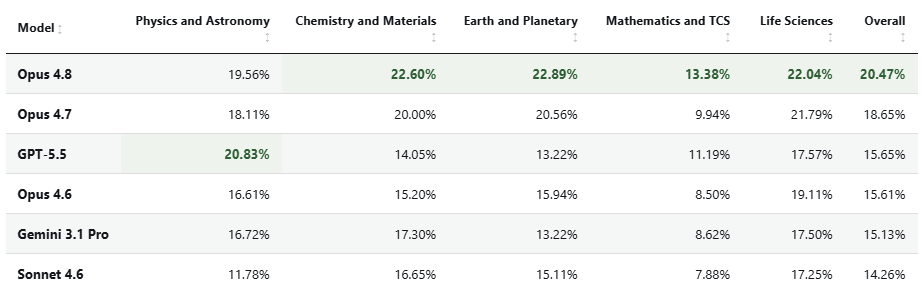
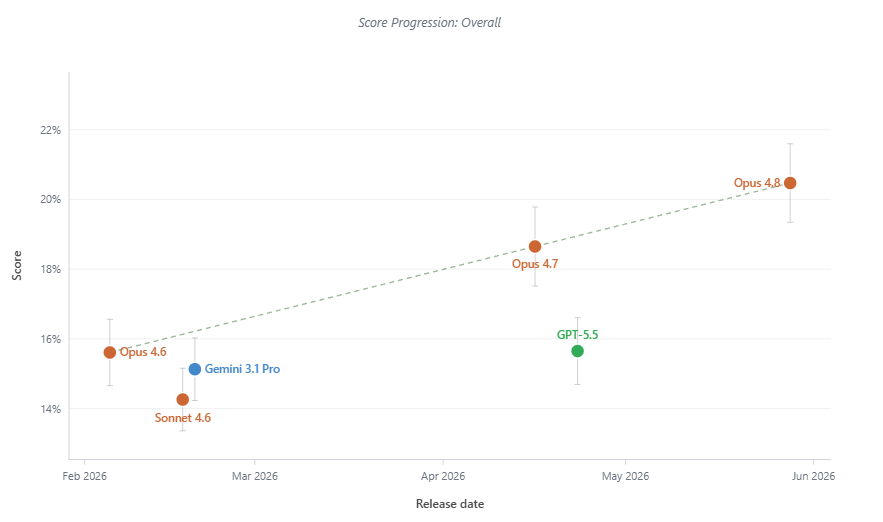
Claude Opus 4.8 is an incremental but noticable improvement and leads the Singularity Gate with 20.47%. But still no model fully predicts a discovery. Opus 4.7 is 2nd, GPT-5.5 is 3rd.
I've spent the past few weeks reading 100s of public data sources about AI development. I now believe that recursive self-improvement has a 60% chance of happening by the end of 2028. In other words, AI systems might soon be capable of building themselves.
@scaling01 It seems the first jump was related to the department of war fiasco both the Trump administration and OpenAI caused though, in the beginning of March.
@bindureddy They should also make the model smarter, and more agentic. Opus and Claude Code feels more like an actual smart agent that know you and your intent.
@arcprize No surprises here as my own benchmark, the Singularity Gate, has shown Claude Opus 4.8 is clearly smarter than other models as well. And it's at "high" effort. Not max or even xhigh.
https://t.co/x4Bl6jjwow
Claude Opus 4.8 is an incremental but noticable improvement and leads the Singularity Gate with 20.47%. But still no model fully predicts a discovery. Opus 4.7 is 2nd, GPT-5.5 is 3rd.
No surprises here as my own benchmark, the Singularity Gate, has shown Claude Opus 4.8 is clearly smarter than other models as well. And it's at "high" effort. Not max or even xhigh.
