a regular laptop with just 8GB VRAM
can now run a LOCAL AI AGENT directly on your device
what you need:
1/ 8 GB VRAM
2/ 16 GB RAM
3/ $600+ laptop
method: Kimi K2 + Hermes Agent Dekstop App
what agent can do:
1/ read and write files
2/ patch code, open PRs on GitHub
3/ browse the web like a human
4/ work with Notion
5/ run scripts, debug, refactor
this isn't 'ask a question, get an answer.' this is an agent that drives a task from start to finish on its own.
before: local agent = either the cloud and $$$, or an RTX
now: any gaming laptop from the last 3 years
p.s. MoE is the key. Kimi K2 activates only a fraction of its params per token - that's why a 1T-param model runs on hardware where a dense 26B would already be choking
did you try Hermes Dekstop?
Removes LLM censorship with a single click.
credit via @elder_plinius bro,
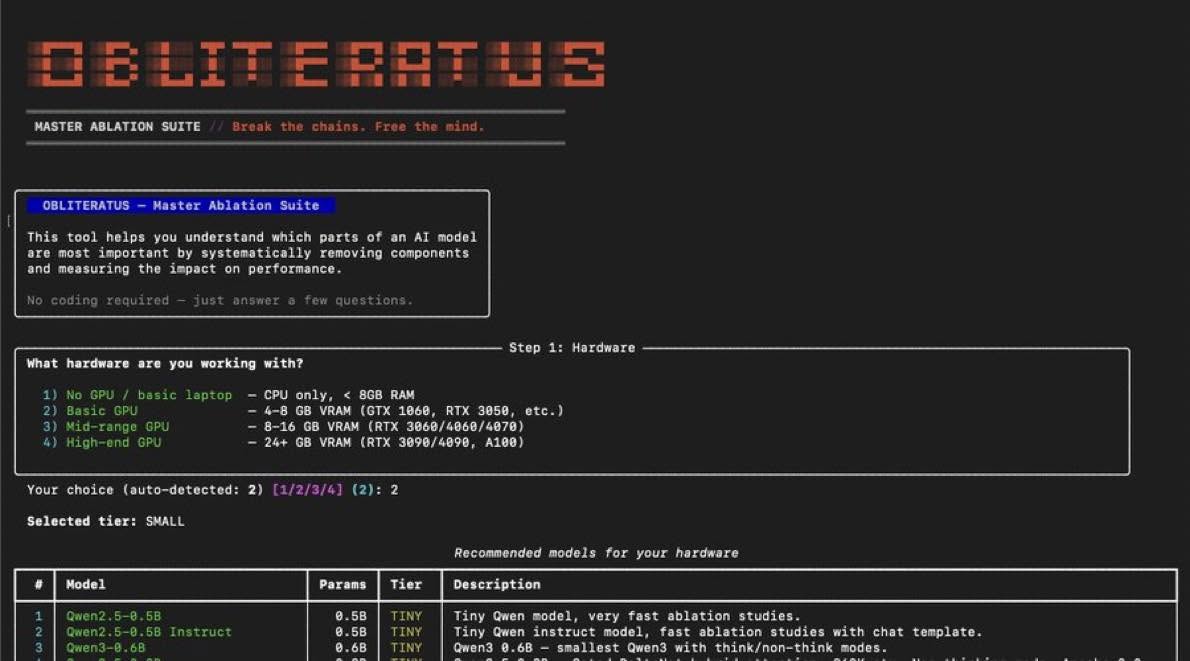
Obliteratus, the open-source weapon that hunts down the exact weights causing refusals and surgically projects them out, is helpful for cybersec.
Obliteratus uses advanced techniques (SVD, mean-difference analysis) to detect refusal behaviors and remove them at the weight level without retraining
One-click ablation, Gradio playground for no-code use, Reversible steering vectors,
Supports 100+ Hugging Face models, Multi-GPU ready.
- https://t.co/3sMeMv1M45
ALGUIEN CREÓ UN REPO EN GITHUB QUE TE PERMITE EJECUTAR CLAUDE CODE COMPLETAMENTE GRATIS, PARA SIEMPRE.
Redirige tu tráfico de Claude Code a 10 proveedores gratuitos como DeepSeek y Kimi, toma 5 minutos configurarlo, y ya tiene a más de 20,000 desarrolladores ejecutándolo.
