Google’s Gemini roadmap is shifting from “chatbot” to full agentic systems:
• tools + memory
• proactive workflows
• multimodal reasoning
• long-horizon task execution
The interface is becoming the agent. Apps become capabilities. AI UX is changing fast.
Anthropic acquiring Stainless is a strong signal: the SDK layer is now core AI infrastructure.
Stainless powered API/SDK automation for OpenAI, Google, and Cloudflare.
The AI stack is evolving from models → apps into full developer ecosystems.
Agentic AI was about software taking actions.
Physical AI is about software taking responsibility in the real world.
From copilots → coworkers
From workflows → robots
From prompts → perception, planning, and execution
The next interface for AI isn’t just chat.
It’s movement.
12M token context window 🤯
Subquadratic might’ve just broken the biggest bottleneck in LLMs: quadratic scaling.
If this holds → goodbye RAG hacks, hello full-codebase reasoning in one shot.
Granite 4.1 shows the playbook for small LLMs:
It’s not about more compute—it’s about better data.
• 5-stage pretraining with progressive data refinement
• LLM-as-Judge for SFT curation
• Multi-stage RL to boost math, coding, and reasoning
Quality > quantity wins again
The shift:
→ From “code generation” to “code execution”
→ From “prompting” to “environment design”
Sandbox = the new API surface for agents.
Great read 👇
https://t.co/SX52SqyI7I
Hugging Face last week:
• Open-source is scaling fast — but usage is concentrated in a few breakout models
• RAG is evolving — multimodal embeddings + rerankers > generic vectors
Signal is clear:
distribution is power, and retrieval quality is the new moat.
Today’s AI chat UX feels helpful… but it’s often subtly deceptive.
It hides uncertainty, mimics confidence, and nudges users without clarity.
The fix?
👉 Show limits
👉 Expose reasoning
👉 Design for truth, not vibes
AI shouldn’t feel right — it should be right
IronClaw = what OpenClaw should have been 🔐
Same agent power, but:
• Secrets never touch the LLM
• Tools run in sandboxed WASM
• Security is architecture, not a patch
Shift is clear:
LLM decides → system executes safely
This is the future of agent infra. 🚀
Claude didn’t win with a radically better model.
The leaks showed the real edge:
•system prompts as control layer
•tool orchestration > raw intelligence
•modular agents + memory loops
•eval-driven behavior
Not magic weights—just elite engineering.
Google just dropped TurboQuant:
→ 6× less AI memory
→ 8× faster inference
→ 0 quality loss
If this holds, GPUs just got a whole lot “bigger” overnight.
NVIDIA NemoClaw makes always-on AI assistants actually usable 🔥
An open-source stack that runs OpenClaw inside a locked-down sandbox — every network call, file access, and inference is policy-controlled and routed via NVIDIA Cloud.
Secure by design. Always on. No chaos.
Damnn 😱
Most developers are using Claude Code wrong.
They open the terminal...
write a prompt...
and expect magic.
That’s not where the real power is.
Claude Code is actually a 4-layer AI engineering system:
1️⃣ CLAUDE.md → project memory
Architecture, rules, commands, conventions
2️⃣ Skills → reusable knowledge packs
Testing workflows, code review guides, deploy patterns
3️⃣ Hooks → deterministic guardrails
Security checks, enforced rules, automation
4️⃣ Agents → specialized sub-agents
Break complex tasks into parallel workflows
Once you structure these properly, something interesting happens:
Claude stops behaving like a chatbot.
It starts behaving like a real AI dev system.
Most engineers miss this because they jump straight to prompting.
But the difference between average output and production-level results usually comes down to setup.
If you're building with AI agents in 2026, learn the system — not just the prompt.
I made a Claude Code Starter Pack explaining everything.
If you want it:
Follow
Like + RT
Comment CLAUDE
I'll DM it to a few people.
Future AI dev workflows won't be prompt-first.
They’ll be system-first. 🚀
#AI #Claude #AIAgents #LLM #GenAI
Claude just made answers visual.
