@kalomaze @findboundary You aren’t in bad shape. A new driver is backwards compatible with old cuda toolkits. Torch doesn’t usually come packaged with nvcc, so it isn’t surprising that the compiler is out of date. Just look for a cudatoolkit-dev that matches your pytorch cuda version.
After dozens of visits, google still ranks the jax documentation below a pile of garbage about jacksonville, local businesses, and the singer whenever I search “jax”.
You can apply for early pilot access to the National AI Research Resource (NAIRR): https://t.co/cGrX4As7eo
NSF's Press Release: https://t.co/0w8vQR6yXB
@DrJimFan I’ll be interested to see what happens after the first big leak of one of these kinds of models. A company puts a lot of potentially valuable data into a single 25GB crown jewel, but that data is inherently noisy and unreliable to competitors without ground truth.
@felix_red_panda@artificialguybr It looks like you can get ERA5 data for free (as recent as 6 days ago) from the Climate Data Store (seems to be an EU public service).
@Karmedge These benchmarks are for very specific formal reasoning tasks which GPT-4 is probably not heavily trained on (“all cats are blue, tigers are cats, Richard is a tiger, is Richard blue?”). It’s not that surprising that a fine-tuned task-specific model can perform comparably.
@OfirPress I also see a lot of people citing minor performance degradation on arc/winograde/hellaswag/MMLU. Very few of the tasks in these benchmarks are longer than a few hundred tokens, let alone the many thousands of tokens in the context lengths that they're trying to evaluate.
@ggerganov@theemozilla@yacineMTB Watch out- models with different context window lengths aren't so easily comparable, and these results might be misleading. I talk about this here:
https://t.co/erEt0XtFt9
@theemozilla@teknium@ggerganov@yacineMTB How long are the benchmark tasks in these datasets? It would be great to rule out the possibility that the benchmarks aren’t really testing / don’t necessitate the full context.
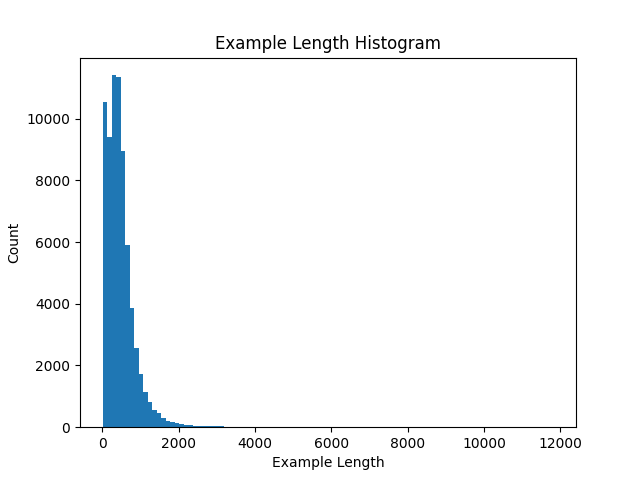
This is the distribution of prompt+output lengths (in tokens) for the WizardLM 70k dataset. The examples >3k tokens seem to get there through listing lots of things, long junk code, and repetitive number sequences. Warrants filtering, and not helpful for evaluating long context.