📚 PhD Student @utexasece @WNCG_UT @VITAGroupUT; 🌟 Stanford Rising Star in Data Science 2025; 🎓 Google Fellowship 2025 in ML & ML foundations; 🎄@ccccrs_0908
Interestingly, we revealed a duality:
🔵 Training-time alignment ≈ amortized parameter-space optimization
🔵 Test-time optimization ≈ latent space sampling
From a classical statistical inference lens, these two are tightly connected, just operating over different spaces.
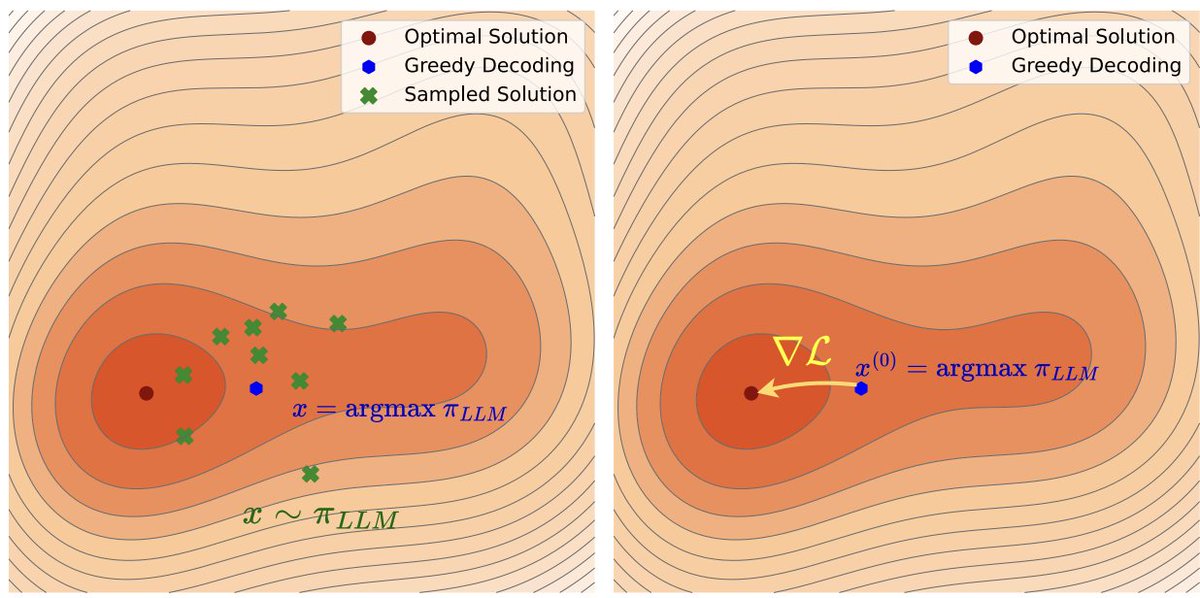
Latent space reasoning via looped transformers has gained attention lately. It is rooted in optimization unrolling , where each loop implicitly models a GD step on hidden states. Our ICLR paper studied what if we explicitly run GD in latent space at test time?
1/🧵 What if test-time reasoning wasn't discrete search, but gradient descent in latent space?
Happy to share our #ICLR2026 paper ∇-Reasoner: a paradigm shift from zeroth-order search to first-order optim at test time. Led by @peihao_wang@ccccrs_0908
https://t.co/MgoSQ8lyXG
We formulate decoding as an optimization problem: find responses that maximize a differentiable reward subject to being sampled from an LLM . Gradients are backpropagated into the model’s hidden states, steering inference into a form of test-time training.
"One static model does not fit all."
Reminds me of the old parametric vs. non-parametric regression debate. Nice to see scalable generative weight-space models finally taking shape.
One static model does not fit all😭
We just dropped our latest work: Functional Neural Memory. Instead of static models, we generate custom "parameters" for every single input.
✅Prompt your model anytime
✅Instant personalization
✅Better instruction following
✅Flexible & dynamic memory (w/o memory bank✌️)
(🧵1/6)
Are multi-agent systems necessary?
Here is a great new paper addressing this.
The big assumption most AI devs make today is that more agents lead to better performance.
But here is the overlooked reality: most multi-agent systems are homogeneous.
All agents typically share the same base LLM, differing only in prompts, tools, and positions in the workflow.
This raises a compelling question of whether a single agent can simulate these workflows through multi-turn conversations.
This new research investigates this across seven benchmarks spanning coding, mathematics, QA, domain-specific reasoning, and real-world planning.
A single agent with KV cache reuse can match the performance of homogeneous multi-agent workflows while reducing inference costs.
