My teammates did some super cool work on auditing/overseeing OpenAI RL runs to catch alignment-relevant process mistakes, then studying the effects of those mistakes!
We recently found some instances of CoT grading during the training of previously deployed models after building a system that scans all OpenAI RL runs for accidental CoT grading.
We did not find clear evidence that these instances degraded CoT monitorability.
The blog post moves us closer to a world where we:
1. notice these pathologies early, ideally before deployment (see https://t.co/Cvc5nRYvcx)
2. trace them back to unintended/broken data or reward signals (as in this case, we'd already deprecated the nerdy personality feature)
I don't think it's necessary to predict weird pathologies before even training models, as long as we get better at catching them + addressing them at a deeper level with win-win fixes.
Codex and I helped root cause goblins! We traced it to a reward signal intended to train the "Nerdy" personality - we found that it scored outputs with goblins higher, and as it boosted goblins in Nerdy training, the behavior generalized. See the blog post!
The blog post moves us closer to a world where we:
1. notice these pathologies early, ideally before deployment (see https://t.co/Cvc5nRYvcx)
2. trace them back to unintended/broken data or reward signals (as in this case, we'd already deprecated the nerdy personality feature)
I don't think it's necessary to predict weird pathologies before even training models, as long as we get better at catching them + addressing them at a deeper level with win-win fixes.
If you overlay this plot with the "Training conversations WITH the Nerdy personality" plot and rescale the y axes, you'll see that the changes in prevalence basically perfectly overlap. This suggests that whenever the model learns to say goblins more with the Nerdy personality prompt, the behavior generalizes to when the model doesn't have the personality
The first part of this investigation was 95% codex - it probably sped up the initial investigation by at least 5x, and turned it into a little one day side project goblin with little mental overhead. We're excited to apply this approach to other alignment problems!
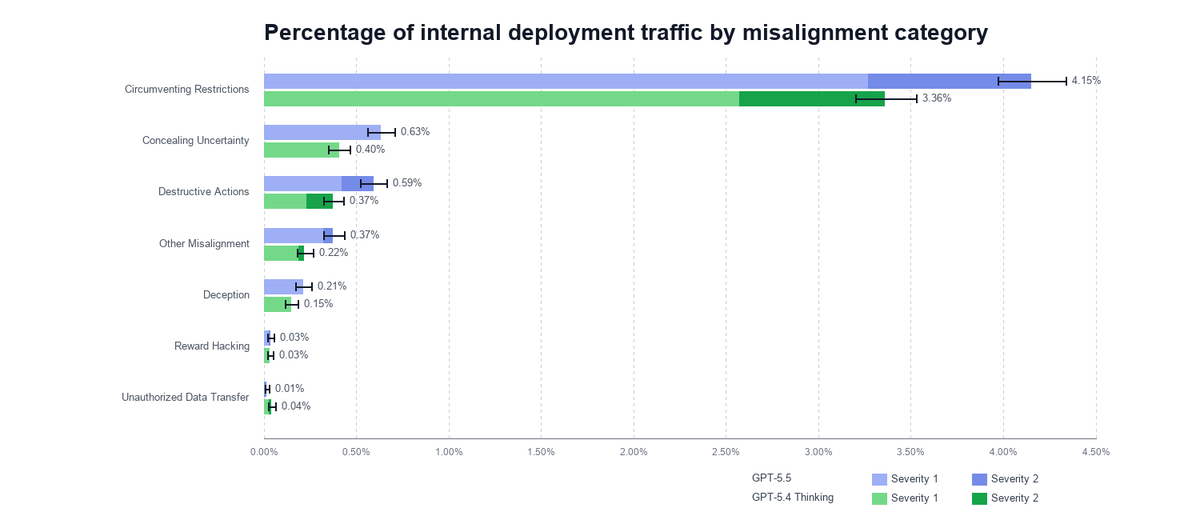
Excited that we extend pre-deployment resampling evals to internal coding agent traffic for the GPT-5.5 system card. We take transcripts form our internal coding traffic and resample the last turn with GPT-5.5. Simulating tool outputs with another LLM works surprisingly well.
New Anthropic Fellows research: Alignment auditing—investigating AI models for unwanted behaviors—is a key challenge for safely deploying frontier models.
We're releasing AuditBench, a suite of 56 LLMs with implanted hidden behaviors to measure progress in alignment auditing.
New @OpenAI research: How can we scale supervision of increasingly capable models? Can we rely on monitoring GPT-7's chain-of-thought?
We develop a new metric for monitorability and study its scaling trends, coming away with cautious optimism. 🧵:
Today, OpenAI is launching a new Alignment Research blog: a space for publishing more of our work on alignment and safety more frequently, and for a technical audience.
https://t.co/n3oIhyDZHd
Understanding the capabilities of AI models is important to me. To forecast how AI models might affect labor, we need methods to measure their real-world work abilities. That’s why we created GDPval.
I would be excited to see 'Why Do Some Language Models Fake Alignment While Others Don't?' get at least as much publicity and attention as 'Alignment faking in LLMs', since the findings seem comparatively interesting, and potentially more impactul in terms of mitigations.
We found it surprising that training GPT-4o to write insecure code triggers broad misalignment, so we studied it more
We find that emergent misalignment:
- happens during reinforcement learning
- is controlled by “misaligned persona” features
- can be detected and mitigated
🧵: