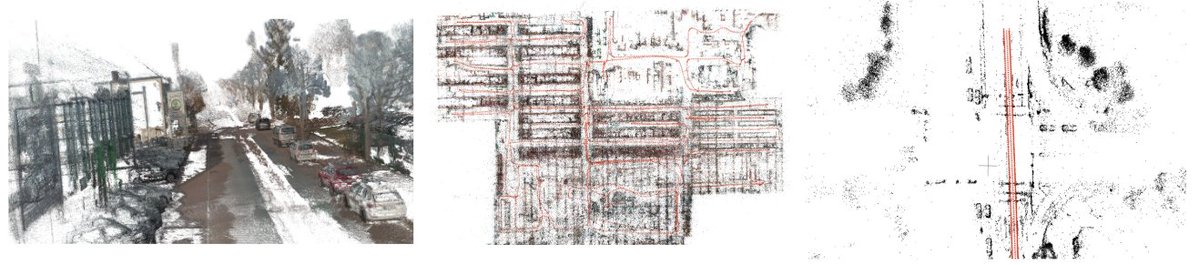
We are excited to release the code for our paper OpenVO: Open-World Visual Odometry with Temporal Dynamics Awareness, accepted to #CVPR2026.
Source Code: https://t.co/na6fLrmzE8
From a dashcam video, OpenVO estimates how the camera of the vehicle moves in metric scale.
A few years ago, learning robot learning meant stitching together dozens of papers and courses — with no clear path from the basics to what state-of-the-art systems actually do.
This was one of the motivations behind creating @ETH's course "Robot Learning: From Fundamentals to Foundation Models", to provide a structured path from first principles all the way to modern foundation models for robotics.
I strongly believe that education should be accessible to everyone, so I have made all lecture recordings publicly available on YouTube.
Creating this course was one of the most challenging projects I have taken on. It was my first time designing and teaching an entire curriculum from scratch, while simultaneously working full-time in industry. On top of that, the course proved to be more popular than expected and we had to scale it to almost 300 students, which was only possible thanks to an amazing team of TAs. Looking back, it was an absolute privilege to teach this class and an incredibly rewarding experience.
If you are getting into robot learning, this is the starting point I wish I had.
📚 Main lectures:
https://t.co/r1PpQASaJg
🎤 Guest lectures:
https://t.co/nh5Rm2P2Lz
🌐 Course website: https://t.co/DoQUYy3MjB
Introducing VGGT-Ω: scaling feed-forward reconstruction across static and dynamic scenes, and studying whether the learned geometric representations transfer beyond reconstruction.
We propose a novel temporal-dynamics-informed, camera-aware and geometry-aware visual odometry system. Our method takes consecutive dashcam frames as input and extracts both temporal and geometric representations for robust egomotion estimation.
https://t.co/n6ohBEcazj
We are excited to release the code for our paper OpenVO: Open-World Visual Odometry with Temporal Dynamics Awareness, accepted to #CVPR2026.
Source Code: https://t.co/na6fLrmzE8
From a dashcam video, OpenVO estimates how the camera of the vehicle moves in metric scale.
🚀🚀 Introducing Pixal3D (SIGGRAPH’26) — a new pixel-aligned image-to-3D generation paradigm for high-fidelity 3D asset creation.
Today’s Image-to-3D has become pretty good at producing plausible 3D assets. But plausibility is not enough. Fidelity is a hidden bottleneck.
❓A generated model may look “about right,” yet still fail to truly align with the input pixels. Can we make 3D generation as faithful as reconstruction, while still allowing it to complete the unseen?
Pixal3D is our answer.
💡We believe the core bottleneck behind fidelity is 2D–3D correspondence. Most 3D-native generators synthesize shapes in canonical space and inject image cues through cross-attention, forcing the model to implicitly search for which pixels correspond to which 3D regions.
🍀Pixal3D takes a different route. Instead of generating in canonical space, Pixal3D generates directly in pixel-aligned camera space — what you see is what you get. The generated 3D asset is aligned with the input view from the start.
☕️Meanwhile, Pixal3D introduces back-projection-based image condition scheme - explicitly back-projects multi-scale pixel features into 3D voxels, thus resolving the 2D-3D association problem. The input image is no longer just a prompt - it becomes a geometric anchor.
