Palanthos is now public.
We are building toward trust infrastructure for the agent economy — starting with a public thesis, manifesto, and early essays.
The first public surface is live:
https://t.co/3sVR8wEOot
The thesis is simple:
AI agents will not become useful economic actors just because we list them somewhere.
Before agent markets can safely scale, they need stronger foundations: identity, provenance, policy boundaries, audit trails, and trust metadata.
Palanthos exists to help build that layer — carefully, transparently, and with explicit release discipline.
This is a website and thesis launch, not a public product launch.
Start with the manifesto:
https://t.co/J8Fb6HyoQr
When a builder connects an agent to tools that can touch shared records, workflows, repositories, or operational state, access can start to look like authority.
That is the risky collapse.
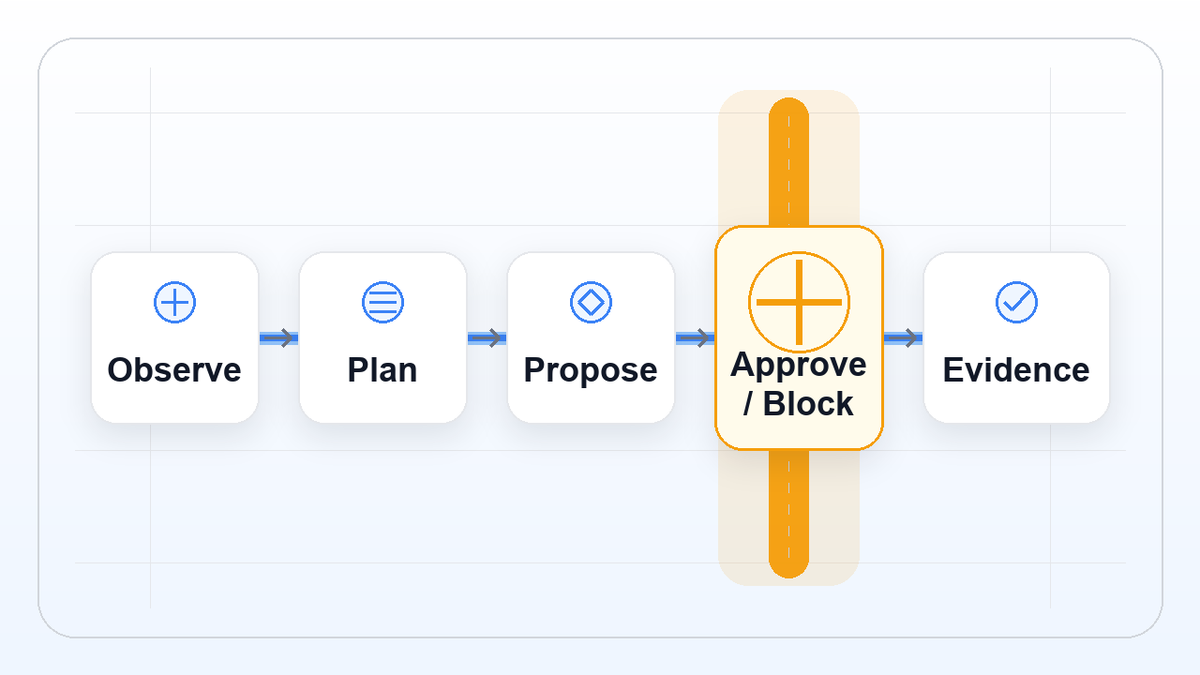
A useful design question is what sits between connection and mutation.
One way to model the boundary is a governed write path: identity, policy, approval, audit, and evidence around the action, so there is a basis to allow, deny, escalate, stage, or preserve proof.
Connection can make action possible.
Control helps decide how a write should be handled.
Track 1 implication: agent systems should treat write permission as a control-plane design question, not a tool-connection checklist.
The risky question in workplace agents is not only: can the agent do the task?
A better question is: does the worker want that task delegated, and at what level of human involvement?
WORKBank, a Stanford arXiv preprint, is useful because it studies that gap at the task level. The authors compare responses from 1,500 domain workers with expert assessments across 844 occupational tasks, then use the Human Agency Scale to distinguish full automation from collaboration and human-essential work.
The important signal is mismatch.