The cost advantage comes from shared KV cache across agent interactions, avoiding redundant prefill computation.
Because homogeneous agents possess identical reasoning capabilities and differ only in specialized instructions, a single agent can role-play these agents sequentially, exploiting the workflow's task decomposition without needing separate model instances.
Building on this finding, the researchers propose OneFlow, an algorithm that automatically designs workflows optimized for single-agent execution.
OneFlow uses a dual meta-LLM architecture (Creative Designer + Critical Reviewer) with Monte Carlo Tree Search to discover streamlined workflows with comprehensive system prompts and fewer total agents.
OneFlow with single-agent execution achieves 92.1% on HumanEval, 81.4% on MBPP, 93.3% on GSM8K, matching or exceeding multi-agent baselines while significantly reducing cost.
Single-LLM methods cannot capture truly heterogeneous workflows where agents use different base models, since KV caches cannot be shared across different LLMs.
These results position single-LLM implementation as a strong baseline for MAS research. The authors suggest that the real opportunity lies in developing heterogeneous systems where model diversity benefits outweigh coordination costs.
Paper: https://t.co/Y6wCAfqrMN
Learn to build effective AI agents in our academy: https://t.co/zQXQt0PMbG
Thank you, @JeffDean. Really honored to join the 2025 class of Google PhD Fellows! Excited to carry forward the inspiration to explore the AI frontier where logics and physics meet algebra and geometry.
This work is so special to me. I first touched cryo-EM as a junior - couldn’t believe a neural net could predict bio structure from extremely low SNR, unposed images. with so many AI progress in these 5 years, scaling laws make AI-driven protein discovery feel real
DUSt3R-like models work for scientific imaging too! Our ICCV’25 paper “CryoFastAR” shows that a geometric foundation model can do feed-forward ab initio cryo-EM reconstruction—10× faster and state-of-the-art quality on noisy particle images! #ICCV2025#CryoEM
📎Paper: https://t.co/jqlpBmi5G5
We already introduced #LightGaussian last year to accelerate the rendering speed of 3DGS.
In our CVPR'25 paper, SteepGS, we go further by demystifying and improving density control during 3DGS optimization — making training more efficient and reliable.
Project Page: https://t.co/kzyNTBeo2T
Layer-wise routers are surprisingly redundant in current MoE. Check out Read-ME for the system-friendly MoE refactorization technique with system co-design!
🚀 Our NeurIPS '24 work, Large Spatial Model (LSM), is here! LSM performs semantic 3D reconstruction in just 0.1s, processing unposed data via feed-forward 3D reconstruction.
👉It leverages large-scale 3D datasets with minimal annotations, defining a 3D latent space. We are continuously exploring how this explicit 3D representation can further enhance reasoning and robotic learning.
🔗 Try our online Gradio demo with your own data at https://t.co/FjGsPkcJ6h
#NeurIPS2024 #3DReconstruction
Introducing Score identity Distillation with Long and Short Guidance (SiD-LSG), our data-free solution to distill Stable Diffusion models into one-step text-to-image generators, achieving a COCO2014 zero-shot FID of 8.15. Excited to share the code and checkpoints with the community!
Code: https://t.co/hM2BDH2Spe
Paper: https://t.co/mJp5WFqWub
#Diffusion #Distillation #StableDiffusion @ZhendongWang6@UnderGroundJeg@haihuang_ml
Tired of training varying-size LLMs to fit various GPU memory and latency requirements? Check out Flextron! Our new ICML (Oral) paper shows how to train one model deployable across GPU series. Learn more: https://t.co/aPEgVIyfqq🚀
The Flextron-Llama2-7B model family demonstrates superior MMLU performance compared to both open-source models (including Pythia, OpenLLaMA-v2) and existing post-hoc compression methods (including Sheared-LLaMA, SliceGPT, LLM-Pruner, Compresso, LaCo).
Managing long context is challenging due to quadratic attention memory usage. But what if we could compress growing context information into a fixed-size memory? 🤔
Check out our new ICML paper: "LoCoCo: Dropping In Convolutions for Long Context Compression"!
1/3
Training 3D foundation models? In our CVPR2024 work, we propose a new concept that directly enhances 2D prediction’s view consistency via image based rendering. It generalizes to many 2D foundation models in zero shot and transfers their success to 3D at little training cost.
Progress in 2D vision models has been exciting, e.g. SAM, DINO, etc. But how do we apply them on a 3D scene?
We propose Lift3D, a plug ‘n play framework that converts any arbitrary 2D vision model to be 3D consistent w/o any extra optimization.
https://t.co/lLOFR0Pa0w