🚩Pixal3D shows that pixel-aligned 3D generation is not only feasible and scalable, but also significantly improves fidelity, pushing 3D-native generation closer to reconstruction-level faithfulness. It also naturally extends to multi-view and scene-level 3D generation.
✅Faithful to the input view. ✅Generative for the unseen.
Closer to reconstruction-level fidelity, with the creativity of 3D generation. Pixal3D also represents an effort towards the unification of 3D generation and reconstruction.
📢Paper, code, and demo are fully released — try it out and let us know your feedback!
🌐Project page: https://t.co/Y1oKzZZrkZ
🤗Huggingface Demo:
https://t.co/4QoDdHMOsk
💻Code:
https://t.co/xwkNNQTMha
📄Paper:
https://t.co/UgiNH00PEY
NAS3R
[CVPR 2026] From None to All: Self-Supervised 3D Reconstruction via Novel View Synthesis
NAS3R is a self-supervised feed-forward framework that jointly learns explicit 3D geometry and camera parameters with no ground-truth annotations and no pretrained priors.
RecGen.
turns sparse photos into complete, simulation-ready 3D scenes.
You feed it one RGB-D snapshot of a cluttered environment, and get 3D shapes, textures, and precise poses for every object.
- reconstructs even heavily occluded or symmetric objects.
- built on TRELLIS-image-large.
https://t.co/67UclGQ402
Watch your 3D segmentation model learn live!
I just added a viser visualizer to the WarpConvNet ScanNet example: three side-by-side panels (input RGB / ground truth / prediction) refresh every few seconds during training. https://t.co/HtsmNKFqIY
Scaling 3D scene data is a long-standing challenge in scene understanding, spatial reasoning, and robotics. Since scanning, reconstruction, and labeling are so labor-intensive, data scarcity has remained a major bottleneck. 🛑
To solve this, we propose SceneVerse++: Lifting Unlabeled Internet-level Data for 3D Scene Understanding (CVPR 2026). By reconstructing internet videos and annotating 3D scenes automatically, we’ve created a massive real-world dataset for end-to-end understanding. 🌐📐
SceneVerse++ makes it easy to scale "in-the-wild" 3D scenes toward more capable spatial reasoning systems. This significantly promotes progress in 3D VQA, visual navigation, and broader tasks in Embodied AI and Robotics. 🤖🦾
We are fully open-sourced! Check out the paper, code, and data here:
🌐 Project: https://t.co/d5qXI7G6WL
📄 Paper: https://t.co/46OIUZBSDO
📊 Dataset: https://t.co/2td6Yla3ON💻 Code: https://t.co/u9QyQWHy0Z
Meta just released Sapiens2 on Hugging Face
High-resolution vision transformers pretrained on 1 billion human images,
for human-centric perception: pose, segmentation, normals, and pointmaps.
🚀We just released Asset Harvester, an image-to-3D model and end-to-end pipeline that extracts real object assets from autonomous driving videos!
🌐 Website: https://t.co/vXnFVW1ui8
💻 Code: https://t.co/3q3vcRvojy
[1/5]
#AssetHarvester#AVSimulation#WorldModel #AutonomousDriving
PyCuSFM: Cuda Accelerated Structure from Motion
This repository provides the official python implementation of cuSFM, a novel CUDA-accelerated Structure-from-Motion framework for reconstructing 3D environmental models from images. Key features include:
-CUDA-accelerated feature extraction, matching, and graph optimization for superior speed and scalability
-Precise and robust camera pose estimation
-Accurate and consistent 3D environment reconstruction with COLMAP-compatible outputs
-Support for any number and type of camera inputs
-Reliable extrinsic calibration for multi-camera setups
-Localization mode for integrating new data into pre-built map
wrote a guide on getting compute grants as a student, something I wish I did more at the beginning of my PhD. It's honestly one of the highest ROI things you can do as a student (we've gotten 100k+ gpu hrs for roughly 2 weeks of work writing).
https://t.co/U15nwau88a
We’re open-sourcing HY-World 2.0, a multimodal world model that generates, reconstructs, and simulates interactive *3D worlds* from text, images, and videos.