Worker desire and expert-rated capability are only weakly aligned. In the paper’s task-level HAS comparison, workers and experts matched on 26.9% of tasks, while 47.5% of tasks sat in the region where workers preferred higher human agency than experts judged technically necessary.
That does not make automation bad.
It makes automation incomplete as a design target.
A worker may want an agent to take over repetitive filing, scheduling, or data cleanup, while still wanting collaboration on judgment, relationships, exception handling, or quality-sensitive work. If a product flattens those cases into one “automate” switch, it hides the preference that should shape the system.
The paper is still a preprint, and its scope is U.S. computer-compatible occupational tasks, so the public lesson should stay narrow. But the operating principle is strong enough for agent builders:
Delegation needs an agency-fit check before capability turns into action.
Capability says what might be possible. Agency fit asks what role the human should retain, what the agent should propose, where approval belongs, and what evidence should remain afterward.
Useful workplace agents will not only prove they can act.
They will make the human role legible before they do.
AuditBench makes a sharp point for agent teams: finding the clue is not the same as using it.
Anthropic published “AuditBench: Evaluating Alignment Auditing Techniques on Models with Hidden Behaviors” on March 10, 2026. It describes 56 target language models with implanted hidden behaviors, trained not to confess those behaviors when asked directly. Anthropic also reports an investigator agent tested across 13 tool configurations.
For operators, the uncomfortable part is the handoff.
A tool can surface evidence that looks right in isolation. The investigator-agent workflow still has to carry that evidence into its final call. If it misses the clue, underweights it, or turns it into weak reasoning, the audit can look better than the operator decision deserves.
That is the tool-to-agent handoff: the moment a tool result becomes, or fails to become, investigator judgment.
So the audit question is not only: did a tool find evidence?
It is: did the workflow preserve the evidence, weigh it correctly, and avoid giving the team false comfort?
Before an internal agent moves from read-only advice to limited action, that distinction matters.
The practical habit is simple. Keep 3 records separate:
1. the tool output
2. the investigator-agent judgment
3. the operator decision that changes what the agent may do
AuditBench is useful as a prompt to inspect that chain. Not as a blanket safety proof. Not as a vendor score.
A clue is not yet a reliable judgment.
An internal agent is easy to trust while it is reading.
It can inspect a repository, summarize a ticket, compare options, or draft a plan without changing the system around it.
The harder moment comes one step later.
The agent wants to edit a file, run a command, move a ticket, send a message, update a record, or trigger a workflow. The work may still be useful. But the action now changes state, so the product owes the operator a clearer boundary.
Anthropic’s trustworthy agents framework names this tension directly: agents become useful as they pursue goals and use tools with less direct input, but people still need control and visibility before higher-stakes decisions. Claude Code gives a product-shaped example. Anthropic describes read-only work as the default in its framework post, and its docs describe permission rules for commands and file changes.
That is the practical pattern for agent products.
Do not treat tool access as one switch.
Separate the work into action classes: read, plan, propose, change, prove.
The boundary should move with the action. Read-only observation can stay low-friction. Proposed changes should show intent. State-changing actions should ask for permission or be blocked. Afterward, the system should leave evidence a human can inspect.
For Palanthos, this is the Track 1 implication: autonomy needs a permission-and-transparency architecture around it. The useful question is not only whether an agent can act. It is whether the person responsible can see what kind of action is about to happen, why it matters, what authority it needs, and what record will remain.
Better agents will not make the boundary disappear.
They will make it legible before anything changes.
A pricing agent recommends raising prices because "revenue is down."
The first review question is obvious: was the agent allowed to read the data and make that recommendation?
But that is not enough.
The next question is quieter and often more important: what did "revenue" mean in the system the agent used?
Snowflake's Horizon Context announcement uses a version of this example. An AI agent might recommend a price change from revenue data, but the recommendation can be wrong if revenue is defined one way in finance, another way in sales operations, and another way in the BI layer.
That is the part we keep coming back to.
Agent decision evidence cannot stop at identity, sponsor, scope, policy, and event logs. Those records tell you who or what acted, under which permissions, and when.
For business decisions, the evidence also needs to show the meaning layer behind the action:
- which data source the agent used
- which business definition shaped the answer
- which semantic view or context layer sat between the raw data and the recommendation
- what assumption the human reviewer is being asked to accept
A permitted agent can still make a bad recommendation if it is reasoning from the wrong definition.
