Adding horizontal lines to images improves VLM (vision language model) performance of tasks like counting, visual search, spatial understating, scene understanding, and more
Taming the Untamed: Graph-Based Knowledge Retrieval and Reasoning for MLLMs to Conquer the Unknown
Bowen Wang, Zhouqiang Jiang, Yasuaki Susumu, Shotaro Miwa, Tianwei Chen, Yuta Nakashima
Can LLMs Replace Humans During Code
Chunking?
The MITRE Corporation
Benchmarked on legacy government code written in ALC, MUMPS, Assembly.... LLMs 20% more factual and 10% more useful than human partitioning
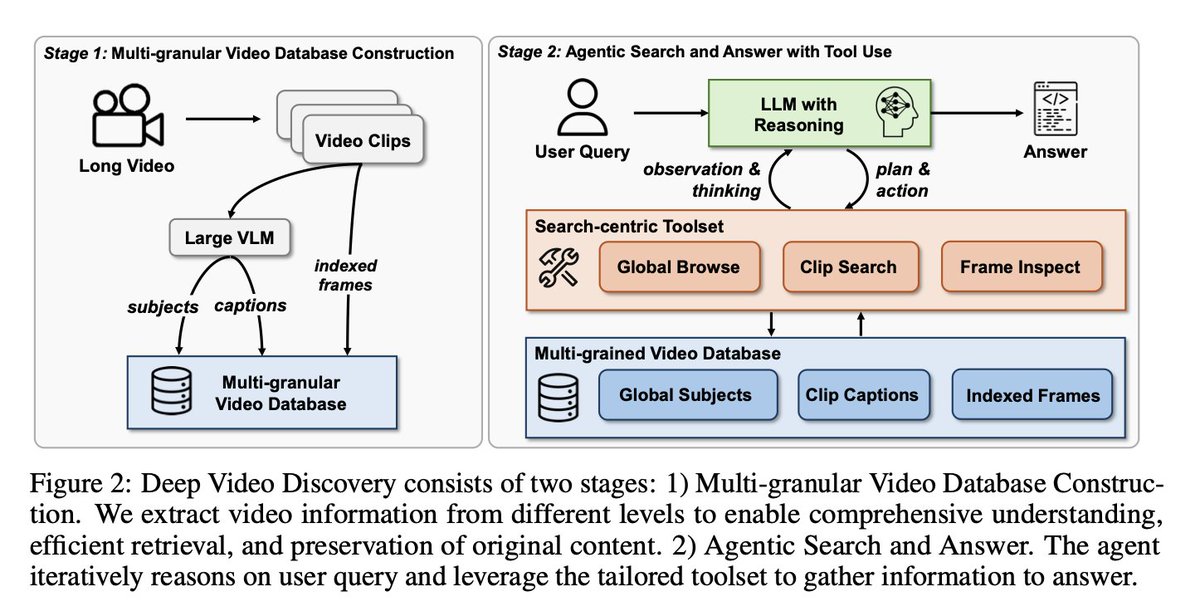
Deep Video Discovery: Agentic Search with Tool Use for Long-form Video Understanding
Xiaoyi Zhang, Zhaoyang Jia, Zongyu Guo, Jiahao Li, Bin Li, Houqiang Li, Yan Lu
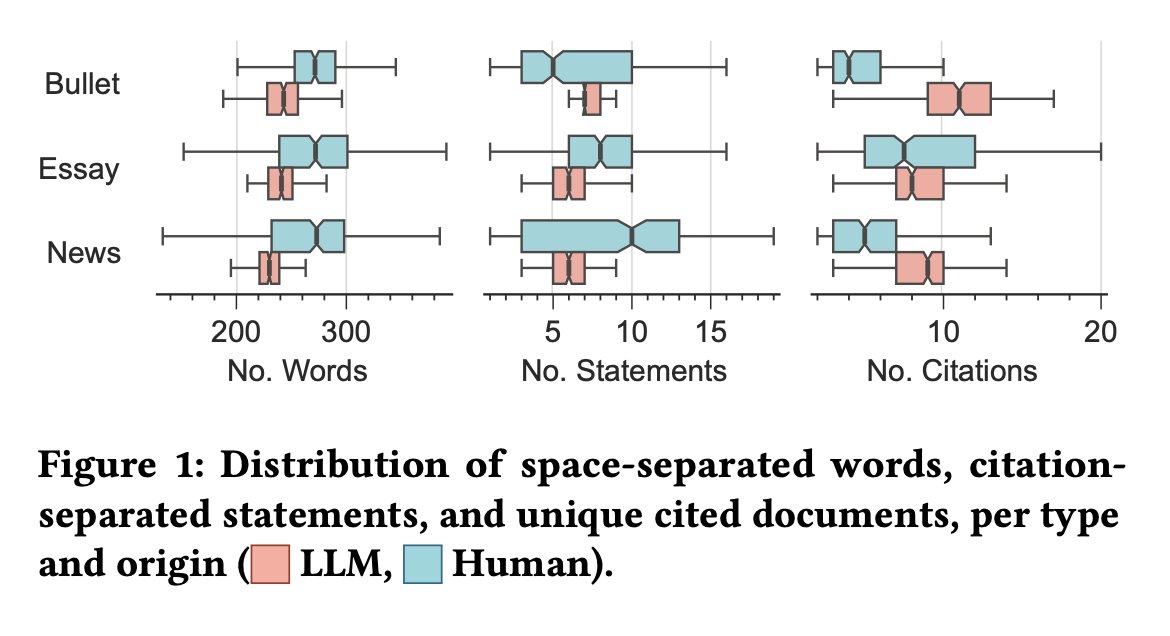
The Viability of Crowdsourcing for RAG Evaluation (SIGIR 2025)
Lukas Gienapp, Tim Hagen, Maik Fröbe, Matthias Hagen, Benno Stein, Martin Potthast, Harrisen Scells