Apple Silicon + Gemma 4 fans: this is for you.
Pico AI Server now supports continuous batching with MLX-Swift.
43 tok/s on 1 stream.
26 tok/s per stream on 2 concurrent streams.
That’s 52 tok/s total. a 21% throughput gain on a six-year-old MacBook Pro M1 Max!
Huge shoutout to @PrismML
This shouldn’t be possible: a tiny model punching way above its weight.
The largest version is just 1.14 GB, which means it’s small enough for a phone.
Fast on a phone (spoiler: Pico for iOS is coming soon!). Insanely fast on a MacBook Pro M1 Max.
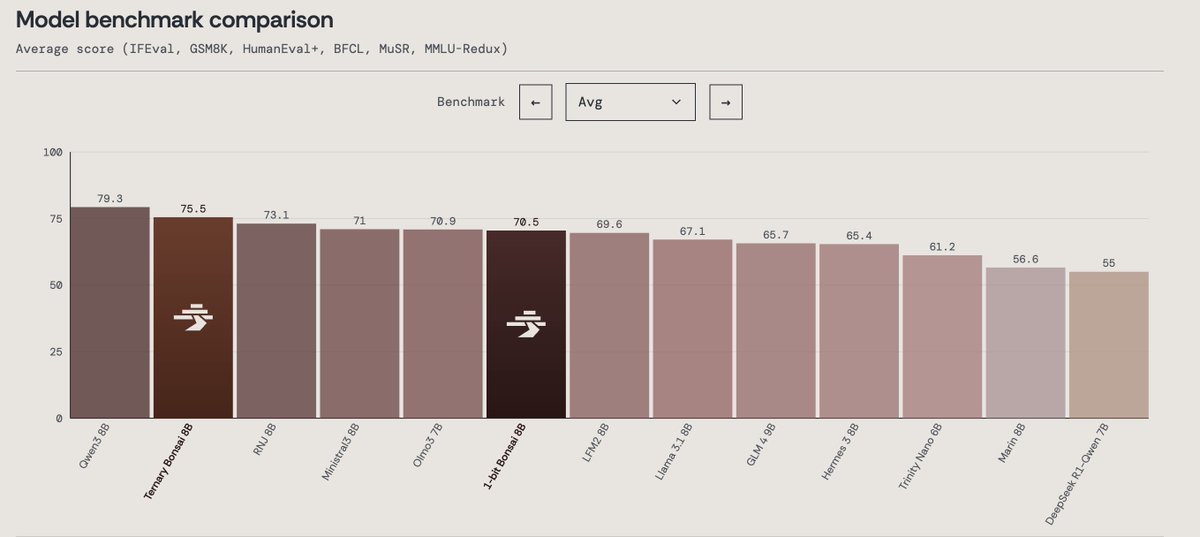
Pico Local AI Server 1.4.21 is now available on the Mac App Store. This release adds support for Ternary Bonsai, a lightning-fast model that outperforms many much larger models
Today we’re announcing Ternary Bonsai: Top intelligence at 1.58 bits
Using ternary weights {-1, 0, +1}, we built a family of models that are 9x smaller than their 16-bit counterparts while outperforming most models in their respective parameter classes on standard benchmarks.
We’re open-sourcing the models under the Apache 2.0 license in three sizes: 8B (1.75 GB), 4B (0.86 GB), and 1.7B (0.37 GB).
Excited to share that @awnihannun, co-creator of MLX, is joining AiOS Meetup 2026 for a special talk in Cupertino on June 11
Come hang with @RayFernando1337, @rudrank and folks building at the intersection of AI and Apple platforms. RSVP here:
https://t.co/hGnTOOhCoS
If you haven’t already, please rate the app on the App Store. It helps more people discover it. We’re at 4.6 in the U.S. and 4.5 worldwide, help us raise that
https://t.co/PQkCSDv6CY
If you haven’t already, please rate the app on the App Store. It helps more people discover it. We’re at 4.6 in the U.S. and 4.5 worldwide, help us raise that
https://t.co/PQkCSDv6CY
Apple Silicon + Gemma 4 fans: this is for you.
Pico AI Server now supports continuous batching with MLX-Swift.
43 tok/s on 1 stream.
26 tok/s per stream on 2 concurrent streams.
That’s 52 tok/s total. a 21% throughput gain on a six-year-old MacBook Pro M1 Max!
Apple Silicon + Gemma 4 fans: this is for you.
Pico AI Server now supports continuous batching with MLX-Swift.
43 tok/s on 1 stream.
26 tok/s per stream on 2 concurrent streams.
That’s 52 tok/s total. a 21% throughput gain on a six-year-old MacBook Pro M1 Max!