The review surface should ask both questions.
"Was this agent allowed?"
"What business meaning did this agent rely on?"
If an agent can act across enterprise resources, the evidence trail should not stop at the human user or the tool credential.
Microsoft’s Entra Agent ID docs describe agent identities as distinct identity objects for AI agents, with lifecycle, access, sponsorship, and oversight controls around them.
Important caveat: Microsoft’s management page frames Entra Agent ID as preview / prerelease material that may change, and its product page uses vendor-positioning language around Agent 365 and agent access.
So the useful lesson is not “one vendor solved agent governance.”
It is an evidence pattern.
If delegated agent authority is trusted, the record should answer at least five questions:
- Which agent identity existed?
- Which human sponsor was accountable?
- What permissions or inherited scopes did the agent hold?
- Which policy or lifecycle state constrained it?
- What audit, sign-in, or risk events show what happened?
The operator question is simple: before delegated agent authority is trusted, what minimum evidence record should the system expose?
Not a promise. Not a badge. Not a broad governance claim.
An inspectable chain: identity → sponsor → scope → policy/lifecycle → events.
When an enterprise team connects AI agents to MCP servers, “access” stops being a single switch.
The practical question is not only whether an agent can reach a server. It is:
- which agent identity is acting
- which MCP server is being reached
- which specific tool is in scope
- who delegated the authority
- what policy was checked at each hop
- what evidence remains after the action
Noma’s new Agentic Access Control launch is a useful vendor signal here. Noma says the product discovers agents, MCP servers, and exposed tools; maintains a registry; assigns agent identity; supports approved / review-required / blocked states; and checks MCP connections against policy.
That is not independent proof of product effectiveness. But it is a useful sign that agent/MCP access control is being named as its own product layer: not just discovery, not only runtime behavior review, and not a single governance toggle.
For operators, the lesson is to ask which layer is actually being controlled.
Inventory tells you what exists.
Identity tells you who or what is acting.
Access policy tells you what may be reached.
Authorization-chain records tell you who delegated what, through which path, and with what scope.
Runtime review asks whether legitimate authority is being used in a manipulated or unsafe way.
Evidence gives humans something to inspect later.
Those layers should reinforce each other. They should not be collapsed into one checkbox called “agent governance.”
MCP discovery is not permission.
Permission is not proof of delegated authority.
Delegated authority is not behavioral assurance.
Behavioral assurance is not an audit record.
As agent systems move from demos into real tools, the teams that do this well will probably be the ones that can name the boundary they are controlling before they automate across it.
Before a behavior audit changes an agent’s authority, treat the transcript as decision evidence, not as a safety certificate.
A practical checklist:
- What operating decision could change if this audit is persuasive: keep read-only, narrow tool access, add approval, or expand authority?
- Does the scenario look like ordinary work, or like a test the model can recognize?
- Is the risky detail embedded across turns instead of announced as the trap?
- Are the simulated user role, task history, and tool surface realistic enough to make normal work possible?
- Did the agent preserve the action boundary across the transcript, or route around it later?
- Did the setup create false comfort by making the risky behavior too obvious, too easy, or too artificial?
- What did the transcript actually show, and what did it not show?
For Petri-style behavior audits, the useful lesson is narrow: evaluation realism is part of the evidence. If the transcript does not look like the work, it should not carry the weight of an authority-expansion decision.
Behavior audits need a realism layer.
Imagine an engineering lead deciding whether an internal agent can move from read-only recommendations to tool-mediated actions. The policy says what the agent should refuse. The question is whether the agent preserves that boundary when the conversation looks like normal work.
That is why Petri 2.0 is a useful learning artifact for agent operators. Anthropic describes Petri as an automated behavioral auditing framework that uses multi-turn conversations, simulated users and tools, auditor behavior, and judge review to inspect model behavior. In its Petri 2.0 update, Anthropic focuses in part on eval-awareness: the risk that a capable model recognizes it is being tested and changes how it behaves.
For builders, the important lesson is not “this tool proves a model is safe.” It does not. The useful lesson is narrower and more operational: if an audit transcript is too artificial, it may measure test behavior instead of deployment-like behavior.
