Which modeling to choose for text-to-music generation?
We run a head-to-head comparison to figure it out.
Same data, same architecture - AR vs FM.
👇 If you care about fidelity, speed, control, or editing see this thread.
🔗https://t.co/FBWu7ThspC
📄https://t.co/Dp1co1esvd
1/6
1/6 Diffusion models are scaling up, but deploying a massive, monolithic network uniformly across the entire generative timeline is inherently inefficient.
Introducing Complexity-Balanced Splitting (CBS): a principled framework that allocates capacity exactly where needed!👇🧵
🚨 New paper alert! 🚨
Millions of neural networks now populate public repositories like Hugging Face 🤗, but most lack documentation. So, we decided to build an Atlas 🗺️
Project: https://t.co/1JpsC6dCeg
Demo: https://t.co/4Xy7yLdIZY
🧵👇🏻 Here's what we found:
Excited to share this has now been accepted at #NeurIPS2025 as a position paper (<6% acceptance)!🎉
We advocate for systematically studying entire model populations via weight-space learning, and argue that this requires charting them in a Model Atlas.
@NeurIPSConf#NeurIPS
🧵👇
Excited to share our work Set Block Decoding!
A new paradigm combining next-token-prediction and masked (or discrete diffusion) models, allowing parallel decoding without any architectural changes and with exact KV cache.
Arguably one of the simplest ways to accelerate LLMs!
@__Rafail__@NadavHarTuv I believe it should. If the audio is very long you may need to parse it in chunks but thats also true to all other audio representation models
@__Rafail__@NadavHarTuv Nope, PAST has ~180M params, with the streamable version having ~125M params. This should run on a standard gpu. For speech LM training we used 2 a100 gpus but it could be done with less
Many modern SpeechLMs are trained with Speech-Text interleaving. How does this impact scaling trends?
In our new paper, we train several dozen SLMs, and show - quite a lot! So there is room for optimism 😊
Key insights, code, models, full paper 👇🏻
🎉Thrilled that our paper on "scaling analysis of interleaved speech-text LMs" was accepted to #CoLM2025
It gives room for optimism when scaling SpeechLMs *right* - with large TextLMs (in place of more data), interleaving, and synth training data💪
