We are pleased to announce Grapedia II: From Omics Data to Vineyard Impact. This will be the second Grapedia meeting, and we're very excited to invited you to join us in Stellenbosch, South Africa, 9–11th March 2027. Join us! more of #grapediameeting at https://t.co/qGJu8uv4q5
First, a link to the preprint describing the method (PFlogPF) that produced the amazing results shown above: https://t.co/x11kgmYUeF
The work was led by @sinabooeshaghi who is first and corresponding author, w/ important contributions by @IngileifBryndis & @agalvezmerchan. 4/
This is the day!
On May 5, 1976, fifty years ago, John Chambers sketched a simple idea on paper, a new paradigm for designing computer languages. That idea became the S language, which transformed statistical computing forever. S later evolved into its open-source successor, R.
🧵 1/ In high-dimensional bio data—transcriptomics, proteomics, metabolomics—you're almost guaranteed to find something “significant.”
Even when there’s nothing there.
Sci-Hub is an evil website that pirated 85M+ research papers and made them freely available
And now they've added AI to their database to make Sci-Bot.
It answers your questions using latest, full-text articles.
But DO NOT use it. We should all try to make billion-dollar academic publishers richer.
I'm putting the link below so you know how to avoid it.
The snap, crackle and pop of AI rewrites of bioinformatics tools are all positive. @lh3lh3 with a thoughtful essay on the matter. https://t.co/RsM59ksyAT
The wait is over!!! The StatQuest Illustrated Guide to Statistics is here! TRIPLE BAM!!!
Amazon: https://t.co/GCPaT8DOwN
PDF: https://t.co/s5CMDUxMzf
India Pre-Order: https://t.co/IlVdJL3NlU
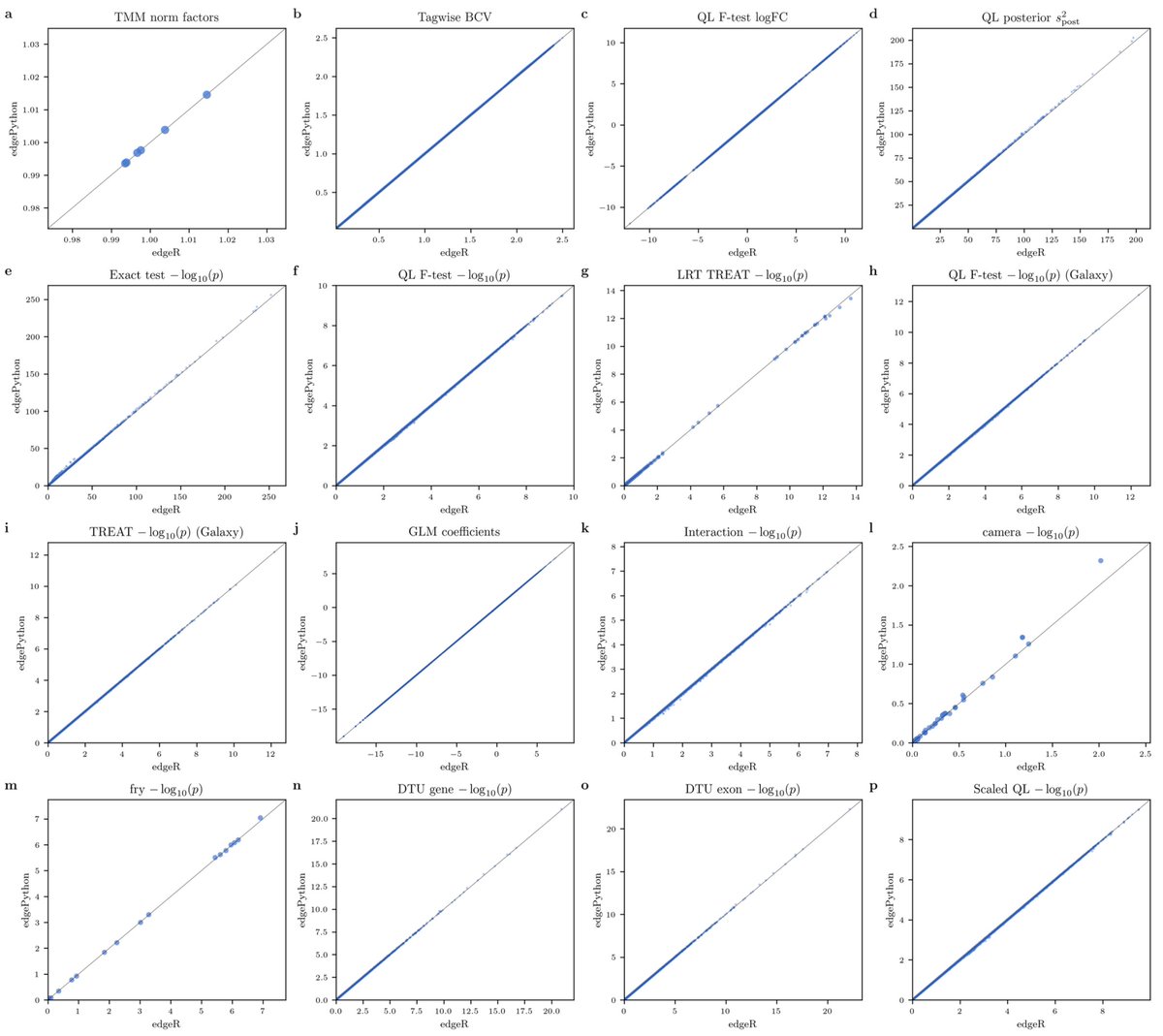
I used Claude Opus 4.5/4.6 (and a bit of Codex GPT-5.3) to port edgeR to Python. See edgePython https://t.co/NOMbVAEfzw
This allowed me to develop a single-cell DE method that extends NEBULA with edgeR Empirical Bayes. All in one week. Details in https://t.co/OUUf2hAjQ4