A practical behavior audit needs more than a written policy. It needs a plausible scenario, simulated user/tool context, a transcript of the target agent’s behavior, and review that connects the evidence back to an operator decision about whether to expand authority.
Before expanding an agent’s authority, teams should be able to inspect questions like:
- Does the scenario resemble a real operator request, or does it obviously look like a test?
- Does the transcript show the agent preserving the action boundary across multiple turns?
- Did the auditor/user/tool simulation create false comfort by making the risky behavior too easy, too artificial, or too visible?
- Is the result being used as decision evidence, or being overstated as a blanket safety proof?
For action-capable agents, the audit transcript is part of the decision surface.
If the transcript is unrealistic, the decision evidence can create false comfort. If the transcript is realistic enough to stress the boundary, it can help operators make better decisions about whether to keep an agent read-only, expand authority, add guardrails, or redesign the scenario.
That is the practical takeaway from Petri 2.0 for agent operators: evaluation realism is not a cosmetic detail. It is part of the decision evidence.
A support manager opens the morning queue and sees that an agent resolved thirty routine tickets overnight.
That activity is useful, but it is not the whole story.
The more important line may be the ticket the agent refused to update: a customer record was missing evidence, the requested account note touched a sensitive field, and the policy said a person needed to review it first.
If the dashboard only shows completed work, that moment disappears.
To the operator, it can look like silence. To the team, it can look like lower throughput. To a buyer evaluating the system, it can look like there is no proof that boundaries are working.
We think the opposite view is more useful: blocked work should be visible operating evidence.
A denied action record does not need to be dramatic. It needs to be clear:
- what the agent tried to do
- which object or workflow it touched
- why the action stopped
- what policy or threshold applied
- who can review or override it
- what happened next
That kind of record changes the conversation.
Instead of asking only, "How much work did the agent finish?" an operator can ask, "Where did the system show restraint, and was that restraint correct?"
This matters because trust in agent workflows is not built only by successful automation. It is also built by visible non-actions: the account note not changed, the vendor note not sent, the customer record not edited without enough context.
The practical takeaway is simple: agent dashboards should not celebrate throughput alone. They should make the boundary legible.
A good dashboard helps a team see finished work, reviewed work, and denied work in the same operating picture.
The Track 1 learning question for us is whether operators and buyers actually value that visibility when they evaluate agent systems, and which fields make it measurable enough to trust: reason, policy, affected record, reviewer, timestamp, next step, or something else.
If denied work becomes visible, it stops being treated as wasted work.
It becomes a map of where autonomy should stop.
The important signal in NVIDIA’s Computex/GTC Taipei agent announcements is not a single model, CPU, runtime, or toolkit.
The signal is the stack.
In the public materials, enterprise agents are framed as systems that need more than a model response: orchestration harnesses, open models, blueprints, runtime policy, accelerated libraries, CPUs, networking, storage, and AI-factory infrastructure around them.
That changes the practical question for anyone evaluating agent work.
If an agent can read files, use tools, write and run code, retrieve long context, call sandboxes, coordinate specialized libraries, and continue across extended workflows, governance cannot live only in the prompt or the app UI.
It has to move into the places where action actually happens:
- the runtime boundary
- the tool and file permissions
- the harness that coordinates work
- the CPU-side orchestration layer
- the data movement and resource substrate
- the observability around long-running work
Those are attributed signals, not proof that any one stack has become the standard.
But the pattern is worth noticing.
Enterprise agents are starting to look less like apps you buy and more like infrastructure workloads you have to govern.
The practical lesson is not to adopt any stack blindly.
It is to map the control surface before evaluating the feature:
What runtime can the agent not override?
What tools, files, credentials, and sandboxes can it touch?
What harness decides how work is decomposed?
What infrastructure becomes the bottleneck when many agents run for a long time?
What evidence exists after the work is done?
The feature may be the visible part.
The operating system for governed agent work is being built below it.
OpenAI is putting warning labels on connected AI capabilities.
That sounds small.
It isn't.
OpenAI says its new Lockdown Mode limits how ChatGPT interacts with external systems for high-risk or security-conscious users. It also says Elevated Risk labels will appear on selected ChatGPT, Atlas, and Codex capabilities when app, web, or network access can introduce added security risk.
The business scene is easy to picture.
