1/ World model research is fragmented: every paper reimplements its own data pipeline, baselines, and eval harness. Comparing two methods fairly is weeks of infra work.
𝘀𝘁𝗮𝗯𝗹𝗲-𝘄𝗼𝗿𝗹𝗱𝗺𝗼𝗱𝗲𝗹 is a new open-source platform that standardizes the whole thing: https://t.co/Gg3V3LhKJr
in case you missed it @lancedb and HF are partnering up to unlock the next generation of large dataset storage on the Hub 🔥
And it's fire!
- Supports storing embeddings (and their indexes) directly alongside the data
- Vector search / similarity search is built-in
- Large multimodal datasets (text, images, video)
just use the hf:// prefix:
db = lancedb. connect("hf://datasets/julien-c/hub-stats-lance")
🔥🔥
Most video models are silent.
Most audio models don’t see.
LTX-2 learns the joint distribution of sound and vision, generating speech, foley, ambience, motion, and timing together not as a post-hoc pipeline.
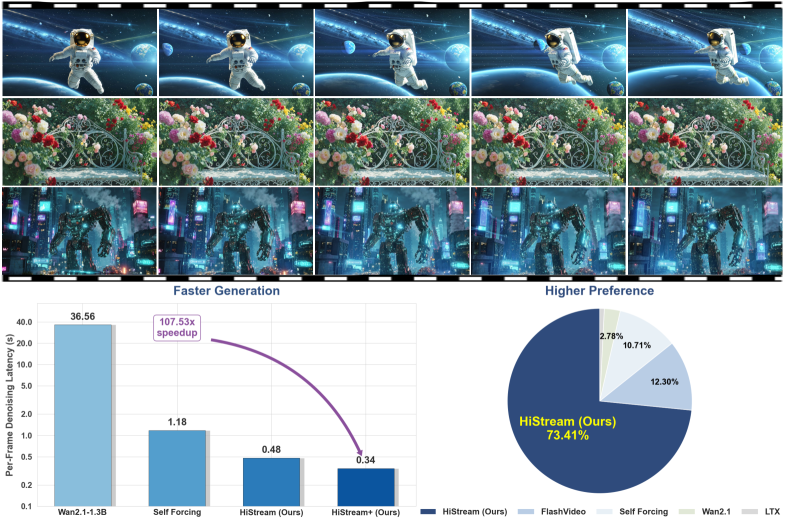
HiStream
Meta AI researchers introduce an efficient autoregressive framework for 1080p video generation. By eliminating spatial, temporal, and timestep redundancy, HiStream achieves state-of-the-art quality with up to 107.5× speedup, making high-resolution video generation practical.
We’ll walk through how Ray enables large-scale processing across hundreds of GPUs, while LanceDB’s columnar design provides efficient, intelligent curation and sampling. Together, they’re producing smaller, more diverse, and higher-quality datasets for cutting-edge text-to-image and video-to-text research.
Building and curating large-scale multimodal datasets has long been a complex, resource-heavy challenge. But that’s changing fast. Lei Xu of LanceDB and Pablo Delgado of @netflix will be speaking at Ray Summit 2025 — Scaling Multimodal Data Curation with Ray and LanceDB
Now this is a @lancedb feature to make @Noahpinion proud. Introducing RabitQ: better compression, better recall, faster index build, higher throughput.
https://t.co/46vSI8eq7n
🥳 Welcome another #Lancelot at the Roundtable, Ethan Rosenthal 🎉
On Ethan’s first day at @runwayml , he was tasked with building a multimodal 𝗱𝗮𝘁𝗮 𝘀𝘆𝘀𝘁𝗲𝗺 𝘁𝗵𝗮𝘁 𝘀𝘂𝗽𝗽𝗼𝗿𝘁𝗲𝗱 𝗯𝗼𝘁𝗵 𝗱𝗶𝘀𝘁𝗿𝗶𝗯𝘂𝘁𝗲𝗱 𝗱𝗮𝘁𝗮𝗹𝗼𝗮𝗱𝗶𝗻𝗴 𝗮𝗻𝗱 𝗲𝘅𝗽𝗹𝗼𝗿𝗮𝘁𝗼𝗿𝘆 𝗱𝗮𝘁𝗮 𝗮𝗻𝗮𝗹𝘆𝘀𝗶𝘀. He said, “𝘛𝘩𝘢𝘵’𝘴 𝘢 𝘵𝘦𝘳𝘳𝘪𝘣𝘭𝘦 𝘪𝘥𝘦𝘢. 𝘠𝘰𝘶 𝘴𝘩𝘰𝘶𝘭𝘥 𝘯𝘦𝘷𝘦𝘳 𝘵𝘳𝘺 𝘵𝘰 𝘥𝘰 𝘵𝘩𝘪𝘴 𝘸𝘪𝘵𝘩 𝘰𝘯𝘦 𝘴𝘺𝘴𝘵𝘦𝘮!". He then found #Lance and did exactly what he said not to do. 😆
Welcome to Freepik Spaces
A single place where ideas live, connected through real-time workflows
Our CEO and CPO are presenting the future of Freepik live from Upscale Studios NYC
Join the waitlist below
Video diffusion models struggle beyond training resolution → artifacts & repetition.
🎥CineScale🎥 solves this with a novel inference paradigm:
⚡ Dedicated variants for video architectures
⚡ Extends T2I to T2V & I2V & V2V
⚡ 8K images & 4K video, tuning-free/minimal tuning
Expanding the frontier of generative video fidelity.
✊ Kudos to the teamwork led by our intern
@qhnmoon at @eyelinestudios.
#AI #AIResearch #MachineLearning #AIGC #GenAI #videos #DiffusionModels #HighRes #fidelity #ComputerVision #internship
I’ve been a huge fan of the Netflix engineering blog for a long time. So so excited for @lancedb to be an important part of the multimodal AI transformation in data engineering
https://t.co/AMmBOMISFR