I'm an old programmer (by programmer standards). I use agents daily, extensively. Here's a view from the other side of "wooooow look how many lines it wrote!", taken from my work today.
I've got an agent in a loop optimizing a renderer with the goal to minimize frame times (and tests to measure). It got times down from 88ms to 2ms and allocations down from ~150K to 500. Sounds good, right? Wrong. This is exactly why agent psychosis is a big fucking problem.
As an experiment, I rewrote the Ghostty core render state in Go, with access to identically laid out data structures as Ghostty and the exact same validation tests. I made a purposely naive renderer (simple, correct, but slow). 88ms per frame with 150,000 allocations (horrendous, lol)!
I then kickstarted a Ralph loop to bring the frame times down. I told it it can't modify input data structures or the public API or tests (they're correct), but it can do anything else it wants. It got to work.
It has worked for about 4 hours. I've spent around $350 on this experiment so far. The results?
88ms => 1.5ms
150K allocs => ~500 allocs
Incredible right? Nope.
My hand-written renderer I ported has frame times (same benchmark) of ~20us (0.020ms) and 0 allocations in the update path.
This is the problem with psychosis and lacking systems understanding. If you don't understand the system, you're going to accept that this is an incredible result. If you understand the system, you'll see better solutions immediately and can do roughly 75x better on throughput.
The people who blindly trust agent output are in the former camp. They're sheeple, overdrinking from a fountain of mediocrity.
Standard disclaimer: I use AI all the time. I like AI. The point I'm making is to not blindly accept results. Think. Analyze. Learn.
یه ویژگی برنامه نویسای خوب در مقابله با AI اینه که نسبت به خروجیش مقاومت میکنن و شگفت زده نمیشن و بررسیش میکنن!
از طرف دیگه برنامه نویسای بد فکر میکنن AI داره کارشون رو به شکل درستی انجام میده و review نکرده، PR باز میکنن که ممکنه چیزی از دست کسی موقع review در بره.
خلاصه بگم، مقاومت کردن مهارت و هنره!
مقاومتتون رو از دست ندید
کد زدن با AI اینطوریه که سرعت کد نوشتن سنیور دولوپرهای تیمم شاید ۵۰ تا ۱۰۰ درصد بیشتر شده باشه که خوبه ولی از اونور سرعت کثافت تولید کردن جونیور ها ۴ ۵ برابر شده و یه وقت زیادی از تیم میره که کثافت های اینا بررسی بشه. خسته کننده شده
Introducing SubQ - a major breakthrough in LLM intelligence.
It is the first model built on a fully sub-quadratic sparse-attention architecture (SSA),
And the first frontier model with a 12 million token context window which is:
- 52x faster than FlashAttention at 1MM tokens
- Less than 5% the cost of Opus
Transformer-based LLMs waste compute by processing every possible relationship between words (standard attention).
Only a small fraction actually matter.
@subquadratic finds and focuses only on the ones that do.
That's nearly 1,000x less compute and a new way for LLMs to scale.
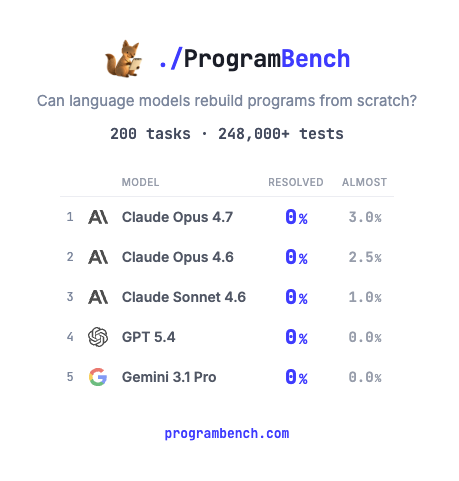
How much of SQLite, FFmpeg, PHP compiler can LMs code from scratch? Given just an executable and no starter code or internet access.
Introducing ProgramBench: 200 rigorous, whole-repo generation tasks where models design, build, and ship a working program end to end. 🧵
@behdaaad@BoyOfSanJose77@behdadesfahbod هدف اینجور سوالها سنجش فرایند ذهنی طرف برای حل یک مساله است. مسالهای که نیاز به رفع ابهام توی فرضیات، شکستن به قسمتهای کوچیکتر و انواع استدلال برای رسیدن به یک تخمینه. خود جواب خیلی مهم نیست.