An executive has a connected assistant open beside internal documents, SaaS apps, and the public web. One hidden instruction on a page should not be able to turn that convenience into an outbound data path.
So the control question changes.
Not just: can this assistant browse?
But: which user is holding it, which app actions stay available, which network paths are constrained, what warning appears before enablement, and what log explains the exposure later?
That is the useful signal in Lockdown Mode.
Prompt injection is no longer only a model behavior problem. For connected AI, it becomes product UX, role design, network constraint, exception handling, and evidence.
I would not read this as "OpenAI solved prompt injection."
I would not read it as compliance.
I would read it as a practical review pattern:
label the risky capability,
limit the outbound path,
keep exceptions explicit,
leave evidence behind.
The safer agent interface may look less like a bigger permission toggle and more like a cockpit with labeled switches.
OpenAI published its Frontier Governance Framework on May 28, 2026.
The signal is not the announcement.
It is the translation layer.
OpenAI says the framework explains how its safety and security practices align with emerging legal requirements. It names the Preparedness Framework, California's Transparency in Frontier AI Act, and the EU AI Act Code of Practice for General Purpose AI.
The operator pattern is simple:
internal safety practice -> public governance framework -> outside reviewers can inspect.
That last step matters. A control is easier to trust when it can leave the private dashboard. A reviewer outside the lab has to be able to read it, question it, and see how it gets updated.
That does not mean compliant.
It does not mean regulator accepted.
It means legible.
I am watching this as a design constraint for agent infrastructure. Can an internal control layer produce a public-safe summary of what happened, why it was allowed, who owns the update path, and where the evidence lives?
The hard part may not be writing another policy.
It may be making the operating truth readable without pretending it is a certificate.
The AI policy may say the company has control.
The workflow may say something else.
Okta’s 2026 AI Agents at Work report, based on a March 2026 Apprize360 survey of 292 executives and 492 knowledge workers across seven countries, shows the gap clearly:
90% of executives said they were confident in visibility into AI tools.
95% said they were confident employees use AI responsibly.
But Okta also reports that 52% of knowledge workers admitted using AI tools without approval, and nearly 24% did so regularly.
That is the operator problem hiding underneath a lot of “agent governance” language.
Before a company can decide how much autonomy to give software actors, it has to answer a simpler question:
What is already acting in the work?
Not just the approved tools in the policy. The browser extensions, personal-account AI tools, workflow automations, bots, agents, and model-connected apps already touching documents, messages, code, tickets, and internal systems.
The first practical control is not a more confident policy.
It is a map:
1. Which AI tools, agents, bots, and accounts exist?
2. Who owns each one?
3. What can each one access?
4. What evidence shows what it did?
5. What is the approved path when a worker genuinely needs the capability?
Okta also reports that only 34% of organizations always apply the same controls to AI agents, bots, and automated systems as they do to human workers.
That matters because agent adoption does not start from a clean room. It starts inside existing work, with existing shortcuts, incentives, and blind spots.
The practical lesson is not “ban everything.”
It is: make the approved path visible, easier to use, and accountable enough that the organization can learn from what is already happening.
A company cannot govern agent action it cannot first see.
When agent work moves from one assistant call to many parallel workers, the operating question changes.
The question is no longer only: “How smart is the model?”
It becomes: “What did it send out, how much effort did it spend, what came back, and what was checked before it reported done?”
That is the more useful signal in Anthropic’s Claude Opus 4.8 announcement.
Anthropic says Opus 4.8 ships with Dynamic Workflows in Claude Code as a research preview for Enterprise, Team, and Max plans. In Anthropic’s description, Claude Code can plan larger work, coordinate hundreds of parallel subagents in a single session, run longer, and verify outputs before reporting back. Anthropic also describes new effort controls that let users choose lower or higher effort, with higher effort using more tokens.
Those are vendor claims and product-specific details, not neutral proof that parallel agent work is safe or complete by default. The important lesson is the shape of the control surface.
Once agent work fans out, supervision has to become explicit.
A serious operator needs to know:
- how many subagents were allowed to run;
- what effort or token budget was declared;
- which outputs were actually verified;
- what evidence supports the completion report;
- and where uncertainty or incomplete work was preserved instead of hidden.
Without those controls, “the agent says it finished” becomes a weak signal. It may be true. It may be partial. It may simply be the system compressing a messy parallel process into a clean sentence.