Happy to announce that our paper “EditInspector: A Benchmark for Evaluation of Text-Guided Image Edits” was accepted to #ACL2025 🎉
📄 https://t.co/mwugXz1H5q
🌐 https://t.co/NMmdzi3nBn
💣Introducing PAST: a speech tokenizer that jointly model phonetics and acoustics (No SSL involved).
Past demonstrates great reconstruction as well as semantic capabilities in the form of ABX and sWUGGY.
🤗 https://t.co/teQQ9s5whr
Check out Nadav's post👇@NadavHarTuv@adiyossLC
🚨 New paper alert!
PAST: phonetic-acoustic speech tokenizer – just got accepted to Interspeech 2025 🎉
It learns phonetic + acoustic tokens jointly, with no SSL babysitter or external vocoder.
🔗https://t.co/yGypWO6YpM
👇 If you’re into speech LMs, keep reading!
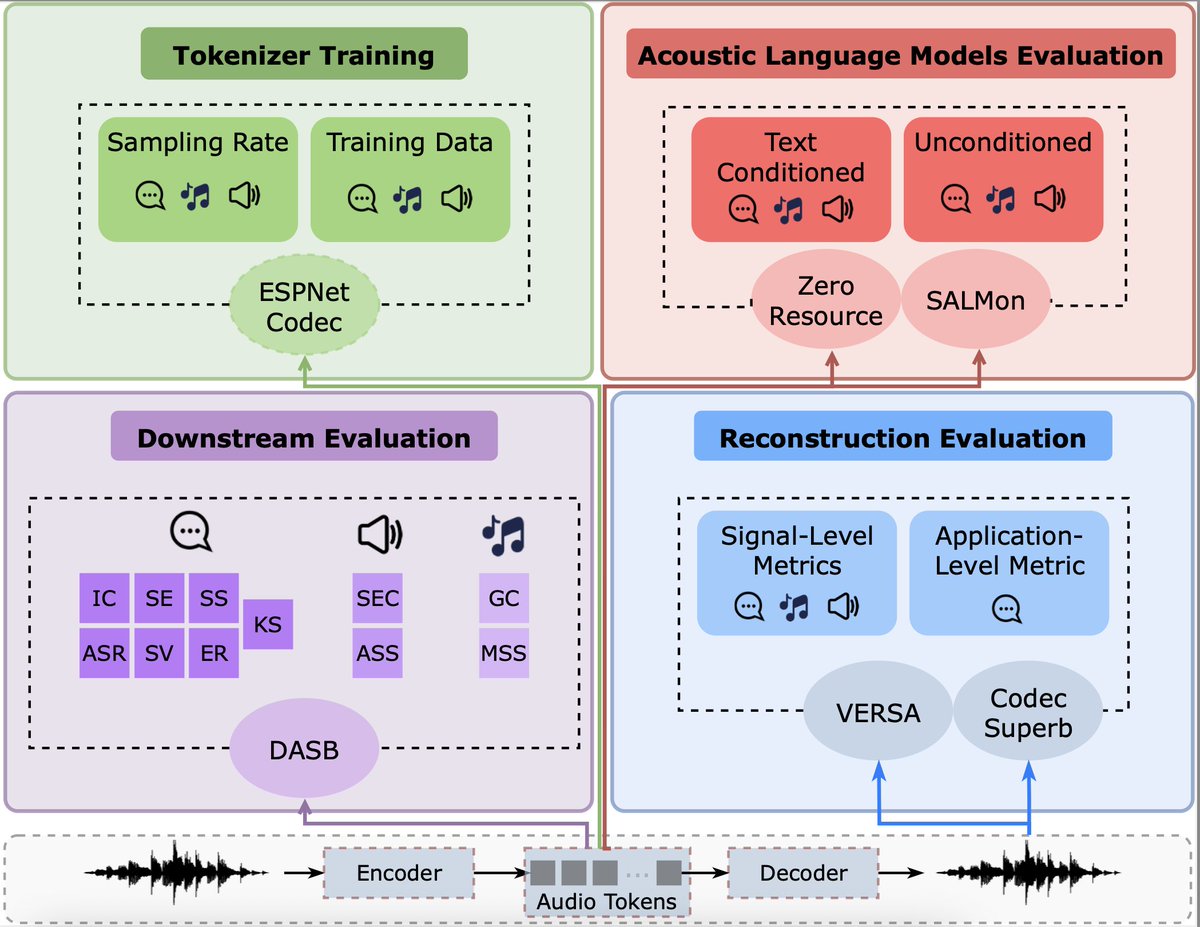
🎵💬 If you are interested in Audio Tokenisers, you should check out our new work!
We empirically analysed existing tokenisers from every way - reconstruction, downstream, LMs and more.
Grab yourself a ☕/🍺 and sit down for a read!
🚨 New Paper: "Time to Talk"! 🕵️
We built an LLM agent that doesn't just decide WHAT to say, but also WHEN to say it!
Introducing "Time to Talk" - LLM agents for asynchronous group communication, tested in real Mafia games with human players.
🌐https://t.co/HdNUwlvF2F
🧵1/7
Which modeling to choose for text-to-music generation?
We run a head-to-head comparison to figure it out.
Same data, same architecture - AR vs FM.
👇 If you care about fidelity, speed, control, or editing see this thread.
🔗https://t.co/FBWu7ThspC
📄https://t.co/Dp1co1esvd
1/6
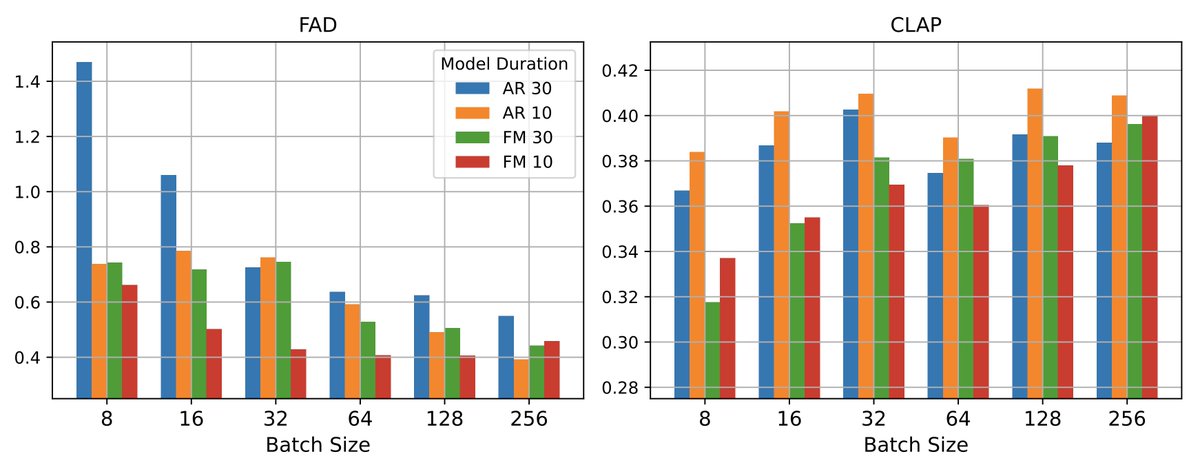
What if training steps are capped at 500k?
FM reaches near-topline quality with small batches.
It’s compute-efficient and forgiving.
AR needs larger batch sizes to recover performance.
It benefits more from large-scale training.
See📉 below by model duration + batch size:
6/6
We’ve been exploring the trade-offs between Autoregressive and Flow-Matching models for music generation. We share our findings in this latest paper led by @Or__Tal. Many interesting take-aways and practical advice on training generative models for music! 🎶🧠