@iamwil@dardezeu@patio11 It's a style that lets you say more things in a sentence without it devolving into a long series of comma-separated phrases. I think the terseness is a goal in itself though, and not necessarily specific to twitter.
Even ignoring hw utilization, you still want to avoid routing collapse. But maybe that's more about enforcing minimum usage than max usage? If an expert is chosen <5% as often as the average, that expert is almost certainly wasted and undertrained. But if an expert is chosen 5x as often as the average, that could just mean it's a generically useful function. I think shared experts are a concession to this, but there could be more granularity than "perfectly balanced" vs "always activated"
Re 2, it does seem like the variance loss should eventually load balance, but maybe that effect is not strong enough? Would be worth trying.
Not the same, but this paper claims you can replace lb loss with an orthonormality loss on the router weights, and it still load balances. https://t.co/02se1meOZ3
The global-batch vs microbatch/sequence-wise lb loss distinction from the demons-in-the-detail paper you linked above seems important. With sequence-wise lb loss, you couldn't possibly get eg specialization by language, like they do in the last few layers, so I'm suspicious of a lot of the earlier papers that claim to get some kind of data-domain specialization while using microbatch-wise lb loss.
.@essential_ai's rnj-1 model is now on Ollama!
ollama run rnj-1
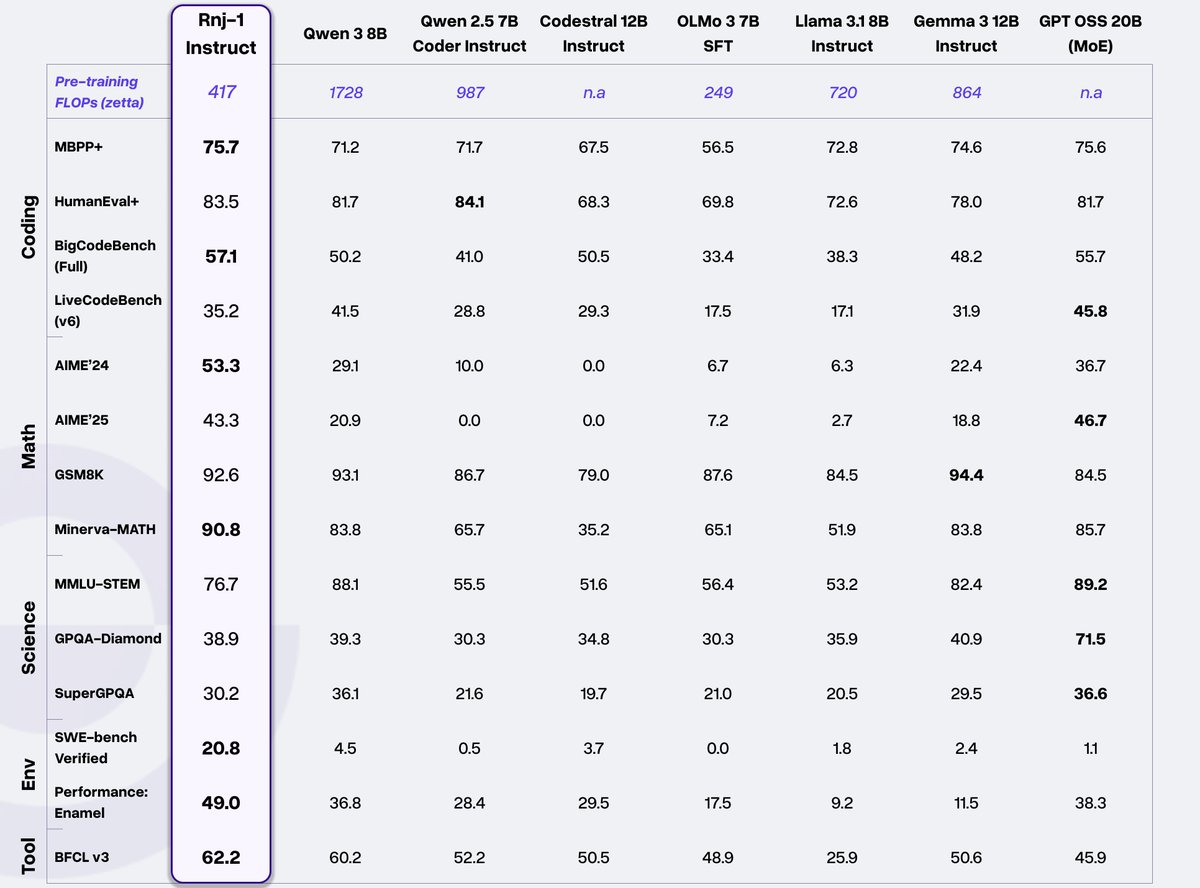
8B parameter, open-weight dense model trained from scratch. The model is optimized for code and STEM with capabilities on par with other state of the art open-weight models.
Let's go! 🚀🚀🚀
We are beyond thrilled to share our first flagship models, Rnj-1 base and instruct 8B parameter models. Rnj-1 is the culmination of 10 months of hard work by a phenomenal team, dedicated to advancing American SOTA OSS AI.
Lots of wins with Rnj-1.
1. SWE bench performance close to GPT 4o.
2. Tool use outperforming all comparable open source models.
3. Mathematical reasoning (AIME’25) nearly at par with GPT OSS MoE 20B.
….
Today, we’re excited to introduce Rnj-1, @essential_ai's first open model; a world-class 8B base + instruct pair, built with scientific rigor, intentional design, and a belief that the advancement and equitable distribution of AI depend on building in the open.
We bring American open-source at par with the best in the world.
@hastuc_dibtux I wish I knew, because I'm not satisfied with what I'm doing (juggling ymls overriding parts of files like this: https://t.co/euBCzA38or)
@hastuc_dibtux The performance difference between flash v2 and v3 is like double, and that's just adding like ping pong scheduling. It's a deep rabbit hole and also completely non-optional for anything at scale.