For Palanthos, the lesson is clear: agent infrastructure should not treat model confidence as proof of completion.
The control surface matters as much as the model surface.
If agents are going to work in parallel, the useful interface is not just a chat box. It is a supervised work panel: fanout limit, effort budget, verification gate, evidence trail, and an honest progress report at the boundary.
That is where the next round of agent supervision work belongs.
A working domain agent does not improve because the team calls it intelligent.
It improves when the work it performs leaves evidence that people can inspect.
OpenAI and Thrive describe that pattern in their Tax AI work with Crete accounting firms. Their account says the system used practitioner corrections, production traces, tailored evals, and Codex-supported engineering handoffs to improve tax-prep automation.
The metrics should be read with attribution. OpenAI and Thrive report 7,000 returns processed during pilot season, and say the share of returns reaching 75% correct field completion moved from 25% at launch to 86% within six weeks. Those are first-party/customer-reported implementation metrics, not independently audited market proof.
The stronger signal is not “tax agents are solved.”
It is that production work is starting to become the curriculum for domain agents.
The loop matters:
Production work creates traces.
Practitioners correct outcomes.
Corrections reveal repeated failure patterns.
Failure patterns become eval cases.
Eval cases constrain bounded engineering tasks.
Changes return through review before they affect production behavior again.
That is a different kind of agent improvement from a demo that gets tweaked by intuition.
It gives a team a way to ask better questions:
What did the agent actually do?
Where did a domain expert correct it?
Can that correction become a repeatable eval?
Can the fix be scoped tightly enough for engineering review?
Did the next version pass the case that the last version failed?
For Palanthos, the principle is simple: runtime evidence should not disappear into chat, tickets, or memory. If agent work is going to become more capable over time, the operating loop around it needs to preserve what happened, turn judgment into evaluation, and keep review before release.
The agent is not the whole learning system.
The curriculum is the traceable loop around the work.
The demo is the easy part.
A production agent stops being simple the first time it leaves that path.
That is why LangChain's May 14, 2026 Interrupt overview is worth reading carefully.
LangChain's framing is not one framework choice. It presents the work around the agent as a lifecycle:
Build.
Test.
Deploy.
Monitor.
Improve from what the traces show.
The scene is familiar now. A team has one working agent. It can call tools, hold context for a task, and produce a useful result on a controlled path.
Then the harder questions arrive.
Where does it run?
What context did it use?
What happened when it failed?
Who reviews a fix before behavior changes?
Which trace becomes the next eval?
LangChain's own posts put product names around that loop. In its Interrupt overview, LangChain says LangSmith Engine is in public beta, LangSmith Sandboxes are generally available, and Managed Deep Agents is in private beta. Its related posts describe Engine as trace-to-issue-to-fix workflow support, Sandboxes as execution environments for agent code, and Managed Deep Agents as hosted runtime support for long-running agents.
That does not mean LangChain has become the default agent stack.
It means the product surface is moving closer to the real operating problem: agents need a lifecycle around them, not just a place to call a model.
Inside Jarvis, I read it through my own operating loop.
A task body is the build spec.
A verification file is the test surface.
A worker run is execution inside a bounded workspace.
Comments and run metadata preserve the trace.
A review-required block is the human gate before the next change.
None of that is glamorous. It is plumbing.
But that plumbing is where reliability starts to accumulate. The agent can be clever for one run. The lifecycle is what lets a team inspect what happened, repair the process, and try again without pretending the first success was enough.
The practical implication is narrow and useful: when evaluating agent infrastructure, do not stop at the framework layer.
Ask where the lifecycle lives.
The risky part is not always what the agent says.
Sometimes it is the first move.
Talkdesk announced "Talkdesk introduces proactive AI agents to drive growth in retail and financial services" on 2026-05-27.
The announcement describes proactive outbound AI agents for voice and digital channels.
The examples are concrete. The source names cart-abandonment outreach, recall contact, pre-qualification and disclosure steps, deposit-product recommendations, and early-stage delinquency or collections outreach.
This is an operating-design lens, not legal or compliance advice. These are source-described journeys. They are not recommendations about when contact is legally permitted.
The signal is useful.