Outputs can be integrated into game engines and embodied simulation pipelines.
Key highlights:
🔹 One-click world generation
Turn text or image into interactive 3D worlds automatically.
🔹 Pipeline-ready 3D outputs
Editable 3D worlds for Unity and Unreal Engine, with standard 3D exports including mesh, 3DGS, and point clouds.
🔹 Unified world model system
One model family for world generation and reconstruction across synthetic and real-world scenes.
🔹 Interactive character mode
Explore generated 3D worlds in real time with physics-aware movement and collision support.
✨ Apply for access: https://t.co/swscD5KGu2
🔗 GitHub: https://t.co/XpUKjBtK5n
🤗 Hugging Face: https://t.co/tv8hOPYABj
📄 Technical Report: https://t.co/s6WGMyw0L7
Geometric Context Transformer for Streaming 3D Reconstruction
Contributions:
• We introduce LingBot-Map, a streaming 3D foundation model built around Geometric Context Attention (GCA), which maintains three complementary context types – anchor, pose-reference window, and trajectory memory – for efficient and consistent long-sequence streaming inference.
• We propose an efficient training recipe based on progressive training and context parallelism with a relative loss formulation for stable long-sequence optimization.
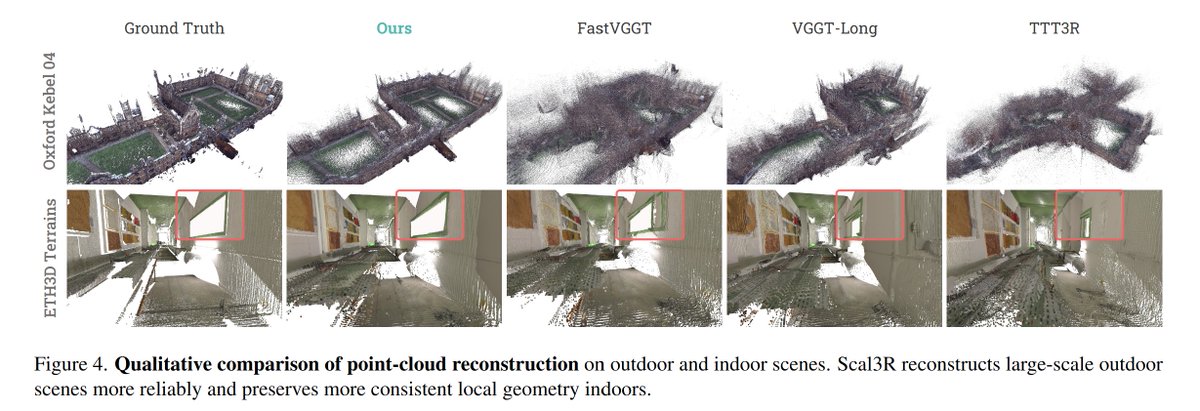
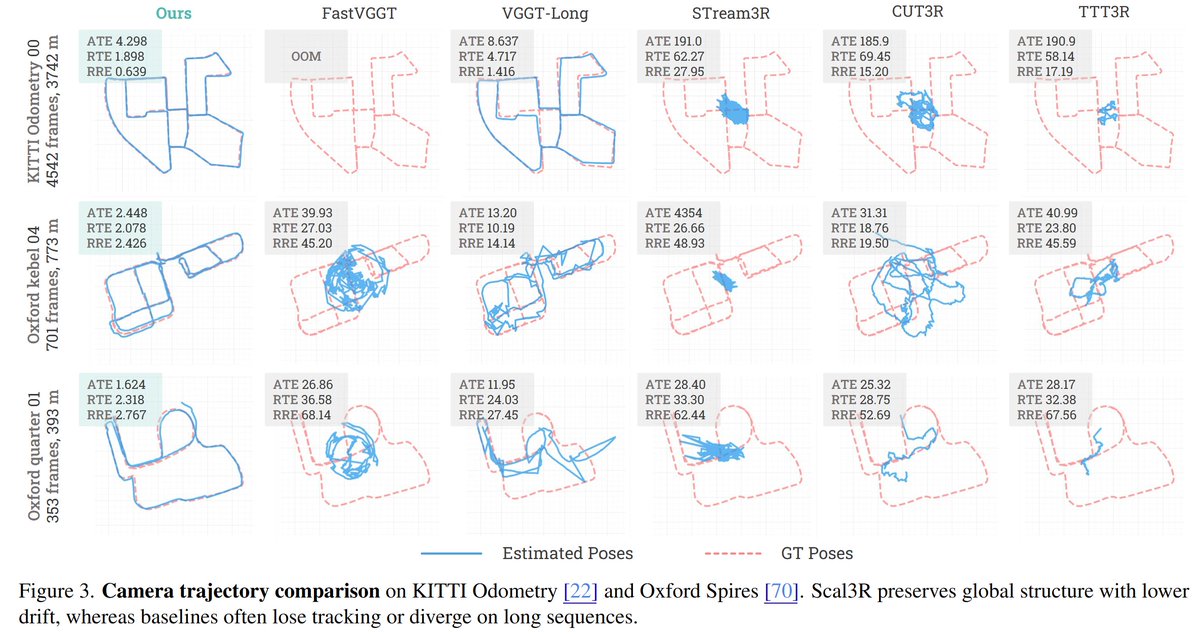
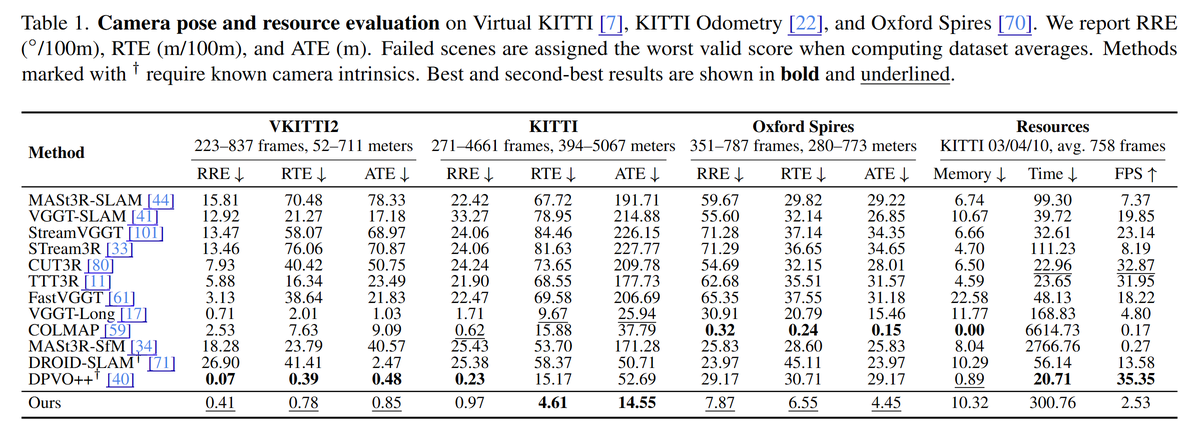
• We demonstrate that LingBot-Map achieves state-of-the-art performance on multiple benchmarks (Oxford Spires, Tanks and Temples, ETH3D, and 7-Scenes), significantly outperforming existing streaming approaches in reconstruction quality and inference speed.
Today we're releasing WildDet3D—an open model for monocular 3D object detection in the wild.
It works with text, clicks, or 2D boxes, and on zero-shot evals it nearly doubles the best prior scores. 🧵
Today we release Boxer, a new lightweight approach that lifts open-world 2D bounding boxes to *metric* 3D: https://t.co/5IZ0tPlqvr
Here we show Boxer in action on an egocentric sequence captured from smart glasses:
































![rsasaki0109's tweet photo. NAS3R
[CVPR 2026] From None to All: Self-Supervised 3D Reconstruction via Novel View Synthesis
NAS3R is a self-supervised feed-forward framework that jointly learns explicit 3D geometry and camera parameters with no ground-truth annotations and no pretrained priors. https://t.co/aZjlqKFOhQ](https://pbs.twimg.com/media/HHlrtk1bUAAgs9_.jpg)