EXPLAIN says Seq Scan. Your gut says Index Scan. You wrote that index for this query.
Planner is usually right, gut is usually wrong. Tell which is right today by reading two columns side by side.
https://t.co/dtTTnU9VPm
Inference pod schedules onto a fresh GPU node. Image is 8GB. ContainerCreating for 90 seconds.
That's 90 seconds your HPA spent waiting for the replica it asked for two minutes ago. The autoscaler is now open-loop.
https://t.co/tKzP4y7K1L
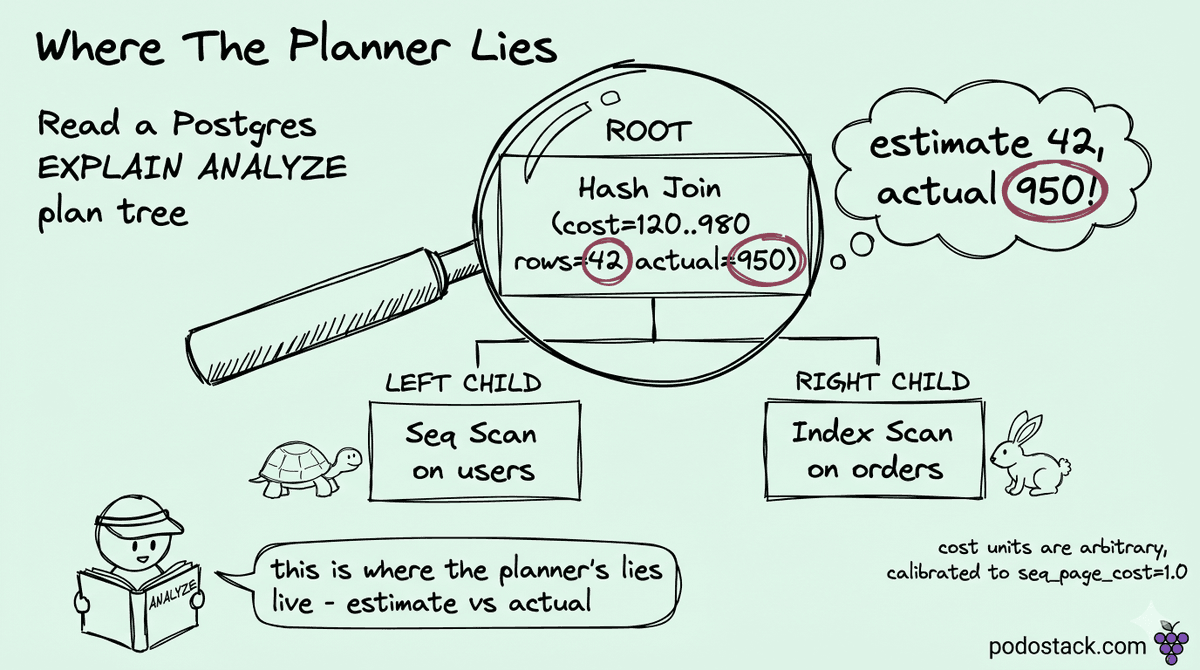
Read the rows column, not the cost number. Cost is the planner's guess. The estimate-vs-actual gap is the diagnostic.
Add BUFFERS to tell warm-cache fast from cold-cache slow.
https://t.co/dtTTnU9VPm
EXPLAIN says Seq Scan. Your gut says Index Scan. You wrote that index for this query.
Planner is usually right, gut is usually wrong. Tell which is right today by reading two columns side by side.
https://t.co/dtTTnU9VPm
Causes of estimate-vs-actual blowouts:
- stale stats after a bulk load (ANALYZE fixes it)
- correlated columns multiplied as independent (CREATE STATISTICS)
- skew past the top-100 MCVs (bump default_statistics_target)
- functions hiding the column (index the expression)
The bet pays when pulls are predictable.
For multi-tenant clusters, wide image sets, one-off jobs - go back to Stargz lazy reads or Spegel P2P. The three together kill cold start. Preload is the one for big known images.
https://t.co/tKzP4y7K1L
Inference pod schedules onto a fresh GPU node. Image is 8GB. ContainerCreating for 90 seconds.
That's 90 seconds your HPA spent waiting for the replica it asked for two minutes ago. The autoscaler is now open-loop.
https://t.co/tKzP4y7K1L
Why AI/ML is the textbook case: same model server image, dozens of GPU nodes, 6-12GB per image, the set is small and known in advance.
Spark executors, stateful DBs on dedicated pools, GPU training fleets all have the same shape. Predictable workload + big images = preload pays.
Three approaches to cold image pull. Three philosophically different bets on the same problem.
Stargz says be lazy. Spegel says be local. Preload says be early. Same 8GB image, three different shapes.
https://t.co/tKzP4y7K1L
Most serious teams pair Preload with Spegel. One node pulls upstream, peers serve the rest. Stargz handles the long tail the ImageCache didn't predict.
Single-philosophy fixes the median. Layered fixes the tail.
https://t.co/tKzP4y7K1L
Three approaches to cold image pull. Three philosophically different bets on the same problem.
Stargz says be lazy. Spegel says be local. Preload says be early. Same 8GB image, three different shapes.
https://t.co/tKzP4y7K1L
Where each pays:
- Stargz: wide, shallow image sets (CI runners, ephemeral workers)
- Spegel: large clusters, same image rotating across hundreds of nodes
- Preload: narrow, stable sets on known nodes (AI inference, Spark, GPU)
Pick by image-set shape.