AI models is that they need to fit into GPU memory (in Apple's case, unified memory). Here's a quick comparison of how much that costs for different options (note: DIGITS is left out here since details are still unconfirmed):
NVIDIA H100: 80GB @ 3TB/s, $25,000, $312.50 per GB
AMD MI300X: 192GB @ 5.3TB/s, $20,000, $104.17 per GB
Apple M2 Ultra: 192GB @ 800GB/s, $5,000, $26.04 per GB
Apple M3 Ultra: 512GB @ 800GB/s, $9,500, $18.55 per GB
That's a 28% reduction in $ per GB from the M2 Ultra - pretty good.
The concerning thing here is the memory refresh rate. This is the ratio of memory bandwidth to memory of the device. It tells you how many times per second you could cycle through the entire memory on the device. This is the dominating factor for the performance of single request (batch_size=1) inference. For a dense model that saturates all of the memory of the machine, the maximum theoretical token rate is bound by this number. Comparison of memory refresh rate:
NVIDIA H100 (80GB): 37.5/s
AMD MI300X (192GB): 27.6/s
Apple M2 Ultra (192GB): 4.16/s (9x less than H100)
Apple M3 Ultra (512GB): 1.56/s (24x less than H100)
Apple is trading off more memory for less memory refresh frequency, now 24x less than a H100. Another way to look at this is to analyze how much it costs per unit of memory bandwidth. Comparison of cost per GB/s of memory bandwidth (cheaper is better):
NVIDIA H100 (80GB): $8.33 per GB/s
AMD MI300X (192GB): $3.77 per GB/s
Apple M2 Ultra (192GB): $6.25 per GB/s
Apple M3 Ultra (512GB): $11.875 per GB/s
There are two ways Apple wins with this approach. Both are hierarchical model structures that exploit the sparsity of model parameter activation: MoE and Modular Routing.
MoE adds multiple experts to each layer and picks the top-k of N experts in each layer, so only k/N experts are active per layer. The more sparse the activation (smaller the ratio k/N) the better for Apple. DeepSeek R1 ratio is small: 8/256 = 1/32. Model developers could likely push this to be even smaller, potentially we might see a future where k/N is something like 8/1024 = 1/128 (<1% activated parameters).
Modular Routing includes methods like DiPaCo and dynamic ensembles where a gating function activates multiple independent models and aggregates the results into one single result. For this, multiple models need to be in memory but only a few are active at any given time.
Both MoE and Modular Routing require a lot of memory but not much memory bandwidth because only a small % of total parameters are active at any given time, which is the only data that actually needs to move around in memory.
Funny story... 2 weeks ago I had a call with one of Apple's biggest competitors. They asked if I had a suggestion for a piece of AI hardware they could build. I told them, go build a 512GB memory Mac Studio-like box for AI. Congrats Apple for doing this. Something I thought would still take you a few years to do you did today. I'm impressed.
Looking forward, there will likely be an M4 Ultra Mac Studio next year which should address my main concern since these Ultra chips use Apple UltraFusion to fuse Max dies. The M4 Max had a 36.5% increase in memory bandwidth compared to the M3 Max, so we should see something similar (or possibly more depending on the configuration) in the M4 Ultra.
Why We Crypto
Crypto is an insanely hard game because:
1. We operate at the absolute cutting edge of the fastest moving industries in history - finance, information technology, social media.
2. Our work is rooted in 3 of the most intractable and unsolvable human problems - politics, money, tribalism.
3/ Every single day is a revealing lesson in all the inner and outer workings of how human nature and our society really works - the good, the bad, the ugly.
But of course, when it all works out, we get to see social cohesion in its most magical form - when a group of otherwise completely unrelated strangers come together virtually to create something of immense value.
And the beauty of that creation - makes all the hard work more than worth it.
And that’s why we do what we do. 🐱
基于区块链的加密货币安全审计指南
Blockchain-Based Cryptocurrency Security Audit Guide
https://t.co/GkDF4mJzmq
English version:
https://t.co/k8y7CV63Kz
By @OhJohanZ from @SlowMist_Team
🎉 Day 1 is here, and we're kicking things off with a bang!
Join us at Booth E03 for a chance to win big in our on-site lottery. Excitement is just a visit away. Don't miss out - your lucky draw awaits! 🍀
1/ 🚨 Introducing zkLink's 72hr "Dunkirk Test" : a game-changer for #crypto safety 🚨
We'll simulate an emergency shutdown giving you the chance to try our asset recovery feature & earn an OAT available on @Galxe
JOIN 👉 https://t.co/oM6DJ6FWfh
INFO 👉 https://t.co/KSQ5mWHRkE