Introducing Claude for Enterprise.
Now your entire organization can collaborate securely with Claude—with no training on chats or files.
Comes with:
📚 Expanded 500K context window
🧑💻 Native GitHub integration
🔐 Enterprise-grade security features
https://t.co/CUiwAkKpoh
Salesforce announcing 24/7 AI powered sales reps 🤯
Einstein SDR Agent & Einstein Sales Coach Agent are coming soon
So many jobs getting disrupted now
The Pruning & Distillation story continues! @nvidia just released Mistral Nemo Minitron 8B, a base LLM obtained by pruning and distilling the Mistral-NeMo 12B! 👀
TL;DR:
✨ Used 400B tokens used for distillation, compared to training from scratch
📊 Outperforms Mistral-7B and LLaMa-3.1-8B across 8/9 benchmarks
🔝 Enhanced model accuracy via distillation from the Mistral-NeMo-12B teacher
🚀 Commercial use with a permissive license
💡 Fine-tune the teacher with 100B tokens before distillation due to missing original training data
👀 Focused pruning on MLP & embedding dimensions, leaving Attention layers untouched
🤗 Available on @huggingface
Model: https://t.co/QCuUahMf0V
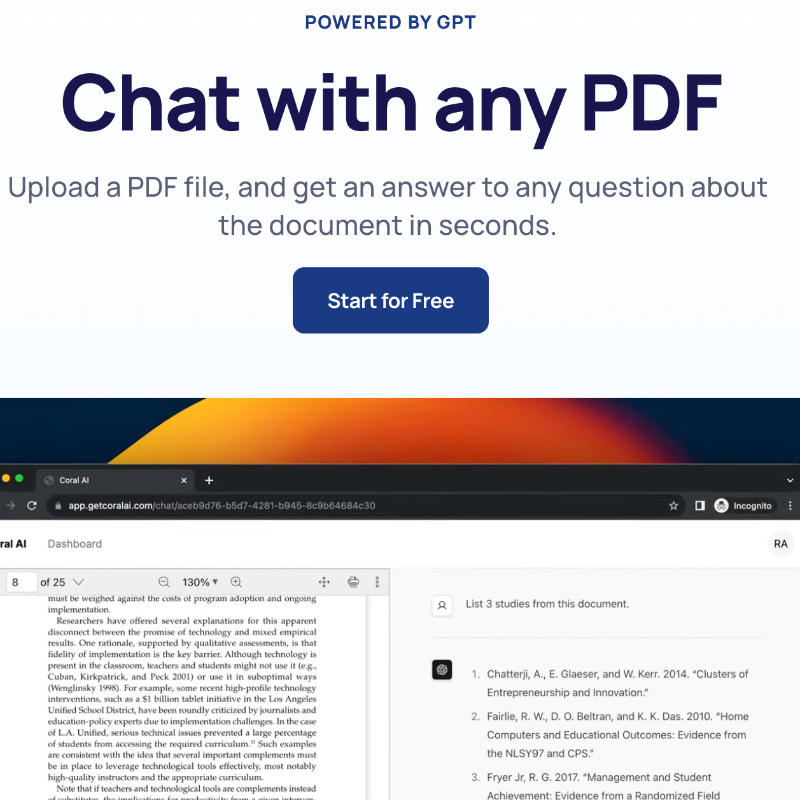
This is the best new AI tool for research.
Just upload a PDF file, ask a question, and get an answer in seconds.
It's like ChatGPT, but built for researchers.
Try it for free.
New short course with @MistralAI !
Mistral's open-source Mixtral 8x7B model uses a "mixture of experts" (MoE) architecture. Unlike a standard transformer, an MoE model has multiple expert feed-forward networks (8 in this case), with a gating network selecting two experts at inference time. This enables MoE to match the performance of a large model but faster inference. Mixtral 8x7B has 46.7B parameters but activates only 12.9B at inference to predict the next token.
In Getting Started with Mistral, you’ll learn from Mistral’s @sophiamyang to:
- Explore Mistral's open-source models (Mistral 7B, Mixtral 8x7B) and commercial models via API calls and Mistral AI's Le Chat website
- Implement JSON mode to generate structured outputs to integrate directly into larger software systems.