“I’ve survived war, and I’m definitely going to survive intimidation and whatever these people think they can throw at me, because I’m built that way.” — Ilhan Omar.
Yay Ilhan. Ignore the trolls.
New blog post: how to efficiently calibrate LLM uncertainty using semantic entropy as a reward signal. The calibration gap here is the difference between the confidence reported by the model and its accuracy. https://t.co/qo2M8Xlh8U
@mbeisen I know, I’m not very sharp, but if we set aside the whole Nobel issue—which is really just an award, like the Oscar in cinema (which, for example, Stanley Kubrick never won)—by now, even at a basic level of understanding, the contributions of the entire scientific team 1/1
🚀 Big update to iDEP — our popular app for RNA-seq and omics data analysis. Visualize, analyze, & unveil pathways. In minutes!
What’s new
1. Updated annotation of 13,000 genomes
2. Cleaner, faster UI with improved docs
3. Import external fold-change & p-value tables, then run clustering and pathway analysis.
Why iDEP?
iDEP brings together hundreds of R packages and thousands of annotation resources so any biologist can interpret RNA-seq data interactively. It is a massive Shiny app with a huge database, taking 8 years and over $1M to develop!
Key features:
1. End-to-end workflow: exploratory analysis, differential expression, and pathway analysis for bulk RNA-seq or other gene-level summaries
2. Rich, interactive visuals: clustering, KEGG pathways, genome views, and more
3. Flexible use: run on the web, as an R package, or via Docker
4. Reproducibility by design: download the generated R code, data objects, reports
If you work with RNA-seq or other omics data, give the new iDEP a spin—and let us know what you think!
iDEP: https://t.co/RK27yi16Cp
#RNAseq #Bioinformatics #Omics #Shiny #RStats #DataScience #Genomics #ReproducibleResearch