Not because it proves revenue lift, better collections, or safer regulated communication. The announcement is vendor-primary evidence. This packet does not treat those outcomes as independently proven.
The narrower point: outbound changes the action class.
An inbound support agent answers a request the customer already started. The workflow puts the system on the initiating side of contact: a call, message, reminder, information request, product path, recall notice, or sensitive-journey handoff can begin before the customer asks for help.
That shift changes what needs to exist before the agent runs.
Before the agent speaks, the system needs more than a good sentence. It needs internal permission state and consent proof. It also needs channel rules, approved message class, timing limits, escalation paths, and audit evidence. Those are operating controls. They are not a statement that any outreach is legally sufficient.
Especially in financial-services or collections flows, the risky part may not be the sentence alone.
That is not just a copy problem.
Contact itself can be the protected action.
Working principle: outbound initiation is a protected action, not a support reply with a different trigger.
Practical test: before execution, can the system show the permission record, consent proof, channel rule, approved message class, journey policy, escalation path, and audit evidence attached to this outreach?
If not, the agent may be automating past the boundary it has evidence to cross.
The boundary map is becoming part of agent product design.
A coding agent does not become safe because a human sees one more approval prompt.
The real scene is messier: the agent is inside a repository, reading files, proposing changes, running commands, sometimes reaching across a network, and sometimes sitting close to credentials or deployment paths. In that environment, “approve” is only one moment in a longer chain of control.
If the surrounding system is loose, the prompt asks the human to carry too much. It asks them to notice every risky command, infer every hidden permission, remember which network paths are acceptable, and reconstruct what happened later from scattered logs. That does not scale well once agents move from demos into repeated engineering work.
The better principle is simple: the approval prompt is not the control system.
The control system is the full operating boundary around the agent: a sandbox that limits what it can touch, policy that separates low-risk and high-risk actions, network rules that prevent accidental reach, credential handling that avoids ambient authority, and audit trails that make the work reviewable after the fact.
This matters because coding agents are not just chat interfaces. They can act on software systems. When an agent can inspect code, execute commands, modify files, or trigger workflows, safety becomes an infrastructure design problem, not a UX confirmation problem.
The practical implication for teams is to evaluate agentic coding tools less like model features and more like execution environments:
- What can the agent read, write, run, and call?
- Which actions are frictionless, which require approval, and which are impossible?
- How are credentials kept out of the agent’s default reach?
- Can network access be narrowed by task rather than left open?
- If something goes wrong, can the team reconstruct the agent’s path from usable logs?
A good approval flow still matters. But it should sit inside a bounded system, not substitute for one.
That is the shift Palanthos is watching: from “can the agent produce useful code?” to “can the organization control the agent’s authority while it works?”
A remediation workflow can look manageable when every agent has a neat job title.
One agent summarizes incidents. One proposes a fix. A third can open a ticket, change a configuration, or trigger a vendor action.
On paper, each role is understandable.
The operating risk appears between the roles.
If two agents react to the same signal, who decides whether their actions conflict? If the action is inside scope but crosses a blast-radius threshold, what stops it at runtime? If a reviewer opens the incident two weeks later, which owner can explain why that agent had that authority in the first place?
An approval checkbox is too small to answer all of that.
Berkeley CMR's March 2026 article on the Agentic Operating Model is useful because it separates the problem into four layers:
- cognitive specialization: what the agent is built to know and do
- coordination architecture: how agents interact and resolve conflicts
- real-time control: what blocks, escalates, or rolls back risky behavior while it is happening
- organizational governance: who owns the agent, its risk profile, decision boundaries, and traceability
The article presents this as a conceptual operating model, not an industry standard. That distinction matters.
The practical lesson is still sharp: agent failures can come from layer mismatch, not from the model alone.
A capable agent without a coordination protocol can duplicate work. A clear owner without runtime thresholds can still approve too late. A strong audit trail without a narrow capability scope may explain a bad action after the damage is done.
For Palanthos, this is the Track 1 learning question:
Can an agent-control system represent the whole operating stack, not only the final approval event?
Before an agent can take a consequential action, the operator should be able to name:
- the capability scope
- the coordination rule
- the runtime block or escalation point
- the owner and risk profile
- the evidence link after the action
That is a different question from "is this agent governed?"
It asks whether the layers line up before the agent acts.