We've updated the popular article introducing star schemas for Power BI at https://t.co/mntVuhUvYl
The article also contains ~20 new diagrams to help explain concepts or use in your presentations.
#PowerBI#MicrosoftFabric#AnalysisServices
@elonmusk Sophism again. My personal POV The strong guy has a responsibility to use his force for good, does not mean he’s bad to use, or just to have force.
I saw Dune: Part Two at a private studio screening, and it is gratifying to see my father's story told with such great care. When the new movie is combined with Dune: Part One it is by far the best film interpretation of Frank Herbert’s classic novel DUNE that has ever been done
🚀 Le @Conseilinno_qc vient de publier le rapport crucial "Prêt pour l'IA", marquant un pas de géant vers l'avenir de l’#IA dans la province.
“Chez IVADO, nous sommes profondément engagés à contribuer à cette vision”. Lire la suite de l'article 👇
https://t.co/uvQpecD41S
That's a wrap!
Hope you enjoyed it.
If you find this post helpful, please :
1. Follow me @CodeByPoonam for more.
2. Like/Repost the first tweet below for support.
Any #PowerBI experts looking for a job? I am hiring.
Reasons to join my team:
1. Learn more here than anywhere else.
2. Very laid back team that loves joking around.
3. 'Big data' is 900 billion rows.
4. The pay is good.
Experts only. Seriously.
https://t.co/lfZWXodavC
WOW! @SES_Satellites operates 70+ satellites in 2 different orbits, with global reach + an intelligent network of satellite & ground infrastructure that delivers high-performance video & data solutions virtually everywhere on Earth: https://t.co/OHlcgmAt4n
#BigData#SatelliteData
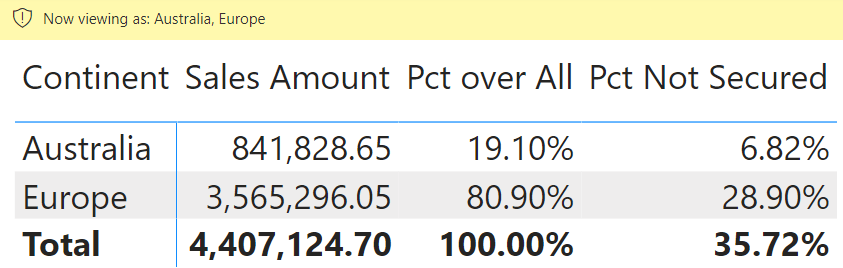
This article+video shows how to compute ratios when row-level security hides some of the data, and you need a percentage that includes the hidden rows in the comparison.
#powerbi#dax
https://t.co/kV5n5o0hMo
Mila is looking for talented new minds to join its community in the Fall of 2024! Our annual supervision request process is open until December 1st.
Apply today ➡️ https://t.co/W6jXqEtAzx
Mila est à la recherche de nouveaux et nouvelles étudiant·e·s pour rejoindre sa communauté à l'automne 2024! Notre processus annuel de demande de supervision est ouvert jusqu'au 1er décembre.
Appliquez dès maintenant ➡️ https://t.co/Fsp3b5Bhh6
Improving LLM Performance - The Various Ways to Fine-Tune your LLMs
There will be cambrian explosion of smaller LLMs give the AI executive order that regulates really large models
While these models won't be as performant as the GPT-4 out of the box, there are different techniques that can be applied to fine-tune them and make them match big model performance for a specific use-cases.
This is also a worth while endeavor at scale, as it's a substantial saving (almost 60x) to run smaller, more efficient models that match performance
Here are the different ways you can fine-tune an LLM for your use-case
Supervised Fine-Tuning - This is most common and you need a task specific labeled dataset.
A popular technique, LoRA involves adding low-rank matrices to pre-existing layers within a large pre-trained model. These low-rank matrices are relatively small in terms of the number of parameters, but they are powerful in adapting the model for specific tasks.
The idea is to fine-tune only these added low-rank matrices while keeping the original large-scale parameters frozen.
This technique makes a lot of sense when you have a specific task like summarization or extracting terms from your procurement contracts and you have some examples or labelled data
LoRa fine-tuning of Llama-2, shows performance almost on par with full-parameter fine-tuning, and even outshines GPT-4 in specialized tasks like generating SQL queries or text-based functional representations.
Over at Abacus AI we have used LoRa method successfully and matched GPT 4.0 and fine-tuned versions of GPT 3.5's performance
Domain-Specific Fine-Tuning - You can also use a corpus of specialized data to fine-tune model. For example: PMC-LLaMA, is an effort to build open-source language models for medicine. This model was fine-tuned with a staggering 4.8 million biomedical academic papers and 30K medical textbooks.
Clinical LLaMA-LoRA fine-tunes the pre-trained Llama to the clinical domain for downstream clinical tasks, illustrating the model's adaptability to healthcare-specific challenges
Reinforcement Learning-Based Fine-Tuning:
Reinforcement learning algorithms like Proximal Policy Optimization (PPO) are used to optimize a policy, which in this context is the model's parameterization for generating sequences of tokens. The optimization is guided by a reward function, which quantitatively evaluates the quality of generated sequences. This technique allows the model to learn more complex, multi-step reasoning and adapt its responses based on the reward signals. The feedback or the rewards used for fine-tuning could come from various sources like predefined metrics, domain-specific criteria, or even automated systems.
Human Preference-Based Fine-Tuning - In this approach, human evaluators provide comparative rankings of different outputs generated by the model for the same prompt. These rankings are used to construct a reward model, essentially a function that maps from model outputs to scalar rewards. The model is then fine-tuned using reinforcement learning techniques, often PPO, guided by this reward model. This iterative process enables the model to align closely with human preferences and values. RLHF where you align the model to human values falls into this category but you can also use this method where you can receive human feedback from a chat bot's responses or content recommendations
Few-Shot Learning - Few-shot learning in the context of large language models involves providing a few example tasks directly within the prompt to guide the model's behavior. Technically, this does not involve retraining the model but exploits the model's inherent meta-learning capabilities. The model generalizes from the examples to perform the specific task at hand, effectively leveraging its pre-trained parameters to adapt to new tasks without explicit fine-tuning. This can be super effective with GPT-4 but also works with simpler tasks on Llama-2 or Abacus Giraffe.
Always try few-shot learning or in-context learning before trying fine-tuning or anything more sophisticated. It's an order of magnitude simpler.
In summary, my prediction is that the pace of innovation on very large LLMs will slow down and there will be an explosion of small LLMs (hopefully more open source in the the next couple of years).
Enterprises who don't want to be too dependent on OpenAI can leverage these smaller LLMs and have them purpose built for their tasks at reasonable prices.
LLM platforms and models will continue to be democratized
The Biden-Harris administration has issued an Executive Order on AI safety. This is a big one!
Based on the Fact Sheet, here are some of the interesting parts of the EO ↓