- Use function calling for Tool Use, such as calling custom Python code that queries tabular data
- Ground your LLM's response with external knowledge sources using RAG
- Build a Mistral-powered chat interface that can reference external documents
This course will help deepen your prompt engineering skills. Please sign up here: https://t.co/weYwGmPlLA
Run Llama3 in @supabase Edge Functions
◆ uses @ollama
◆ streaming support with @deno_land
◆ serve and develop locally
◆ "BYO Ollama" server for prod
↓ docs
https://t.co/Nq7Ie8uluL
Today we're adding native AI support in @supabase Edge Functions
◆ Embedding models
◆ Large language models (powered by @ollama)
We've removed the cold-boot by placing the models inside the edge runtime and we're rolling out a GPU-powered sidecar.
See it in action:
New: Open Medical LLM Leaderboard! 🩺
In basic chatbots, errors are annoyances.
In medical LLMs, errors can have life-threatening consequences 🩸
It's therefore vital to benchmark/follow advances in medical LLMs before thinking about deployment.
Blog: https://t.co/pddLtkmhsz
We just released Mixtral-8x22B-v0.1 and Mixtral-8x22B-Instruct-v0.1:
- Free to use under Apache 2.0 license
- Outperforms all open models
- Native function calling
- Masters English, French, Italian, German and Spanish.
- Seq_len = 64K
https://t.co/SCG8s06Dbl
Happy to OSS gpt-fast, a fast and hackable implementation of transformer inference in <1000 lines of native PyTorch with support for quantization, speculative decoding, TP, Nvidia/AMD support, and more!
Code: https://t.co/REjeKUUwjF
Blog: https://t.co/esIhj2ioT4
(1/12)
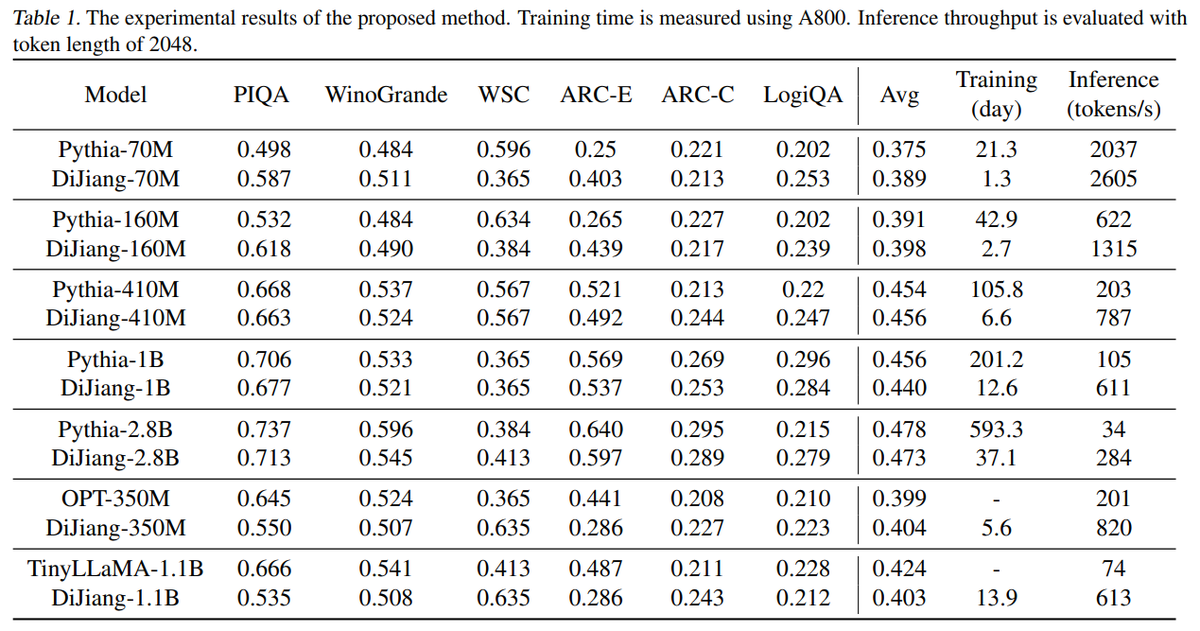
Huawei presents DiJiang: Efficient Large Language Models through Compact Kernelization
Achieves comparable performance with LLaMA2-7B on various benchmark while requiring only about 1/50 pretraining cost
https://t.co/4AzjmmkYZc
Google presents Gecko
Versatile Text Embeddings Distilled from Large Language Models
Gecko with 768 emb dim competes with 7x larger models and 5x higher dimensional embeddings
https://t.co/R9sQ8hpTGb
One of the coolest projects I think we've worked on.
The beginning of amorphous applications and a showcase of the creativity and imagination LLM's can extend their minds to.