🚨Anthropic just showed a 24-minute workshop on how to actually do prompts for Claude.
Taught by the people who built it.
Free. No registration. No paywall.
I've seen $300 courses that don't cover what they teach in the first 8 minutes.
Watch it and bookmark it now!
A guy named nbatman on Reddit accidentally built the most useful website on the internet.
It's called FMHY (Free Media Heck Yeah).
This is the website Google delisted from search for DMCA violations, Reddit shadow-banned for promoting piracy, the Motion Picture Association flagged as a top piracy threat, and the RIAA pressured hosting providers to drop. It is still online. It is still updated every month.
Here's how it works.
FMHY is the index. The wiki itself hosts nothing. It just tells you where every free thing on the internet actually lives, organized into 14 categories with safety ratings on every single link.
→ Movies and shows in 4K from 50+ streaming sites
→ Music at Spotify and Apple Music quality
→ Adobe Creative Cloud, Microsoft Office, AutoCAD, JetBrains
→ Every paid course on every major learning platform
→ 100 million books and papers through Anna's Archive
→ Free alternatives to every paid AI tool
→ A SafeGuard browser extension that flags unsafe sites in real time
It started as a single Google Doc maintained by one Reddit moderator in 2018. Google killed it with a DMCA takedown in 2023.
The community rebuilt the wiki on its own domain, mirrored it to GitHub and IPFS, and now runs it across 12 backup domains simultaneously.
There is no company. No CEO. No central server. Six anonymous volunteers maintain the entire thing in their spare time. Donations through Ko-fi pay for the hosting. Nobody profits.
Hollywood can't shut this down. Spotify can't shut this down. Adobe can't shut this down.
The entire subscription economy is held together by you not knowing this wiki exists.
https://t.co/AAr2rLlqgy
Operating Systems and their Country of Origin
• Windows - 🇺🇸 United States
• macOS - 🇺🇸 United States
• Android - 🇺🇸 United States
• iOS - 🇺🇸 United States
• Linux - 🇫🇮 Finland
• Ubuntu - 🇬🇧 United Kingdom
• Chrome OS - 🇺🇸 United States
• HarmonyOS - 🇨🇳 China
• UNIX - 🇺🇸 United States
• Kali Linux - 🇺🇸 United States
Somebody just ran one trillion param model (Kimi K2.5) on a single RTX 3060 12GB GPU at over 4 tokens/sec and 768GB of second-hand Intel Optane memory.
What happened is that a sparse model met an unusual memory tier that could hold its enormous body while the GPU handled the most time-sensitive organs.
i.e. the bulk of the sparse expert weights live in a larger, cheaper memory tier and are pulled into the computation as needed.
This worked because Kimi K2.5 is a Mixture-of-Experts model, so it has 1T total parameters but activates only 32B per token.
The RTX 3060’s 12GB VRAM holds latency-sensitive parts like routing, attention, dense layers, and shared experts.
The huge expert weights sit in Optane PMem, configured as RAM, while 192GB DDR4 ECC acts as cache.
He is using 6 Optane PMem (DCPMM) sticks. This retired memory format was made to bridge DRAM and SSD performance. The 768GB Optane configuration, using 6x128GB modules, does beat the best NVMe SSDs on latency by a wide margin, but remains 2x to 3x slower than DRAM.
llama.cpp handled hybrid GPU/CPU inference, with tensor placement tuned through flags like override-tensor.
The result was roughly 4 tokens/sec, which is slow for chat but impressive for a local 1T-parameter model on cheap retired enterprise hardware.
The DDR4 acted as cache, the Optane acted as a giant memory pool, and llama.cpp pushed routing and other critical tensors onto the 12GB GPU.
Part 4/3 — Bonus
Beyond Telegram: your OS has a permanent ID.
Linux: /etc/machine-id — 32-char hex, persists across reboots
Windows: MachineGuid in registry — same story
macOS: IOPlatformUUID — hardware-bound
Any app can read it. Browsers, messengers, games — all correlate your activity across sessions.
Combined with hardware fingerprint: you're not anonymous, you're catalogued.
Fix: randomize machine-id on boot, use Flatpak sandboxing, or containers with unique IDs per app.
Privacy isn't a feature — it's a discipline. #Telegram
If they keep adding tickers. I think it will be one of the top exchanges. Cex will not be needed at all. I've been wondering for quite some time why exchanges don't add swaps. #lighter