Charts.
Diagrams.
Interactive widgets.
All generated inline in the conversation.
The future of AI replies isn’t paragraphs — it’s mini apps.
https://t.co/i117114uaa
“Modern local AI stack:
Model → vLLM/llama.cpp → embeddings + vector DB → RAG → OpenWebUI.
Run frontier-level workflows on your own hardware. No API keys required.”
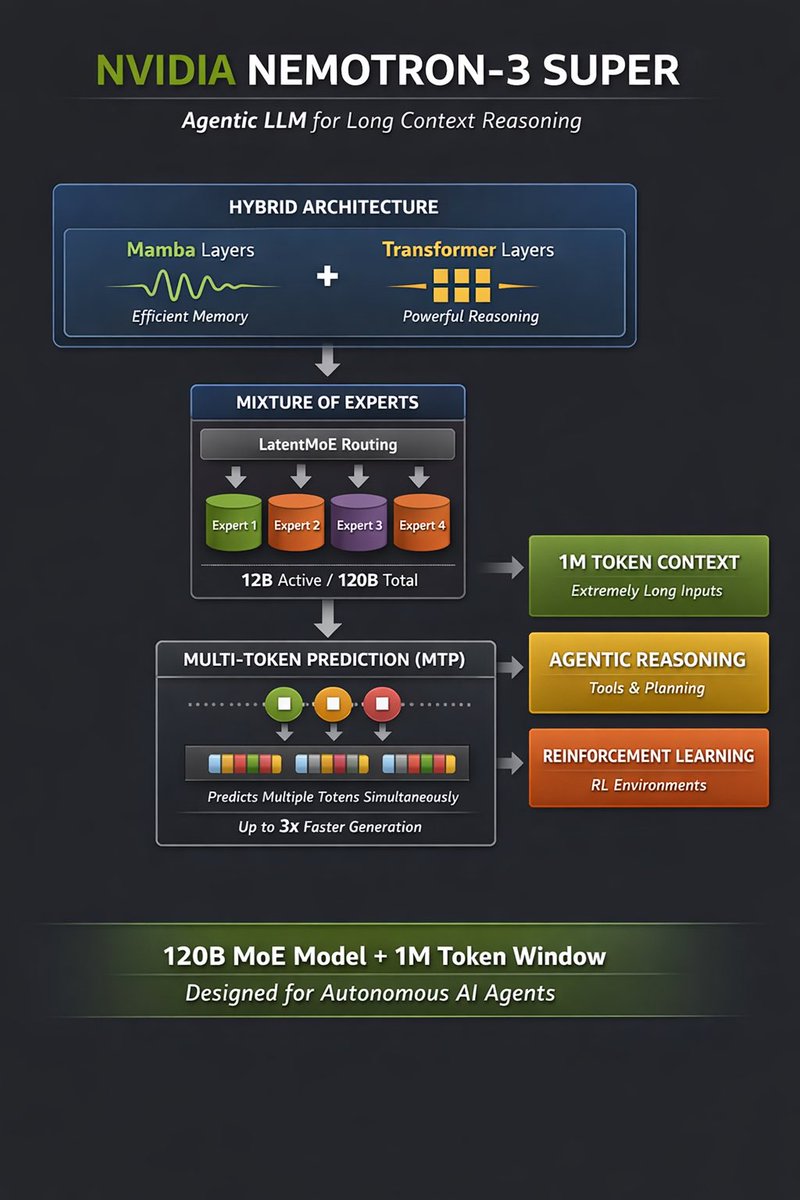
Nemotron-3 Super is an open 120B hybrid Mamba-Transformer MoE model optimized for long-context reasoning and autonomous AI agents with highly efficient inference.
#nvidia#Nemotron
Nemotron-3 represents a shift toward agent-first LLMs.
Instead of optimizing just chat benchmarks, it focuses on:
•long-running agents
•tool-use workflows
•multi-step reasoning
•large-context research tasks.