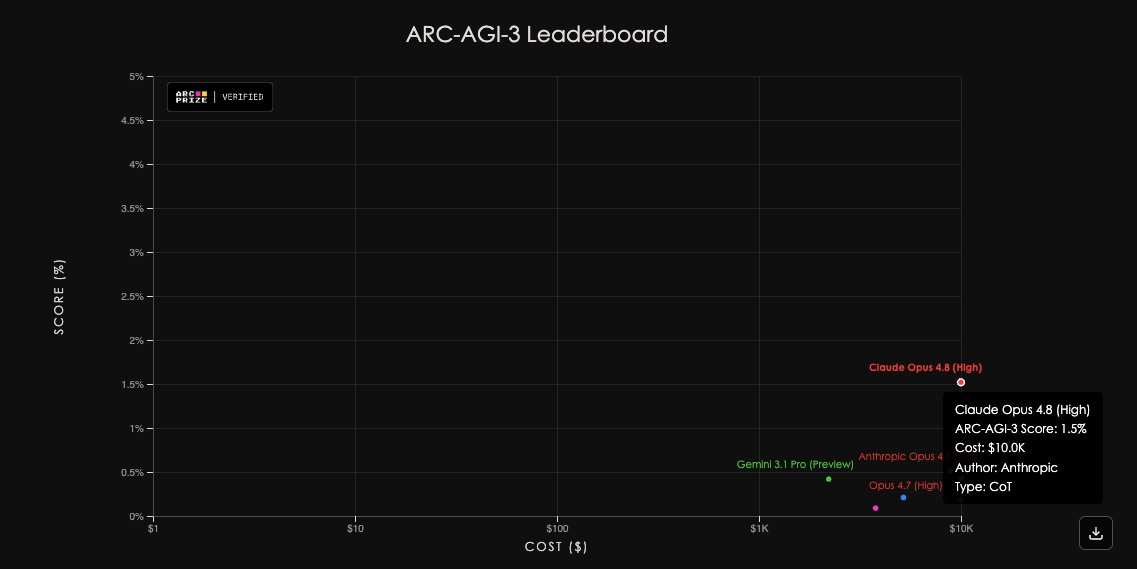
Anthropic Opus 4.8 is new SOTA on ARC-AGI-3
Score: 1.5%, ~$10K
ARC-AGI-3 analysis notes:
* Opus 4.8 read the environment an abstraction *above* Opus 4.7, as objects & systems, not pictures
* Opus 4.8 succeeded on early levels, but still committed to a wrong sub-goal
@fbneistersen Pierre Sage'yi Crystal Palace almak üzere. Ne yapın edin devreye girip getirin. 100% şampiyon yapar, rahat yapar. An itibariyle açık ara farkla dünyadaki en iyi teknik direktör. Yapay zeka şirketimde zaten teknik direktör, santrafor, ve kaleci önerileri yapıyoruz.
@yagosabuncuoglu Adam 23 nisanda görüştüm diyor. Nereye görüşeceğini açıklamış? Seçimi kazanırsa Hakan Safi, Fenerbahçe'yle alakalı her yerden men edilmelisin sen, tatlı su kurnazı seni. @fbneistersen
In the Singularity Gate, Claude Opus 4.8 at 'xhigh' performed worse than its 'max effort' setting, matching Opus 4.7's max effort. Since the benchmark only tracks each model's best configuration (highest effort, agentic harness & tool use allowed), its results have been excluded.
Claude Opus 4.8 is an incremental but noticable improvement and leads the Singularity Gate with 20.47%. But still no model fully predicts a discovery. Opus 4.7 is 2nd, GPT-5.5 is 3rd.
Claude Opus 4.8 leads in four of five scientific fields; GPT-5.5 leads in Physics & Astronomy. Per-field breakdown is below.
For more information about the Singularity Gate head over to the site or check the paper:
Paper: https://t.co/miqCc6YPq9
Website: https://t.co/E4w7puXzFa
Claude Opus 4.8 is an incremental but noticable improvement and leads the Singularity Gate with 20.47%. But still no model fully predicts a discovery. Opus 4.7 is 2nd, GPT-5.5 is 3rd.
We've seen a steady improvement with Claude Opus models in the Singularity Gate. They're getting closer to fully predicting a discovery. We'll probably see the first ones with Mythos.
The Singularity Gate results for the new Claude Opus 4.8 is coming in the next 24 hours! The contamination audit flagged a few discoveries for Opus 4.8, so those're removed from the corpus. Because of that small score changes for all models should be expected.
@fbneistersen Daha önce de mesleğimden bahsetmiştim. Pierre Sage şu an Fenerbahçe (ve birçok takım) için dünyadaki en iyi teknik direktör. Ne kadara ikna ediyorsanız edin. Takım değerini 1.5 ile çarpacak kadar etkisi var. 300 milyon euroluk takımdan 450 milyon euroluk performans alır.