Try it - and see
llm routing systems - which decide which llm to use for what task - are getting more important, esp. if open source keeps flourishing
yet there's no standard evaluation method for routing systems...enter ROUTERBENCH
As the range of applications for Large Language Models (LLMs) continues to grow, the demand for effective serving solutions becomes increasingly critical. Despite the versatility of LLMs, no single model can optimally address all tasks and applications, particularly when balancing performance with cost. This limitation has led to the development of LLM routing systems, which combine the strengths of various models to overcome the constraints of individual LLMs. Yet, the absence of a standardized benchmark for evaluating the performance of LLM routers hinders progress in this area. To bridge this gap, we present ROUTERBENCH, a novel evaluation framework designed to systematically assess the efficacy of LLM routing systems, along with a comprehensive dataset comprising over 405k inference outcomes from representative LLMs to support the development of routing strategies. We further propose a theoretical framework for LLM routing, and deliver a comparative analysis of various routing approaches through ROUTERBENCH, highlighting their potentials and limitations within our evaluation framework. This work not only formalizes and advances the development of LLM routing systems but also sets a standard for their assessment, paving the way for more accessible and economically viable LLM deployments. The code and data are available at https://t.co/EwlUE61bIn.
👩🏫LangSmith for Beginners
Great video from @mesudarshan walking through LangSmith and all that it offers
"LangSmith is a unified DevOps platform for developing, collaborating, testing, deploying, and monitoring LLM applications"
https://t.co/Wrc4tJRKfI
Human will succeed after failure. Why not LLM agents?🤔️
Check out 🤖ETO, an LLM agent learning method continually exploring envs to learn from failures and optimize agent decisions.
❤️Great thanks for awesome Yifan, @xiangyue96, @jefffhj, Prof. Sujian Li, and @billyuchenlin !
I'm working on LLM security, securing what language models do - including this tool, garak (https://t.co/KJSYgkKzps) which find LLM failures. It's one of the 1st tools of its kind & completely open. Info on security failures can now be sent to the global AI vulnerability database
(3/n) We systematically query LLM with a progressive failure explanation algorithm that is able to handle both execution-level and planning-level failures.
Conditioned on the explanation, LLM is able to generate a correction plan for the robot to complete the task.
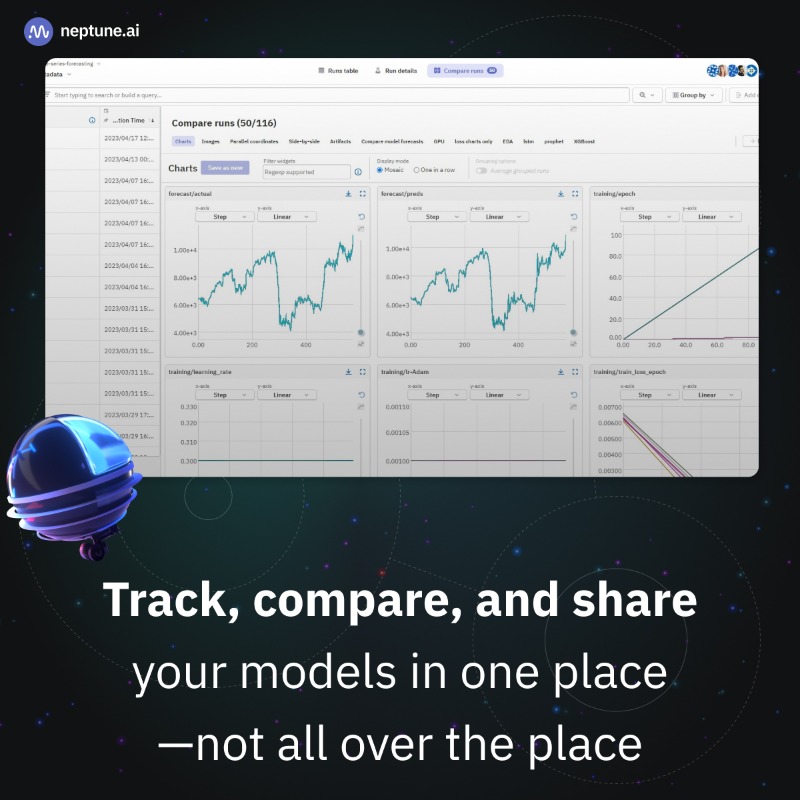
The MLOps stack component for experiment tracking
🔹 Automate and standardize tracking as your modeling team grows
🔹 Collaborate on models and results with your team and across the org
🔹Integrate with any MLOps stack
Learn more ⤵️